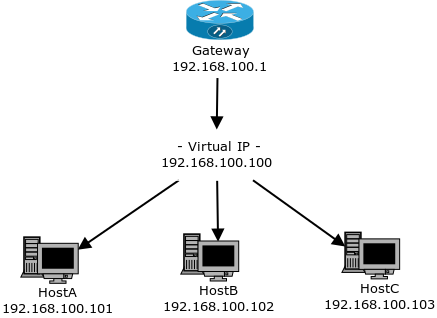
При резервировании некоторых типов ресурсов, очень важно что бы одновременно ресурсом пользовалось не более одного клиента, как, например, с drbd: нельзя допускать что бы drbd была подмонтирована в RW режиме на двух системах. То же касается и дисковых систем, подключаемых к нескольким серверам.
За этим следит сам pacemaker, но могут возникнуть ситуации, когда pacemaker решит что ресурс нужно переносить, но команду на отключение на другом узле дать не сможет (например, потеря сетевой связности при использовании iscsi через отдельную сеть итд). Для борьбы с этим используется stonith (Shoot The Other Node In The Head). В pacemaker он настраивается как ресурс и способен решить многие проблемы.
За этим следит сам pacemaker, но могут возникнуть ситуации, когда pacemaker решит что ресурс нужно переносить, но команду на отключение на другом узле дать не сможет (например, потеря сетевой связности при использовании iscsi через отдельную сеть итд). Для борьбы с этим используется stonith (Shoot The Other Node In The Head). В pacemaker он настраивается как ресурс и способен решить многие проблемы.