Компания Microsoft приняла решение поддержать пользователей, которые хотят делать кластеры Hadoop на Windows Server и Windows Azure. В рамках стратегического сотрудничества с Hortonworks будет разработан стек для Hadoop. Microsoft обещает публиковать код под открытой лицензией, делая коммиты в проект Apache по окончании разработки.
Вдобавок, Microsoft создаст «простые версии, которые можно скачать, инсталлировать и настроить» различных технологий, связанных с Hadoop, в том числе HDFS, Hive и Pig. Это должно стимулировать использование Hadoop корпоративными заказчиками.
Представьте себе фреймворк общего назначения для распределенного исполнения приложений со следующими статистическими показателями*:
* Статистические данные за 2011 год.
А теперь представьте, что это не Hadoop.
О том, что это за фреймворк, о идеях и концепциях, заложенных в его основу и о том, почему этот фреймворк даже более инновационный (субъективно), чем Hadoop, речь пойдет ниже.
Предметом внимания вчерашнего поста на Хабре стал фреймворк распределенных вычислений от Microsoft Research — Dryad.
В основе фреймворка лежит представление задания, как направленного ациклического графа, где вершины графа представляют собой программы, а ребра — каналы, по которым данные передаются. Также обзорно была рассмотрена экосистема фреймворка Dryad и сделан подробный обзор архитектуры одного из центральных компонентов экосистемы фреймворка – среды исполнения распределенных приложений Dryad.
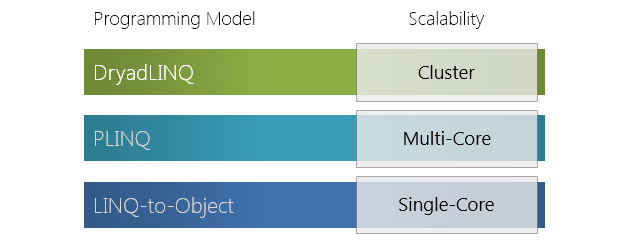
В этой статье обсудим компонент верхнего уровня программного стэка фреймворка Dryad – язык запросов к распределенному хранилищу DryadLINQ.
UPD: сменил заголовок статьи, т.к. прошлый заголовок я написал, пока был лунатиком (шутка, разумеется).
На прошлой неделе на Хабре появилось 2 поста о фреймворке распределенных вычислений от Microsoft Research – Dryad. В частности, подробно были описаны концепции и архитектура ключевых компонентов Dryad – среды исполнения Dryad и языка запросов DryadLINQ.
Логическим завершением цикла статей о Dryad видится сравнение фреймворка Dryad с другими, знакомыми разработчикам MPP-приложений, инструментами: реляционными СУБД (в т.ч. параллельными), GPU-вычислениями и платформой Hadoop.
 Компания Microsoft приняла решение поддержать пользователей, которые хотят делать кластеры Hadoop на Windows Server и Windows Azure. В рамках стратегического сотрудничества с Hortonworks будет разработан стек для Hadoop. Microsoft обещает публиковать код под открытой лицензией, делая коммиты в проект Apache по окончании разработки.
Компания Microsoft приняла решение поддержать пользователей, которые хотят делать кластеры Hadoop на Windows Server и Windows Azure. В рамках стратегического сотрудничества с Hortonworks будет разработан стек для Hadoop. Microsoft обещает публиковать код под открытой лицензией, делая коммиты в проект Apache по окончании разработки.