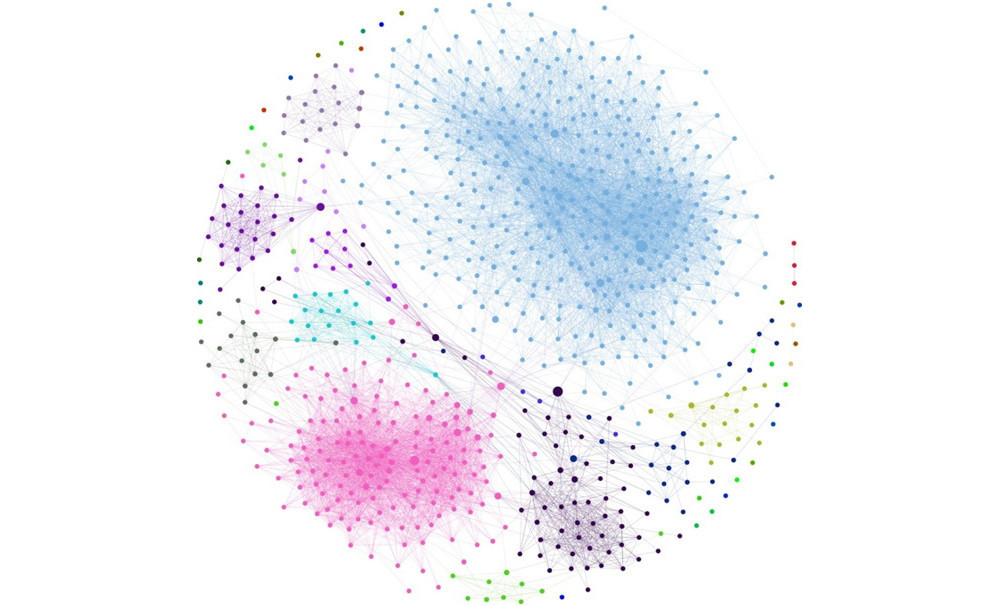
Привет, Хабр! Меня зовут Иван Антипов, я занимаюсь ML в команде матчинга Ozon. Наша команда разрабатывает алгоритмы поиска одинаковых товаров на сайте. Это позволяет покупателям находить более выгодные предложения, экономя время и деньги.
В этой статье мы обсудим кластеризацию на графах, задачу выделения сообществ, распад карате-клуба, self-supervised и unsupervised задачи — и как всё это связано с матчингом.