Приветствуем, уважаемые Хабравчане. Последнее время на Хабре стало мелькать название компании Teradata в тех или иных вопросах. И, увидев возможный интерес, мы решили рассказать немного о том, что же такое СУБД Teradata, от первого лица. Мы планируем подготовить небольшую серию статей о самых интересных, на наш взгляд, технических особенностях СУБД и работы с ней. Если у вас есть опыт работы с Teradata или в вашей компании используется наша платформа и у вас есть вопросы – подкидывайте их, и мы либо ответим на них в комментариях, либо подготовим соответствующую полноценную статью. А начнем с небольшого обзора. Для знакомства, так сказать.
Настройка распределённого выполнения параллельных программ в кластере
Medium
9 min
Tutorial

В предыдущей публикации Фортран: пишем параллельные программы для суперкомпьютера мы рассмотрели общий подход к программированию в массивно-паралллельной архитектуре (MPP) с использованием языка Фортран-2018 и дали пример запуска массивно-параллельной программы на одной машине с многоядерным процессором. В настоящей статье мы рассмотрим запуск массивно-параллельных программ на кластере высокой производительности (HPC) или кластере высокой готовности (HA). Код в данной статье пишется на языке Фортран-2018 с использованием комассивов (coarrays) и преобразуется компилятором Фортрана в вызовы фреймворка MPI.
Vertica Eon в K8S — 3 года развития
Medium
5 min
Retrospective

Vertica - одна из первых широко используемых MPP баз на просторах айти ландшафта СНГ. Колоночное хранение, быстрые запросы на миллиардах строк, легендарные sort-merge джойны, которых нет больше ни у кого, позволяющие запускать свои грибницы. Но нынче на дворе 2024 год: как компания Vertica сменила уже 2 (или трех) владельцев, доступ к веб ресурсам с территории РФ ограничен, поддержка брошена, а вокруг нас процветают облака или как минимум кубернетисы во всех ипостасях.
И все же начиная с версии 10.1 компания представила интересную возможность для тех, кто уже крепко подсел на эту иглу - движок Eon. Описывая в двух словах, это та же самая по скорости база данных, но использующая общее хранилище - S3 (во всех своих ипостасях от вендорских AWS, GCS до онпрем вариантов) или HDFS. К тому же есть отличная завлекалочка - бесплатное использование кластера размером до 1 ТБ и до 3 нод вычисления. Статья является итогом тестирования технологии, и результаты тестирования какие-то не очень веселые.
Проект Dual ETL или как мы строили Disaster Recovery для Greenplum
6 min
В этой статье я хочу рассказать про ещё один этап развития DWH в Тинькофф Банке.
Ни для кого не секрет, что требования к наличию Disaster Recovery (далее DR) в современных бизнес информационных системах относятся к категории «must have». Так, чуть более года назад, команде, занимающейся развитием DWH в банке, была поставлена задача реализовать DR для DWH, на котором построены как offline, так и online процессы банка.

Ни для кого не секрет, что требования к наличию Disaster Recovery (далее DR) в современных бизнес информационных системах относятся к категории «must have». Так, чуть более года назад, команде, занимающейся развитием DWH в банке, была поставлена задача реализовать DR для DWH, на котором построены как offline, так и online процессы банка.
Apache Spark: что там под капотом?
5 min
Вступление
В последнее время проект Apache Spark привлекает к себе огромное внимание, про него написано большое количество маленьких практических статей, он стал частью Hadoop 2.0. Плюс он быстро оброс дополнительными фреймворками, такими, как Spark Streaming, SparkML, Spark SQL, GraphX, а кроме этих «официальных» фреймворков появилось море проектов — различные коннекторы, алгоритмы, библиотеки и так далее. Достаточно быстро и уверенно разобраться в этом зоопарке при отсутсвие серьезной документации, особенно учитывая факт того, что Spark содержит всякие базовые кусочки других проектов Беркли (например BlinkDB) — дело непростое. Поэтому решил написать эту статью, чтобы немножко облегчить жизнь занятым людям.
Greenplum DB
17 min
Продолжаем цикл статей о технологиях, использующихся в работе хранилища данных (Data Warehouse, DWH) нашего банка. В этой статье я постараюсь кратко и немного поверхностно рассказать о Greenplum — СУБД, основанной на postgreSQL, и являющейся ядром нашего DWH. В статье не будут приводиться логи установки, конфиги и прочее — и без этого заметка получилась достаточно объёмной. Вместо этого я расскажу про общую архитектуру СУБД, способы хранения и заливки данных, бекапы, а также перечислю несколько проблем, с которыми мы столкнулись в ходе эксплуатации.

Немного о наших инсталляциях:
За тем, как оно работает, прошу под кат!
Немного о наших инсталляциях:
- проект живёт у нас чуть больше двух лет;
- 4 контура от 10 до 26 машин;
- размер БД около 30 Тб;
- в БД около 10000 таблиц;
- до 700 queries per second.
За тем, как оно работает, прошу под кат!
Exasol: опыт использования в Badoo
10 min
 Exasol — это современная высокопроизводительная проприетарная СУБД для аналитики. Ее прямые конкуренты: HP Vertica, Teradata, Redshift, BigQuery. Они широко освещены в Рунете и на Хабре, в то время как про Exasol на русском языке нет почти ни слова. Нам бы хотелось исправить эту ситуацию и поделиться опытом практического использования СУБД в компании Badoo.
Exasol — это современная высокопроизводительная проприетарная СУБД для аналитики. Ее прямые конкуренты: HP Vertica, Teradata, Redshift, BigQuery. Они широко освещены в Рунете и на Хабре, в то время как про Exasol на русском языке нет почти ни слова. Нам бы хотелось исправить эту ситуацию и поделиться опытом практического использования СУБД в компании Badoo.Exasol базируется на трех основных концепциях:
1. Массивно-параллельная архитектура (англ. massive parallel processing, MPP)
SQL-запросы выполняются параллельно на всех нодах, максимально используя все доступные ресурсы: ядра процессоров, память, диски, сеть. Понятие «мастер ноды» отсутствует — все серверы в системе равнозначны.
Отдельные стадии выполнения одного запроса также могут идти параллельно. При этом частично рассчитанные результаты передаются в следующую стадию, не дожидаясь окончания предыдущей.
2. Колоночное хранение (англ. columnar store)
Exasol хранит данные в колоночной форме, а не в форме отдельных рядов, как в классических СУБД. Каждая колонка хранится отдельно, разделяется на большие блоки, сортирируется, сжимается и равномерно распределяется по всем нодам.
Greenplum 5: первые шаги в Open Source
7 min
 Вот уже два года как одна из лучших распределённых аналитических СУБД enterprise-уровня вышла в open source. Что изменилось за это время? Что дало открытие исходников проекту? Как дальше будет развиваться Greenplum?
Вот уже два года как одна из лучших распределённых аналитических СУБД enterprise-уровня вышла в open source. Что изменилось за это время? Что дало открытие исходников проекту? Как дальше будет развиваться Greenplum?Под катом я расскажу о том, что нового появилось в первом мажорном open source релизе СУБД, как развивается проект в текущих минорных версиях и каких нововведений стоит ждать в будущем.
Сказ о том, как SQL время экономит
5 min
Translation
Существует компания, предоставляющая платформу для работы с большими данными. Эта платформа позволяет хранить генетические данные и эффективно управлять ими. Для полноценной работы платформы требуется возможность обрабатывать динамические запросы в среде выполнения не более чем за две секунды. Но как преодолеть этот барьер? Для трансформации существующей системы было решено использовать хранилище данных SQL. Заглядывайте под кат за подробностями!

Планируем проект внедрения и доработки информационной системы в MS Project — быстро и красиво
15 min
В последнее время мне приходится много работать как с менеджерами проектов так и с заказчиками, и я все больше убеждаюсь, что основой хорошего проекта внедрения и доработки информационной системы служит план проекта, разработанный в MS Project. Его можно показать заказчику, для того что бы наглядно продемонстрировать сроки и скоуп проекта, его можно включить в договор в качестве графика работ, его можно использовать для планирования ресурсов на проекте, с помощью него можно аргументировать те или иные сроки проекта, а так же можно считать внутреннюю и внешнюю стоимость, оценивая ресурсы на специальном представлении.
Релиз Apache Ignite 2.4 — Distributed Database and Caching Platform
5 min
12 марта 2018 г., спустя 4 месяца после прошлой версии, вышел Apache Ignite 2.4. Этот релиз примечателен целым рядом нововведений: поддержка Java 9, множественные оптимизации и улучшения SQL, поддержка платформой нейронных сетей, новый подход к построению топологии при работе с диском и многое другое.
Apache Ignite Database and Caching Platform — это платформа для распределенного хранения данных (оптимизированная под активное использование RAM), а также для распределенных вычислений в близком к реальному времени.
Ignite применяется там, где нужно очень быстро обрабатывать большие потоки данных, которые не по зубам централизованным системам.
Примеры использования: быстрый распределенный кеш; слой, агрегирующий данные из разрозненных сервисов (например, для Customer 360 View); основное горизонтально масштабируемое хранилище (NoSQL или SQL) оперативных данных; платформа для вычислений и т.д.
Далее рассмотрим основные новшества Ignite 2.4.
Apache Ignite Database and Caching Platform — это платформа для распределенного хранения данных (оптимизированная под активное использование RAM), а также для распределенных вычислений в близком к реальному времени.
Ignite применяется там, где нужно очень быстро обрабатывать большие потоки данных, которые не по зубам централизованным системам.
Примеры использования: быстрый распределенный кеш; слой, агрегирующий данные из разрозненных сервисов (например, для Customer 360 View); основное горизонтально масштабируемое хранилище (NoSQL или SQL) оперативных данных; платформа для вычислений и т.д.
Далее рассмотрим основные новшества Ignite 2.4.
Greenplum 6: обзор новых фич
6 min
 Вот уже 16 лет как открытая массивно-параллельная СУБД Greenplum помогает самым разным предприятиям принимать решения на основе анализа данных.
Вот уже 16 лет как открытая массивно-параллельная СУБД Greenplum помогает самым разным предприятиям принимать решения на основе анализа данных.За это время Greenplum проник в различные сферы бизнеса, в числе которых: ритейл, финтех, телеком, промышленность, e-commerce. Горизонтальное масштабирование до сотен узлов, отказоустойчивость, открытый исходный код, полная совместимость с PostgreSQL, транзакционность и ANSI SQL — трудно представить более удачное сочетание свойств для аналитической СУБД. Начиная от громадных кластеров в мировых компаниях-гигантах, как, например, Morgan Stanley (200 узлов, 25 Пб данных) или Tinkoff (>70 узлов), и заканчивая маленькими двух-нодовыми инсталляциями в уютных стартапах — всё больше компаний выбирают Greenplum. Особенно приятно наблюдать этот тренд в России — за последние два года количество крупных отечественных компаний, использующих Greenplum, выросло втрое.
Осенью 2019 года вышел очередной мажорный релиз СУБД. В этой статье я коротко расскажу об основных новых возможностях GP 6.
Аналитический движок Amazon Redshift + преимущества Облака
9 min

Привет, Хабр!
На связи Артемий Козырь из команды Аналитики, и я продолжаю знакомить вас с Wheely. В этом выпуске:
- Основы гибких кластерных вычислений
- Колоночное хранение и компрессия данных
- Вместо индексов: ключи сегментации и сортировки
- Управление доступами, правами, ресурсами
- Интеграция с S3 или Даталейк на ровном месте
Перспективные архитектуры для современных инфраструктур данных
9 min
Translation

Как IT-индустрия мы исключительно хорошо умеем создавать большие и сложные программные системы. Но сейчас мы начинаем наблюдать рост массивных и сложных систем, построенных вокруг данных, для которых основная ценность системы для бизнеса заключается в анализе этих данных, а не непосредственно в программном обеспечении. Мы видим стремительные изменения, спровоцированные этой тенденцией, во всей индустрии, что включает появление новых специальностей, сдвиги в пользовательской финансовой активности и появление новых стартапов, предоставляющих инфраструктуру и инструменты для работы с данными.
Многие из самых быстрорастущих инфраструктурных стартапов сегодня создают продукты для управления данными. Эти системы позволяют принимать решения на основе данных (аналитические системы) и управлять продуктами на основе данных, в том числе с помощью машинного обучения (оперативные системы). Они варьируются от конвейеров, по которым передаются данные, до решений для их хранения, SQL-движков, которые анализируют данные, дашбордов для мониторинга, которые упрощают понимание данных — от библиотек машинного обучения и data science до автоматизированных конвейеров данных, каталогов данных и т.д.
И все же, несмотря на весь этот импульс и энергию, мы обнаружили, что все еще существует огромная неразбериха в отношении того, какие технологии являются ведущими в этой тенденции и как они используются на практике. За последние два года мы поговорили с сотнями основателей, лидеров в сфере корпоративных данных и других экспертов, в том числе опросили более 20 практикующих специалистов по их текущим стекам данных, в попытке систематизировать новые передовые практики и сформировать общий словарь по инфраструктуре данных. В этой статье мы расскажем о результатах этой работы и продемонстрируем вам технологи, продвигающие индустрию вперед.
Аналитические панели в реальном времени. В поисках (Apache) Doris
5 min

Можно было бы назвать эту статью "Yet another analytical database", если бы не тот факт, что Apache Doris построен на архитектуре MPP, которая изначально ориентирована на параллельные вычисления и использование распределенного хранения и обработки данных на кластерах. Изначально проект Baidu, инструмент позволяет подготавливать аналитические панели с обновлением в реальном времени, при этом источниками данных могут быть как потоки из внешних источников (логи событий, time series-данные), так и источники из Data Lake (например, Apache Iceberg или Hive). В этой статье мы рассмотрим основные моменты использования Apache Doris на простом примере хранения и простой обработки данных о погоде.
Архитектурный шаблон MVI в Kotlin Multiplatform, часть 2
10 min

Это вторая из трёх статей о применении архитектурного шаблона MVI в Kotlin Multiplatform. В первой статье мы вспомнили, что такое MVI, и применили его для написания общего для iOS и Android кода. Мы ввели простые абстракции, такие как Store и View, а также некоторые вспомогательные классы и использовали их для создания общего модуля.
Задача этого модуля — загружать ссылки на изображения из Сети и связывать бизнес-логику с пользовательским интерфейсом, представленным в виде Kotlin-интерфейса, который должен быть реализован нативно на каждой платформе. Именно этим мы и займёмся в этой статье.
Мы будем реализовывать специфичные для платформы части общего модуля и интегрировать их в iOS- и Android-приложения. Как и прежде, я предполагаю, что читатель уже имеет базовые знания о Kotlin Multiplatform, поэтому не буду рассказывать о конфигурациях проектов и других вещах, не связанных с MVI в Kotlin Multiplatform.
Обновлённый пример проекта доступен на нашем GitHub.
Архитектурный шаблон MVI в Kotlin Multiplatform, часть 1
9 min
Translation

Около года назад я заинтересовался новой технологией Kotlin Multiplatform. Она позволяет писать общий код и компилировать его под разные платформы, имея при этом доступ к их API. С тех пор я активно экспериментирую в этой области и продвигаю этот инструмент в нашей компании. Одним из результатов, например, является наша библиотека Reaktive — Reactive Extensions для Kotlin Multiplatform.
В приложениях Badoo и Bumble для разработки под Android мы используем архитектурный шаблон MVI (подробнее о нашей архитектуре читайте в статье Zsolt Kocsi: «Современная MVI-архитектура на базе Kotlin»). Работая над различными проектами, я стал большим поклонником этого подхода. Конечно, я не мог упустить возможность попробовать MVI и в Kotlin Multiplatform. Тем более случай был подходящий: нам нужно было написать примеры для библиотеки Reaktive. После этих моих экспериментов я был вдохновлён MVI ещё больше.
Я всегда обращаю внимание на то, как разработчики используют Kotlin Multiplatform и как они выстраивают архитектуру подобных проектов. По моим наблюдениям, среднестатистический разработчик Kotlin Multiplatform — это на самом деле Android-разработчик, который в своей работе использует шаблон MVVM просто потому, что так привык. Некоторые дополнительно применяют «чистую архитектуру». Однако, на мой взгляд, для Kotlin Multiplatform лучше всего подходит именно MVI, а «чистая архитектура» является ненужным усложнением.
Поэтому я решил написать эту серию из трёх статей на следующие темы:
- Краткое описание шаблона MVI, постановка задачи и создание общего модуля с использованием Kotlin Multiplatform.
- Интеграция общего модуля в iOS- и Android-приложения.
- Модульное и интеграционное тестирование.
Ниже — первая статья серии. Она будет интересна всем, кто уже использует или только планирует использовать Kotlin Multiplatform.
Массивно-параллельная база данных Greenplum — короткий ликбез
5 min
Для Hadoop и Greenplum есть возможность получить готовый SaaS. И если Хадуп — известная штука, то Greenplum (он лежит в основе продукта АrenadataDB, про который далее пойдёт речь) — интересная, но уже менее «на слуху».
Arenadata DB — это распределённая СУБД на базе опенсорсного Greenplum. Как и у других решений MPP (параллельной обработки данных), для массивно-параллельных систем архитектура облака далека от оптимальной. Это может снижать производительность аж до 30 % (обычно меньше). Но, тем не менее, эту проблему можно нивелировать (о чём речь пойдёт ниже). Кроме того, стоит покупать такую услугу из облака, часто это удобно и выгодно в сравнении с развёртыванием собственного кластера.
В гайдах явно указывается on-premise, но сейчас многие осознают масштаб удобства облака. Все понимают, что некая деградация производительности будет, но это настолько всё равно супер по удобству и скорости, что уже есть проекты, где этим жертвуют на каких-то этапах вроде проверки гипотез.
Если у вас есть хранилище данных больше 1 ТБ и транзакционные системы — не ваш профиль по нагрузке, то ниже — рассказ, что можно сделать как вариант. Почему 1 ТБ? Начиная с этого объёма использование MPP эффективнее по соотношению производительность/стоимость, если сравнивать с классическими СУБД.
Архитектурный шаблон MVI в Kotlin Multiplatform. Часть 3: тестирование
9 min

Эта статья является заключительной в серии о применении архитектурного шаблона MVI в Kotlin Multiplatform. В предыдущих двух частях (часть 1 и часть 2) мы вспомнили, что такое MVI, создали общий модуль Kittens для загрузки изображений котиков и интегрировали его в iOS- и Android-приложения.
В этой части мы покроем модуль Kittens модульными и интеграционными тестами. Мы узнаем о текущих ограничениях тестирования в Kotlin Multiplatform, разберёмся, как их преодолеть и даже заставить работать в наших интересах.
Обновлённый пример проекта доступен на нашем GitHub.
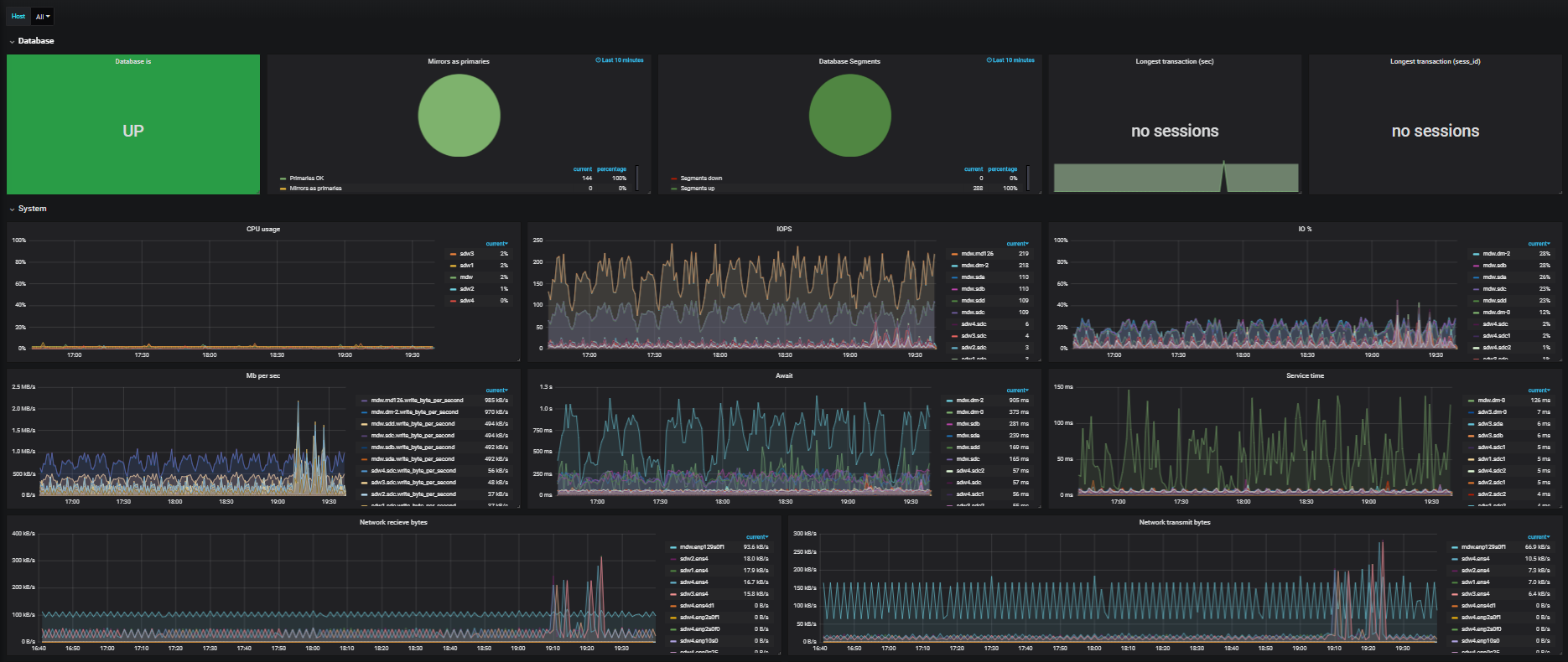
Три способа отследить запросы Greenplum, которые «отъедают» слишком много ресурсов
14 min
Tutorial

Привет, Хабр! Меня зовут Роман, я работаю разработчиком в компании Arenadata, где мы решаем много задач, связанных с Greenplum. Как-то мне представился случай разобраться с одним непростым, но вполне типичным для этой СУБД кейсом. Необходимо было выяснить, на обработку каких запросов уходит неадекватно много системных ресурсов. В этой статье мне бы хотелось поделиться своими наработками и рассказать о трёх проверенных мной способах мониторинга утилизации системных ресурсов, потребляемых запросами в Greenplum.