Иногда возникает задача «склеить» внутри SQL-запроса из переданных в качестве параметров линейных массивов целостную выборку с теми же данными «по столбцам».
PostgreSQL Antipatterns: передача наборов и выборок в SQL
5 min
Периодически у разработчика возникает необходимость передать в запрос набор параметров или даже целую выборку «на вход». Иногда попадаются очень странные решения этой задачи.
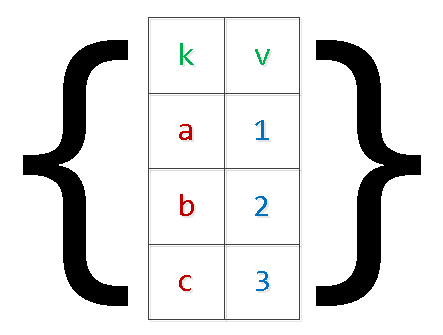
Пойдем «от обратного» и посмотрим, как делать не стоит, почему, и как можно сделать лучше.
Пойдем «от обратного» и посмотрим, как делать не стоит, почему, и как можно сделать лучше.
Как использовать функцию UNNEST в Google BigQuery для анализа параметров событий Google Analytics
6 min
Tutorial
Translation

Сегодня я расскажу о том, как использовать функцию `UNNEST` в Google BigQuery для анализа параметров событий и свойств пользователей, которые вы получаете вместе с данными Google Analytics.
Как использовать конструкцию SELECT FROM UNNEST для анализа параметров в повторяющихся записях Google BigQuery
7 min
Tutorial
Translation

В предыдущей статье мы с вами разобрались с тем, как использовать функцию UNNEST для работы с повторяющимися записями в Google BigQuery.
В этой статье мы идём дальше, и поговорим про конструкцию SELECT FROM UNNEST.
Используя конструкцию SELECT FROM UNNEST, вы говорите: «Я хочу применить функцию UNNESTк повторяющейся записи в ее собственной маленькой временной таблице. Далее выбрать одну строку из неё и поместить ее в наши результаты, так же как если бы это было любое другое значение ».
PostgreSQL Antipatterns: DBA-детектив, или Три дела о потерянной производительности
30 min
Сегодня вместо решения абстрактных алгоритмических задач мы выступим в роли детектива, по крупицам доставшейся информации исследующего неэффективные запросы, и рассмотрим три реальных дела, встречавшихся в разное время на просторах нашего приложения СБИС, когда простота и наивность при написании SQL превращалась в дополнительную нагрузку для PostgreSQL-сервера.

Дедукция и индукция помогут нам вычислить, что же все-таки хотел получить от СУБД разработчик, и почему это получилось не слишком оптимально. Итак, сегодня нас ждут:
Дедукция и индукция помогут нам вычислить, что же все-таки хотел получить от СУБД разработчик, и почему это получилось не слишком оптимально. Итак, сегодня нас ждут:
- Дело о непростом пути вверх
Разберем в live-видео на реальном примере некоторые из способов улучшения производительности иерархического запроса. - Дело о худеющем запросе
Увидим, как можно запрос упростить и ускорить в несколько раз, пошагово применяя стандартные методики. - Дело о развесистой клюкве
Восстановим структуру БД на основании единственного запроса с 11JOINи предложим альтернативный вариант решения на ней той же задачи.
SQL HowTo: 1000 и один способ агрегации
5 min
Наш СБИС, как и другие системы управления бизнесом, не обходится без формирования отчетов — каждый руководитель любит сводные цифры, особенно всякие суммы по разделам и красивые "Итого".
А чтобы эти итоги собрать, необходимо по исходным данным вычислить значение некоторой агрегатной функции: количество, сумма, среднее, минимум, максимум,… — и, как правило, не одной.
Сегодня мы рассмотрим некоторые способы, с помощью которых можно вычислить агрегаты в PostgreSQL или ускорить выполнение SQL-запроса.
А чтобы эти итоги собрать, необходимо по исходным данным вычислить значение некоторой агрегатной функции: количество, сумма, среднее, минимум, максимум,… — и, как правило, не одной.
Сегодня мы рассмотрим некоторые способы, с помощью которых можно вычислить агрегаты в PostgreSQL или ускорить выполнение SQL-запроса.
SQL HowTo: пишем while-цикл прямо в запросе, или «Элементарная трехходовка»
5 min
Периодически возникает задача поиска связанных данных по набору ключей, пока не наберем нужное суммарное количество записей.
Наиболее «жизненный» пример — вывести 20 самых старых задач, числящихся на списке сотрудников (например, в рамках одного подразделения). Для различных управленческих «дашбордов» с краткими выжимками по участкам работы похожая тема требуется достаточно часто.

В статье рассмотрим реализацию на PostgreSQL «наивного» варианта решения такой задачи, «поумнее» и совсем сложный алгоритм «цикла» на SQL с условием выхода от найденных данных, который может быть полезен как для общего развития, так и для применения в других похожих случаях.
Наиболее «жизненный» пример — вывести 20 самых старых задач, числящихся на списке сотрудников (например, в рамках одного подразделения). Для различных управленческих «дашбордов» с краткими выжимками по участкам работы похожая тема требуется достаточно часто.
В статье рассмотрим реализацию на PostgreSQL «наивного» варианта решения такой задачи, «поумнее» и совсем сложный алгоритм «цикла» на SQL с условием выхода от найденных данных, который может быть полезен как для общего развития, так и для применения в других похожих случаях.
Разворачиваем вложенные столбцы — списки с помощью языка R (пакет tidyr и функции семейства unnest)
24 min
Tutorial
Translation
В большинстве случаев при работе с ответом полученным от API, или с любыми другими данными которые имеют сложную древовидную структуру, вы сталкиваетесь с форматами JSON и XML.
Эти форматы имеют множество преимуществ: они достаточно компактно хранят данные и позволяют избежать излишнего дублирования информации.
Минусом данных форматов является сложность их обработки и анализа. Неструктурированные данные невозможно использовать в вычислениях и нельзя строить на их основе визуализацию.

Данная статья является логическим продолжением публикации "R пакет tidyr и его новые функции pivot_longer и pivot_wider". Она поможет вам привести неструктурированные конструкции данных к привычному, и пригодному для анализа табличному виду с помощью пакета tidyr, входящего в ядро библиотеки tidyverse, и его функций семейства unnest_*().
КЛАДРируем адреса произвольной формы (ч.2 — подстрочный поиск)
12 min
Tutorial

В первой части серии статей про работу с адресами по КЛАДР мы научились импортировать данные этого справочника к себе в базу и превращать их во что-то более удобное для дальнейшей работы.
Сегодня же займемся реализацией конкретных прикладных алгоритмов на этой структуре и рассмотрим, как можно реализовать мгновенную помощь пользователю при вводе адреса, используя возможности префиксного поиска в PostgreSQL.
SQL HowTo: замена в строке по набору
Easy
2 min
Tutorial

Решим сегодня простую, казалось бы, задачу: как на PostgreSQL можно в строке провести замены по набору пар строк. То есть в исходной строке 'abcdaaabbbcccdcba' заменить, например, 'а' -> 'x', 'bb' -> 'y', 'ccc' -> 'z' и получить 'xbcdxxxybzdcbx'.
Фактически, мы попробуем создать аналог str_replace или strtr.