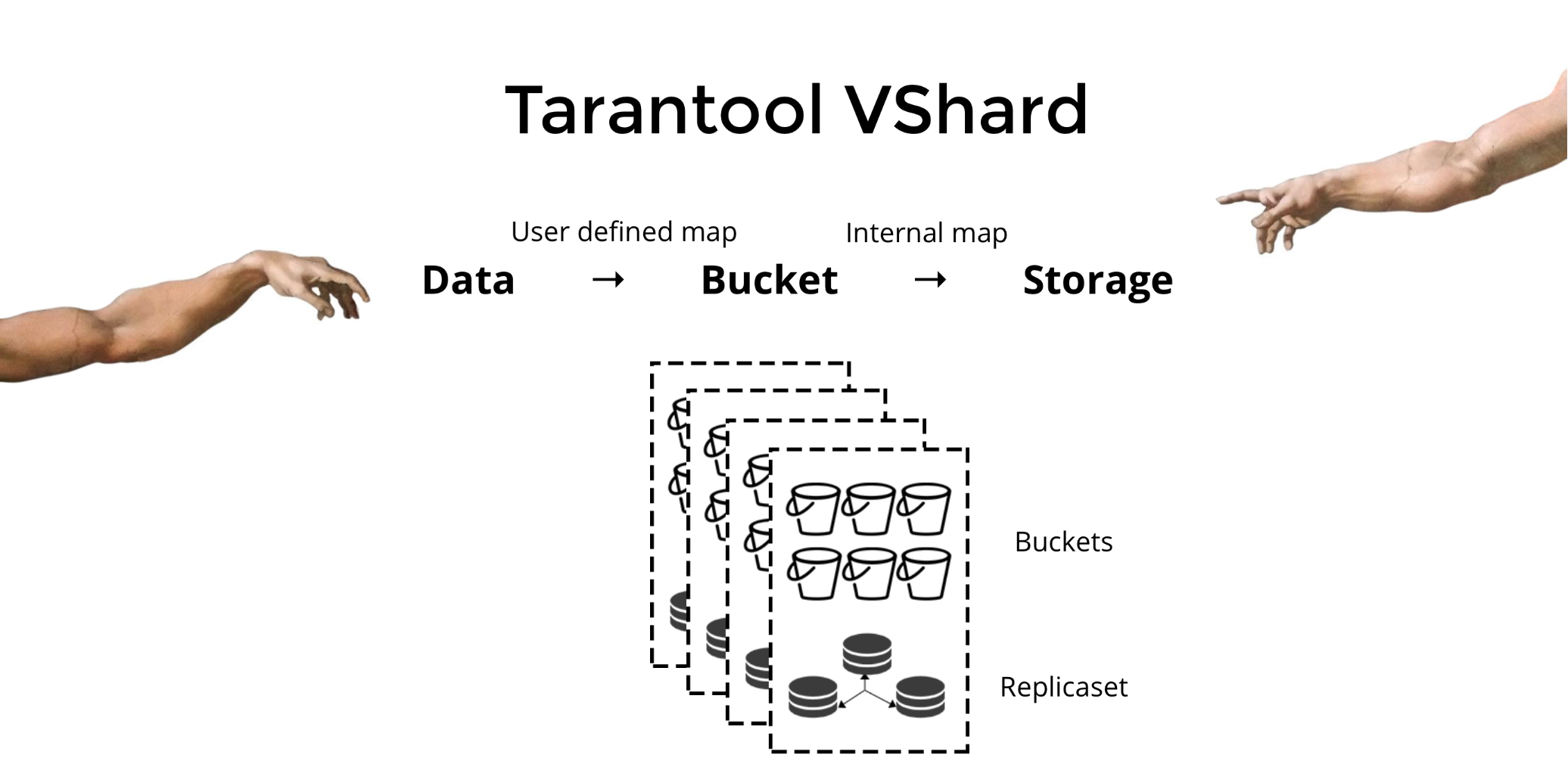
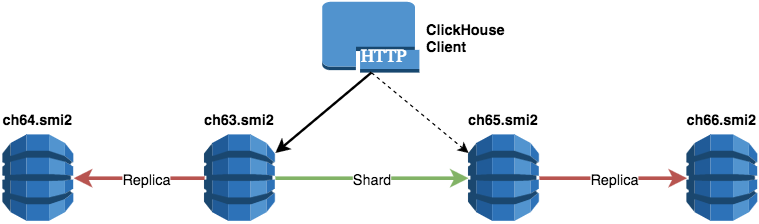
Шардинг
Вопрос масштабирования приложений в облаке возникает очень часто. Сама концепция облачных технологий подразумевает масштабирование приложений по запросу. Любой уважающий себя облачный провайдер поддерживает соответствующие функции.
Зачем вообще нужно горизонтальное масштабирование? Когда возникает вопрос повышения производительности приложения, то есть несколько вариантов. Как известно можно купить новое «железо» для сервера, добавить количество оперативной памяти и т. д. Этот принцип называется вертикальным масштабированием. Однако этот способ может быть достаточно дорогим, долгим, да и имеет предел. Можно конечно купить топовое железо, однако оно может не потянуть все требования вашего приложения.
Второй способ, называемый горизонтальным масштабированием, предполагает расширение вычислительных ресурсов доступных приложению за счет увеличения количества серверов или инстансов приложения, в случае PaaS, на которых размещено ваше приложение. То есть если раньше ваше приложение было расположено на одном сервере, и в какой-то момент оно перестало «вытягивать» нагрузку, можно просто купить второй точно такой же сервер. Поставить на него ваше приложение и таким образом часть запросов к приложению будет идти на первый сервер, часть — на второй.
Этот принцип и положен в горизонтальное масштабирование приложений размещенных в «облаке», только вместо реальных физических серверов и у нас есть понятие виртуальная машина. Когда экземпляра одной виртуальной машины недостаточно вашему приложению — вы можете увеличить его, таким образом распределив нагрузку между несколькими виртуальными машинами.
Если рассматривать возможности облачной платформы от Microsoft, то они достаточно широкие. Есть auto-scaling, scaling по запросу, причем все это доступно как с помощью UI, так и с помощью SDK, REST API и PowerShell.
Однако если с масштабированием приложения (PaaS) или виртуальных машин (IaaS) все достаточно просто, указываете сколько инстансов вам необходимо, столько и будет, то в случае если ваше приложение использует базы данных MS SQL, возникает несколько вопросов. Конечно первое что приходит в голову — организовать кластер из виртуальных машин SQL Server. Решение достаточно простое и хорошо всем знакомое. А что делать, если приложение использует базу данных как сервис (SaaS)? Что если мы не хотим заниматьсянастройкой кластера SQL Server?
Конечно же, если мы говорим о Windows Azure, то в качестве SQL базы данных будет использоваться SQL Azure. Эта база данных поддерживает технологию горизонтального масштабирования (шардинг) называемую SQL Azure Federations. Принцип ее работы очень простой: логически независимые друг от друга строки одной таблицы хранятся в разных базах данных. Самый простой пример:

Это одна и та же таблица, данные которой хранятся в разных экземплярах базы данных (шардах). То есть данные аккаунта с идентификатором 1 хранятся в первой базе данных, с идентификатором 2 — во второй и т. д.
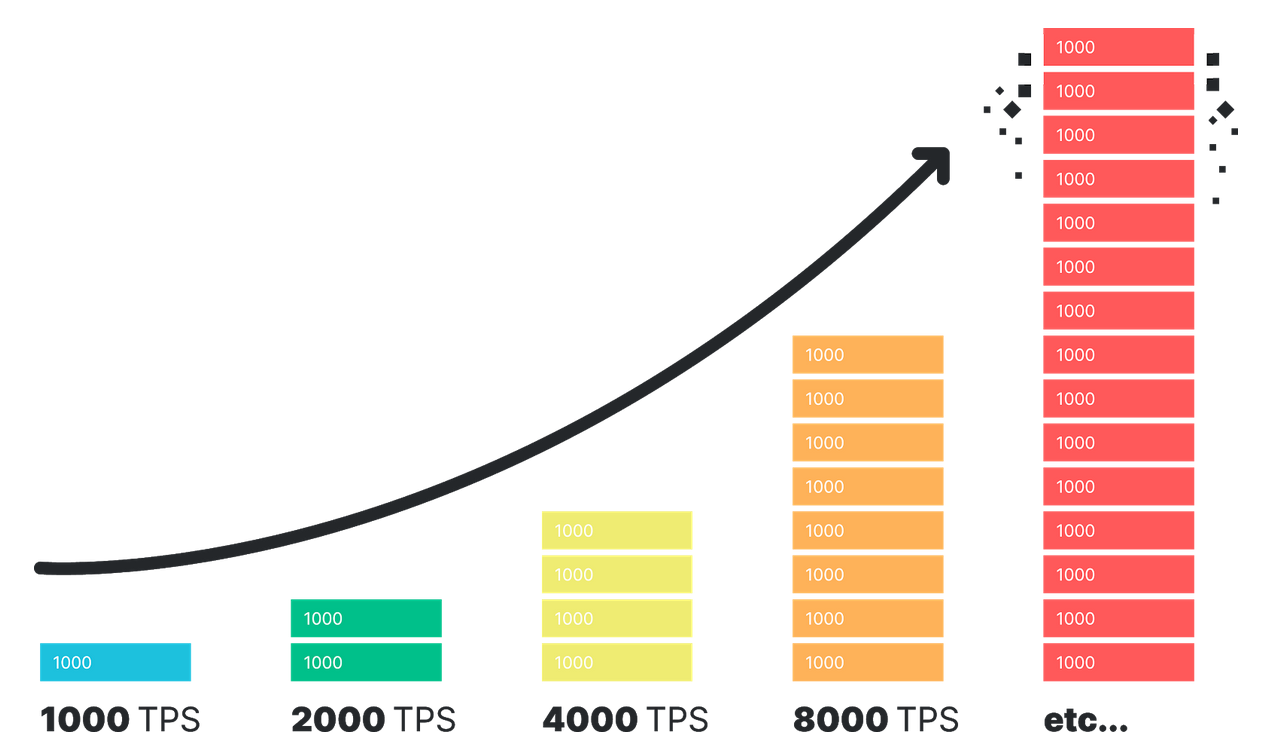
 Начну с того, что наш проект находится на начальной стадии развития, а его запуск планируется на 1е ноября. И, чтобы сразу отсечь всю возможную критику касаемо преждевременной оптимизации, скажу, что перед командой была поставлена задача разработать приложение, справляющееся с резкими скачками нагрузки (от 1000 до 50000 и т. п.). В связи с этим было решено закладывать хорошо масштабируемую архитектуру, позволяющую легко и быстро увеличивать производительность системы за счет аппаратной части (по принципу scale-out).
Начну с того, что наш проект находится на начальной стадии развития, а его запуск планируется на 1е ноября. И, чтобы сразу отсечь всю возможную критику касаемо преждевременной оптимизации, скажу, что перед командой была поставлена задача разработать приложение, справляющееся с резкими скачками нагрузки (от 1000 до 50000 и т. п.). В связи с этим было решено закладывать хорошо масштабируемую архитектуру, позволяющую легко и быстро увеличивать производительность системы за счет аппаратной части (по принципу scale-out).