Я работаю в компании STM Labs, где мы строим большие высоконагруженные системы класса Big Data. Эта статья написана по мотивам моего выступления на конференции Saint Highload 2023. Хочу рассказать вам увлекательную историю про то, как мы искали лучшее решение по синхронизации аналитического и оперативного хранилищ в реальном времени. Нам важно было сделать это без потерь, потому что на кону стояли сотни и более терабайт данных.
Сразу обозначу, чего в этой статье не будет:
• Я не буду подробно говорить о типах СУБД и их различиях.
• Я не буду делать обзор аналитических СУБД. Тут каждый выбирает сам.
• Я не буду подробно останавливаться на архитектуре, отказоустойчивости и масштабировании СУБД MongoDB.
• Я не буду делать обзор отличий OLAP и OLTP.
• Я не буду делать обзор и сравнение реализаций CDC в различных СУБД.
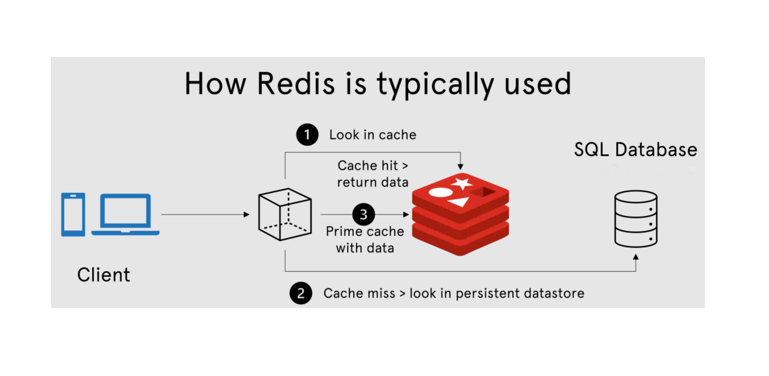

 Создатель опенсорсной системы управления базами данных
Создатель опенсорсной системы управления базами данных