EagleMQ – это новый высокопроизводительный менеджер очередей. Основные решаемые задачи это эффективное распределение сообщений между процессами, межпроцессорная коммуникация и уведомления реального времени.


dispatch(), примерно так:

На новом проекте, на котором я работаю в качестве PHP Tech Lead. Команда столкнулась с вопросом наведения порядков, один из которых - унификация:

Stack
Stack is a linear data structure. In stack, data access is limited. It follows the rule of insertion and deletion of data. Stack is a collection of only similar data types. Elements in the stack are arranged sequentially. It follows the LIFO principle which is the last-in and first-out rule.
Example
To understand this concept, let us take an example of arranging coins. If we start placing coins one after the other in such a way that the first coin will be placed first at the bottom and the next coin will come on above the first coin and so on. Now if we want to remove coins, then the topmost coin which is the third coin will be removed first. So in this way, the last coin will be removed first according to the LIFO principle.

 При звонках в колл-центр компаний часто приходится сталкиваться с большим временем ожидания на линии, многие из нас слушали надоедливую мелодию в течение десятков минут хотя бы раз в жизни. Самое интересное заключается в том, что это совершенно невыгодно компании в колл-центр которой вы звоните, особенно если вы звоните на номер 8-800. К счастью, уже давно придуман способ, позволяющий решить данную проблему — это callback или обратный вызов. Суть этого способа очень простая: позвонившему предлагают отключиться от колл-центра при этом его номер так и остается в очереди на обслуживание и как только его очередь подойдет, то ему автоматически наберут и соединят с оператором, на которого распределился его звонок. Таким образом убиваем сразу несколько зайцев: не занимаются линии колл-центра, не тратятся дорогостоящие минуты 8-800, а клиенты не испытывают лишнего раздражения в ожидании ответа. Вендоры колл-центрового ПО хотят за такую функцию весьма приличных денег, а мы под катом расскажем как данный функционал достаточно просто и быстро реализуется с помощью платформы VoxImplant.
При звонках в колл-центр компаний часто приходится сталкиваться с большим временем ожидания на линии, многие из нас слушали надоедливую мелодию в течение десятков минут хотя бы раз в жизни. Самое интересное заключается в том, что это совершенно невыгодно компании в колл-центр которой вы звоните, особенно если вы звоните на номер 8-800. К счастью, уже давно придуман способ, позволяющий решить данную проблему — это callback или обратный вызов. Суть этого способа очень простая: позвонившему предлагают отключиться от колл-центра при этом его номер так и остается в очереди на обслуживание и как только его очередь подойдет, то ему автоматически наберут и соединят с оператором, на которого распределился его звонок. Таким образом убиваем сразу несколько зайцев: не занимаются линии колл-центра, не тратятся дорогостоящие минуты 8-800, а клиенты не испытывают лишнего раздражения в ожидании ответа. Вендоры колл-центрового ПО хотят за такую функцию весьма приличных денег, а мы под катом расскажем как данный функционал достаточно просто и быстро реализуется с помощью платформы VoxImplant.


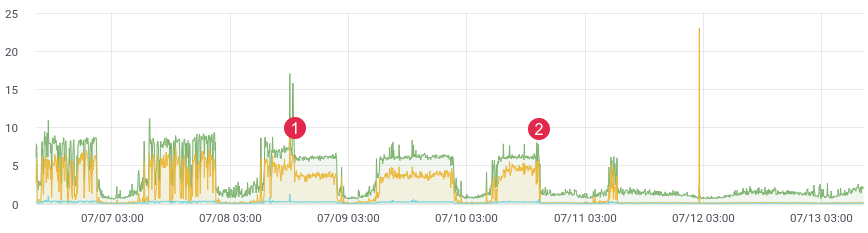
 Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.
Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.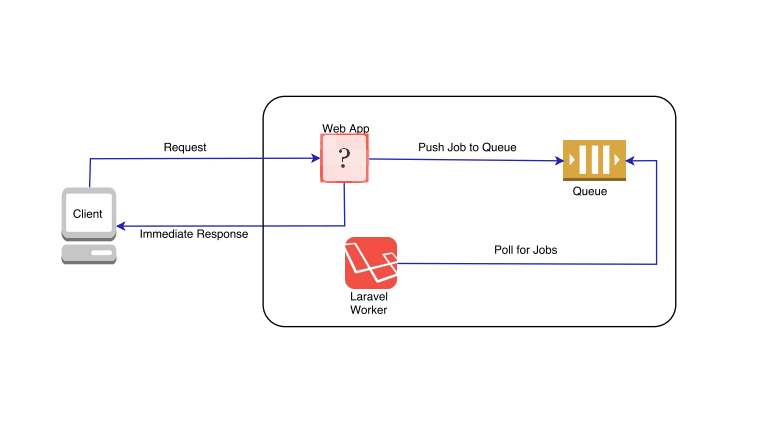
При работе над проектом (будь-то хайповые микросервисы или монолит) довольно часто возникает ситуация, когда необходимо, чтобы один сервис поставил задачу для другого сервиса. Задача довольно тривиальная, если на обеих сторонах используется один и тот же фреймворк. Но все становится намного интересней, когда на стороне подписчика допустим Laravel со своим дефолтным форматом, а на стороне издателя что‑то модное на Go.
Очереди часто являются фундаментальными компонентами в паттернах проектирования программного обеспечения.
Но что, если каждую секунду поступают миллионы сообщений, а многопроцессорные потребители должны иметь возможность читать полный журнал всех сообщений?
Java может хранить ограниченное количество информации, пока куча не станет ограничивающим фактором, в результате чего сборка мусора будет иметь большие последствия, что потенциально может помешать нам выполнить целевые SLA (соглашения об уровне обслуживания) или даже остановить JVM на секунды или даже минуты.
В этой статье рассказывается о том, как создавать огромные персистентные очереди, сохраняя при этом предсказуемую и стабильную низкую задержку с помощью Chronicle Queue с открытым исходным кодом.


В 2013 я пришел в Mail.ru Group, и я решал задачу, в которой мне нужна была очередь. Есть много разных инструментов для построения очередей, но я решил для начала узнать, что уже имеется в компании. Услышал, что есть такой продукт — Tarantool. Узнал, как он устроен, и мне показалось, что в него отлично может быть встроен брокер очередей.
Я пошёл к главному по Tarantool — Косте Осипову — и постарался объяснить, что я хочу получить. Предполагалось, что код очереди будет написан на C, как и остальной код Tarantool, но… На следующий день Костя дал мне скрипт на 250 строк, который реализовывал почти всё, что я хотел.
С того момента я влюбился в Tarantool. Оказалось, что можно написать совсем немного кода на очень простом скриптовом языке и получить совершенно новую для этой СУБД функциональность.
Прошло много времени, Tarantool развивался, в том числе и под влиянием наших запросов, но основные идеи и подходы сохранились. Я расскажу, как реализовать собственную очередь на современном Tarantool, например версии 2.2.

Пару лет назад в одном из проектов мы столкнулись с необходимостью откладывать выполнение некоего действия на определенный промежуток времени. Например, узнать статус платежа через три часа или повторно отправить уведомление через 45 минут. Однако на тот момент мы не нашли подходящих библиотек, способных "откладывать" и не требующих дополнительного времени на настройку и эксплуатацию. Мы проанализировали возможные варианты и написали собственную маленькую библиотеку delayed queue на Java с использованием Redis в роли хранилища. В этой статье я расскажу про возможности библиотеки, ее альтернативы и те "грабли", на которые мы наткнулись в процессе.

В работе над проектом Образовательной Платформы Сбера мы столкнулись с ситуацией, когда интенсивность влития изменений в центральную ветку репозитория git существенно превысила время прохождения Quality Gate (статический анализ, сборка, автотесты) внесённых изменений. В статье я расскажу, как нам удалось решить эту проблему, не утратив скорости разработки и добившись стопроцентной зелёной ветки master.