В этой главе мы обсуждаем базы данных, реляционные и NoSQL, которые работают на одной машине. Именно этот режим работы будет являться тем кирпичиком, на котором строятся распределенные базы данных.
Перевод концепции модели данных ESRI внутреннего пространства зданий (BISDM)
29 min
Модель данных внутреннего пространства зданий (помещений) обеспечивает шаблоны классов пространственных объектов и таблиц, которые представляют информацию о здании. В то время как основное внимание уделяется планированию и управлению помещениями, также есть цель обеспечить основы для дополнительных данных, связанных со зданиями и сооружениями для поддержки разнообразных применений. Модель вобрала в себя наилучшие практики в области, которая быстро развивается по многим направлениям в различных организациях.
Как Microsoft спрятала целый сервер и как его найти
4 min
— Видишь SSAS-суслика?
— Нет…
— И я не вижу. А он есть!

(Кадр из к/ф «ДМБ»)
Поддержка относительно новой табличной (табулярной) модели данных, в противовес устоявшейся многомерной OLAP, встроена в целый ряд продуктов компании Microsoft. Начиная с SQL-сервера (SS) и заканчивая Excel. И если с SS всё понятно – в нём содержится отдельный сепаратный продукт SQL Server Analysis Services (SSAS). А как же решена поддержка языка DAX-запросов и прочей табулярной функциональности в Power BI, SharePoint или Excel? Поищем «суслика» на примере Power BI Desktop.
— Нет…
— И я не вижу. А он есть!
(Кадр из к/ф «ДМБ»)
Поддержка относительно новой табличной (табулярной) модели данных, в противовес устоявшейся многомерной OLAP, встроена в целый ряд продуктов компании Microsoft. Начиная с SQL-сервера (SS) и заканчивая Excel. И если с SS всё понятно – в нём содержится отдельный сепаратный продукт SQL Server Analysis Services (SSAS). А как же решена поддержка языка DAX-запросов и прочей табулярной функциональности в Power BI, SharePoint или Excel? Поищем «суслика» на примере Power BI Desktop.
SSAS 2012: от многомерной к табличной модели данных
10 min
Введение
Табличная Модель Данных как основа для решений в бизнес-аналитике была предложена корпорацией Майкрософт в компоненте по имени PowerPivot, скромном дополнении к Microsoft Office Excel. С тех пор дискуссии о значении этой модели не стихают и по сей день. Апологеты новой технологии убеждены в ее революционности, скептики считают, что это не более чем эволюционная подвижка. В SQL Server 2012 Analysis Services (SSAS 2012) Майкрософт представил теперь уже серверный вариант аналитической базы данных, основанной на принципах Табличной Модели. Естественно, это не может не добавить в диспуты свежую струю.
Как подготовить данные для SAP Process Mining by Celonis
22 min
На примере данных из системы управления ИТ-услугами (ITSM).
В предыдущей статье SAP Process Mining или как разобраться в своих бизнес-процессах мы говорили о Process Mining и о его применении в корпоративной среде. Сегодня мы хотим более подробно рассказать про модель данных и процесс ее подготовки. Мы рассмотрим компоненты, как они связаны между собой, какой формат данных запросить у владельцев данных и каким может быть подход к генерации таблицы событий для SAP Process Mining by Celonis.
В предыдущей статье SAP Process Mining или как разобраться в своих бизнес-процессах мы говорили о Process Mining и о его применении в корпоративной среде. Сегодня мы хотим более подробно рассказать про модель данных и процесс ее подготовки. Мы рассмотрим компоненты, как они связаны между собой, какой формат данных запросить у владельцев данных и каким может быть подход к генерации таблицы событий для SAP Process Mining by Celonis.
YANG — это имя для вождя
5 min
Tutorial

Когда я впервые увидел эти символы, то подумал, что это имя индейского вождя: буква Y напомнила венец из перьев желтокожего вождя из книжек о Диком Западе. И даже произнесение “YANG” вслух произвело такой эффект, что мой далеко не прыткий английский бульдог Бучо вскочил на четыре лапы.
Архитектура CMS. Модель данных. Часть 2
9 min
Продолжаем тему объектной модели данных. В этой части речь пойдет о модуле Data, являющимся, по сути, ORM системой. Для наглядности работы модуля Data c его помощью будет создано содержимое простого сайта. Предыдущая статья: Архитектура CMS. Модель данных. Часть 1.
Модуль Data состоит из классов Data, Object, Multy, Query и набора классов Cond*. Сам модуль – это статический класс Data, остальные классы используются для представления структур данных, с которыми он работает. Для представления сущностей в программном коде используется класс Object. Не важно, какого типа сущность – класс данных, объект данных или связь между ними – для всех Object. Класс Multy используется для ассоциации с набором сущностей, в частности, для представления множественных свойств. Классы Query и Cond* необходимы для осуществления поиска по объектной модели (в базе данных) с учетом гибких условий.
Модуль Data состоит из классов Data, Object, Multy, Query и набора классов Cond*. Сам модуль – это статический класс Data, остальные классы используются для представления структур данных, с которыми он работает. Для представления сущностей в программном коде используется класс Object. Не важно, какого типа сущность – класс данных, объект данных или связь между ними – для всех Object. Класс Multy используется для ассоциации с набором сущностей, в частности, для представления множественных свойств. Классы Query и Cond* необходимы для осуществления поиска по объектной модели (в базе данных) с учетом гибких условий.
RDF Это просто
5 min

В этой заметке я попытаюсь объяснить на пальцах ключевые моменты и обосновать преимущества модели RDF.
Более 10 лет концепция Semantic Web, частью который является RDF развивалась, была предметом споров и обсуждений, и сегодня ее все активнее поддерживает сообщество в своих приложениях.
Однако для многих все еще совсем не понятно:
- Зачем все это?
- Как с этим работать?
- Что это даст именно мне?
Мета-данные. На пути к идеалам управления моделями данных
6 min
О чём этот пост
- Это пост-обзор вариантов управления моделями данных, известных автору, на основе опыта, слухов, и чтения инструкций
- Также этот пост — попытка классификации существующих вариантов управления моделями данных
- Напоследок приводится идея и начальные штрихи в реализации системы управления моделями данных, которая не должна содержать недостатков предыдущих
Определения и ограничения
Предполагается, что читатель является (или когда-нибудь станет) разработчиком Enterprise Application, которому часто нужно писать быстро и качественно, но не боящегося лезть в дебри JPA/JTA/RMI чтобы «подкрутить напильником» особо тонкие места.
Данные — то, что хранится в базе данных приложения. Данные о клиентах, пользователях, заказах и т.п.
Метаданные — описание структуры данных. Описание того, какие типы объектов хранятся в базе данных, какие у них есть поля (аттрибуты, элементы), описание зависимостей между объектами. В общем случает типы могут наследовать атрибуты родительского типа, а один атрибут в общем случае может присутствовать у двух и более типов, несвязанных отношением наследования.
Java-ассемблер, мета-программирование и JPA
20 min
В этом топике хочу поделиться первым опытом по написанию системы генерации кода «на лету». В коде реализуются некоторые идеи, описанные в предыдущем топике, а сам код используется в одной старой, но работающей системе управления сайтами.
Краткая постановка задачи:
Для выполнения данной задачи использовалось:
Краткая постановка задачи:
- Есть набор виртуальных «классов» в понятии бизнес-пользователя. Например, «сайт», «папка», «новость», и т.д. Каждый из таких классов имеет набор полей (аттрибутов).
- Пока что у нас нет наследования классов, а поля ограничены примитивными String/Integer/Long/Enum/Boolean, даже без multiple, но с возможными заданными значениями по умолчанию
- Каждый класс записывается в отдельную таблицу, например, objects_sites, objects_news, objects_folder, etc. Таблица всегда содержит ID объекта, а также колонки для полей.
- Нужно сделать так, чтобы загрузка этих объектов работала через JPA (Hibernate), с использованием необходимого кэширования/транзакций/Lazy-loading'а и других вкусностей, которые нам даёт JPA.
Для выполнения данной задачи использовалось:
- В качестве баз данных — MySQL 5.0, InnoDB, три схемы базы данных (разные типы могут лежать в разных схемах, чтобы отделить системные типы от пользовательских)
- Sun JDK 6.0
- Tomcat 6 + JOTM 2.1.9 + Hibernate 3.5.0-Final (patched)
- Для создания классов использовалась связка CGLib 2.2 (входящая в Hibernate) и ASM 3.2 (в Hibernate входит 3.1)
Прототипная модель данных
4 min
В прототипной модели данных объекты создаются на основе других объектов. В этом случае у объекта имеется прототип, его ещё можно назвать эталоном или наследуемым объектом. В такой модели данных отсутствуют типы и классы. Объекты можно различать по тому, кого прототипируют, но эта задача второстепенная. Прототипирование, в первую очередь, применяется для повторного использования существующих структур из объектов.

Реализация ссылочной модели в языке программирования Аргентум
Medium
18 min
Review
Реализация ссылочной модели в языке программирования Аргентум:
Практический пример, сравнение с популярными языками, семантика операций, особенности многопоточности, внутреннее устройство.
Аналитика микросервисов. Практический опыт аналитика в enterprise
22 min
Вместо введения
Для кого я решил написать? Данная статья, написана для моих коллег аналитиков или для тех, кто желал бы им стать. Если вы теперь захотели стать аналитиком, то подумайте хорошенько.
Микросервисы. С хайпом вокруг них, лучше быть разработчиком, архитектором, тестировщиком, проджект-менеджером, дизайнером. Хорошо быть кем угодно в микросервсиах, но только не аналитиком. Аналитик ведь всегда во всем виноват. Ни разу не слышал, чтобы в “факапе” и срыве сроков обвинили архитектора, ну или там разработку. Нет, господа, вина всегда лежала и будет лежать на плохой документации и нечетко поставленных задачах. Вот вся команда собралась и тычет в тебя пальцами. Дескать, это все он! Опытный архитектор спроектировал, хороший разработчик сделал, внимательный тестировщик протестировал, мотивированный проджект-менеджер обеспечил… а невнимательный аналитик все завалил. А меж тем, материалов по аналитике и как её вести на русском языке очень мало. И как “анализировать” эти самые микросервисы не совсем понятно. Более того, никто вам не скажет, чем “системный аналитик” теперь отличается от “солюшн архитектора”. Вот во всем этом я и захотел разобраться и поделиться. Поэтому, если вы не аналитик - не читайте. Вам не будет интересно. Ведь, нет в вас экзистенциального кризиса и вопросов “Кто я? и зачем я им нужен на проекте”.
Процесс моделирования данных при разработке приложений
10 min
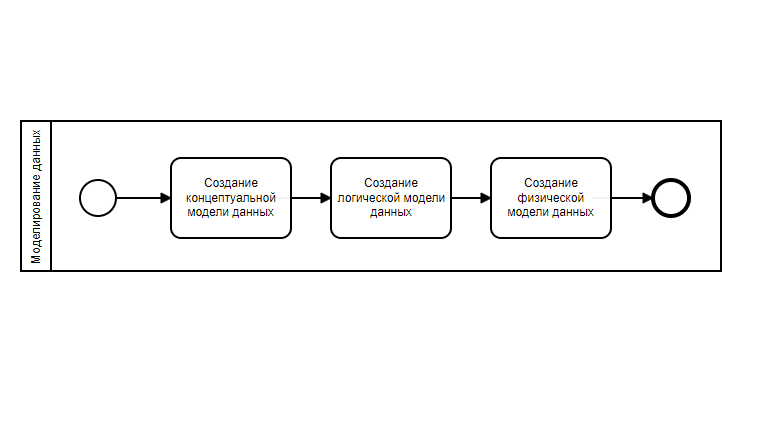
Привет!
Меня зовут Коля, и я системный аналитик.
В большинстве источников моделирование данных (в контексте создания приложений) рассматривается как последовательное создание трёх моделей данных - концептуальной, логической и физический. Такого порядка придерживаются, например, DMBOK2 и BABOK, а также многочисленные статьи в сети Интернет:
Рискну предложить несколько дополнений и уточнений к этому процессу - как на основании собственного опыта, так и обобщения опыта коллег, с которыми обсуждал этот вопрос.
Пример описания многослойной архитектуры, основанной на использовании наборов подслоёв и иерархии моделей данных
Medium
9 min
В статье рассмотрен подход, основанный на разбиении структуры приложения на слои и подслои, который позволяет с единой позиции подойти к описанию основных используемых типов архитектуры приложений.

Хранилище данных пугает бизнес: проблемы DWH для бизнеса
Easy
8 min
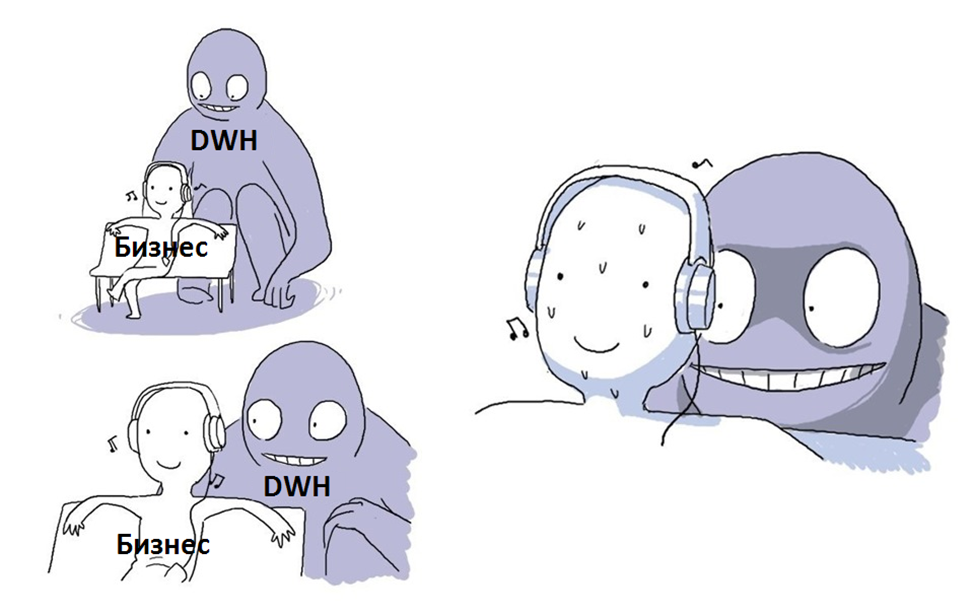
За созданием хранилища данных и особенно его поддержкой кроются жуткие монстры, пугающие в первую очередь бизнес, а уже потом IT-отдел.
В этой статье рассмотрим наиболее частые проблемы, касающиеся хранилищ данных, с которыми сталкивается менеджмент компании, а также способы их решения.
Рекомендации по моделированию данных
Easy
6 min
Tutorial

Всем привет! Меня зовут Елизавета Акманова, и я рада приветствовать вас в моей новой статье. Если вы помните, моя первая публикация касалась пяти ключевых трендов в бизнес-анализе. Сегодня я приглашаю вас отправиться в увлекательное путешествие под названием «Рекомендации по моделированию данных».
Отмечу, что в данной статье не будут рассмотрены технические аспекты, такие как типы баз данных, уровни нормализации, типы данных, и т.п. Эти вопросы не являются предметом обсуждения. Основное внимание будет уделено бизнес-целям создания модели данных. Я дам рекомендации по работе с моделями данных, основанные на моем личном опыте.
Первое, с чего хочется начать: что такое модель данных и база данных? Зачем их разделяют и в чем их принципиальное отличие?