Хочу начать серию статей, посвящённых отладке ваших .NET приложений на стороне заказчика, а также оптимизации вашего кода. В связи с этим понадобиться немного подготовить вашу систему. В этой статье мы ознакомимся с различными инструментами для отладки приложений, немного углубимся в описание CLR, где это будет необходимо.
Получение метаданных .NET на клиенте с использованием ajax
3 min
Всем, кто программирует в среде ASP.NET MVC, хорошо известно, насколько широко используются метаданные в .NET вообще и в MVC в частности. В MVC, атрибуты применяются как при генерации разметки, так и при валидации данных, полученных с клиента.
При использовании классической модели программирования сайтов это прекрасно работает. Но что, если Вы работаете с использование ajax и формируете html разметку динамически на клиенте? Вы хотите иметь метаданные модели (далее МДМ) на клиенте? Я — да!
При использовании классической модели программирования сайтов это прекрасно работает. Но что, если Вы работаете с использование ajax и формируете html разметку динамически на клиенте? Вы хотите иметь метаданные модели (далее МДМ) на клиенте? Я — да!
Троян, ворующий предметы из инвентаря Steam
4 min

Хотя про этот троян известно достаточно давно, настоящую массовость он приобрел в конце ноября.
Интересно в нем то, что вместо обычной кражи логинов и паролей, от которой можно вполне просто защититься, он напрямую ворует предметы из инвентаря Steam.
Компания Valve давно в курсе проблемы, но каких-то особых действий за несколько месяцев так и не предприняла, хотя текущую волну можно без проблем остановить небольшими изменениями в клиенте Steam.
5 способов сравнить два байтовых массива. Сравнительное тестирование
32 min
 В результате профилирования моей софтины я сделал вывод о необходимости оптимизации функции сравнения буферов.
В результате профилирования моей софтины я сделал вывод о необходимости оптимизации функции сравнения буферов.Т.к. CLR не предоставляет стандартного способа сравнить два куска памяти, то функция была написан на скорую руку самостоятельно (лишь бы работало).
Погуглив по фразе «Best Way to Compare Byte Arrays in .Net», я пришёл в замешательство: в абсолютном большинстве случаев люди предлагали использовать либо LINQ, либо Enumerable.SequenceEqual(), что практически одно и тоже. Даже на StackOverflow это был самый популярный ответ. Т.е. катастрофически популярно заблуждение вида:
«Compiler\run-time environment will optimize your loop so you don't need to worry about performance.» Отсюда.
Именно оно впервые навело меня на мысль написать этот пост.
Я провёл сравнительное тестирование пяти способов сравнения буферов, доступных из C#, и на основании результатов тестирования дал рекомендации в выборе способа.
Кроме того, я декомпилировал некоторые функции, и проанализировал код, генерируемый JIT-компилятором для конфигурации x86, а так же сравнил машинный код, генерируемый JIT-компилятором, с машинным кодом функции CRT аналогичного назначения.
6 простых вопросов по C# с подвохом
7 min
Почитав 10 простых задач на c# с подвохом я огорчился т.к. по сути своей там и подвохов-то не было особо (этак можно скатиться до "чему будет равно i++ + ++i")… Посему решил немного повспоминать подвохи, которые не хотел бы видеть никогда в жизни 8-). Уровень подготовки middle наверно.
Деревья выражений в C# на примере нахождения производной (Expression Tree Visitor vs Pattern matching)
18 min
Доброго времени суток. Деревья выражений, особенно в сочетании с паттерном Visitor, всегда являлись довольно запутанной темой. Поэтому чем больше разнообразной информации по этой теме, чем больше примеров, тем легче интересующимся будет найти что-то, что им понятно и полезно.

Истинная реализация нейросети с нуля на языке программирования C#
10 min

Здравствуй, Хабр! Данная статья предназначена для тех, кто приблизительно шарит в математических принципах работы нейронных сетей и в их сути вообще, поэтому советую ознакомиться с этим перед прочтением. Хоть как-то понять, что происходит можно сначала здесь, потом тут.
Недавно мне пришлось сделать нейросеть для распознавания рукописных цифр(сегодня будет не совсем её код) в рамках школьного проекта, и, естественно, я начал разбираться в этой теме. Посмотрев приблизительно достаточно об этом в интернете, я понял чуть более, чем ничего. Но неожиданно(как это обычно бывает) получилось наткнуться на книгу Саймона Хайкина(не знаю почему раньше не загуглил). И тогда началось потное вкуривание матчасти нейросетей, состоящее из одного матана.
Решаем Open Day CrackMe, таск Pizza
25 min
Tutorial
На момент написания статьи (16.12.2017) ридми от ЛК еще не выложили, поэтому я подумал, что можно и свой пока написать. Кому интересно почитать, как работать с il-кодом в powershell и какая у .NET PE структура, прошу под кат.
Полигоны Doom на Playstation
18 min
Translation

Sony PlayStation
История PlayStation началась в 1988 году, когда Nintendo и Sony приступили к совместной работе над дополнительным устройством чтения CD-ROM для консоли SNES. По условиям договора Sony могла независимо разрабатывать игры для этой платформы и сохраняла контроль над форматом «Super Disc» — две необычные уступки со стороны Nintendo.
Проект развивался до выставки CES ’91, на которой Sony объявила о совместном работе над «Play Station». На следующий день в рамках той же выставки Nintendo, к удивлению Sony, объявила, что вместо этого заключила партнёрское соглашение с Philips (на гораздо более выгодных условиях). Преданная и публично униженная Sony попыталась обратиться к совету директоров Sega, сразу же отклонившему эту идею. В интервью 2013 года генеральный директор SEGA Том Калинске вспоминал о решении совета.
«Это глупая идея, Sony не знает, как разрабатывать оборудование. Они не знают и как писать ПО. Зачем нам с ними связываться?» — совет директоров SEGA
И они не ошибались, у Sony действительно было мало опыта в работе с играми. Она почти и не проявляла к ним интереса, за исключением инициативы одного человека — Кена Кутараги. С того самого момента, как он увидел, как его дочь играет в Nintendo Famicom, Кен убеждал Sony, что нужно выйти на этот рынок. Несмотря на рекомендации вице-президентов Sony, он даже разработал для Nintendo аудиочип (SPC700), использованный в SNES.
Большинство руководителей Sony посчитало это рискованной ставкой, но Кутараги обрёл поддержку в лице генерального руководителя Sony Норио Ога. В июне 1992 года Кену позволили начать с нуля создание игровой системы. Для успокоения совета директоров «отца PlayStation», как его стали называть позже, перевели в финансово независимую от родительской компании Sony Music, и он приступил к работе над тем, что со временем превратится в «PlayStation» (уже без пробела в названии).
Semantic BPM. Семантика и синтаксис бизнес-процессов
Medium
26 min
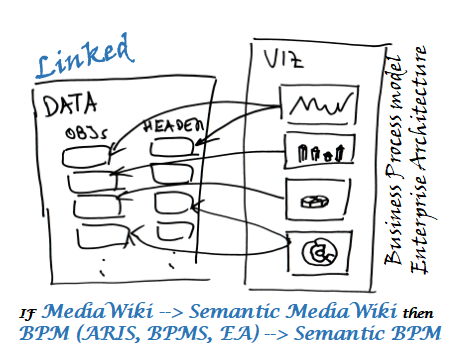
Онтологический инжиниринг в области Управления бизнес-процессами (BPM). Семантический BPM (Business Process Management), впрочем, как и семантический ЕА (Enterprise Architecture), – это заимствование концепций (подходов к описанию и онтологизации) \ инструментов Linked Data к указанным направлениям (формализация процессов и архитектур предприятий).
«Красная нить»: когда мы формализуем процессы - мы говорим об одном и том же, но на разных языках (нотациях), поэтому стандартизация Языка семантики, онтологических концептов BPM (EA) – важная, но еще недостаточно популяризированная составляющая развития BPM (следующий этап, ВРМ 3.0). Отделение («мух от котлет») семантики от синтаксиса позволит «рафинировать» понятийный (смысловой) анализ бизнес-процессов и при их аналитике оперировать базовыми (семантическими) концептами (образами).
В Semantic BPM, как и в Semantic Web (семантическая паутина), смысл представленного процесса \ архитектуры понятен не только человеку, но и машинам и они могут его читать и обрабатывать. Эти смыслы, обычно передаваемые «человек – человек» на языке синтаксиса / графической грамматики через нотации VAD, EPC, BPMN, UML (плюс еще несколько десятков подобных вариантов \ форматов «обертывания», включая Дракон), исходно формализуются на языке семантики (стек Linked Data или аналогичный) и уже потом упаковываются в схемы с конкретной нотацией («пишутся» на языке какой-либо нотации). Для единого понимания смысловой составляющей схем применяется общая ВРМ-онтология, толковый словарь ВРМ.
Создаем изометрические уровни игры с помощью Stable Diffusion
Easy
5 min
Tutorial

Всем привет. Сегодня я покажу вам, как можно создавать 2.5D уровни в изометрии с помощью быстрого прототипирования техникой grayboxing, и генеративного искусственного интеллекта, а именно Stable Diffusion. Практически весь процесс, описываемый в статье, довольно легко автоматизируется.
Если интересно, добро пожаловать под кат.
Шпаргалка для искусственного интеллекта — выбрось лишнее, учи главному. Техника обработки обучающих последовательностей
16 min
Recovery Mode
Это вторая статья по анализу и изучению материалов соревнования по поиску корабликов на море. Но сейчас будем изучать свойства обучающих последовательностей. Попробуем найти в исходных данных лишнюю информацию, избыточность и её удалить.

Статья эта тоже есть просто результат любопытства и праздного интереса, ничего из нее в практике не встречается и для практических задач тут нет почти ничего для копипастинга. Это небольшое исследование свойств обучающей последовательности — рассуждения автора и код изложены, можно все проверить/дополнить/изменить самим.
Недавно закончились соревнования на kaggle по поиску судов на море. Компания Airbus предлагала провести анализ космических снимков моря как с судами так и без. Всего 192555 картинок 768х768х3 — это 340 720 680 960 байт если uint8 и это громадный объем информации и возникло смутное подозрение, что не все картинки нужны для обучения сети и в таком количестве информации очевидны повторы и избыточность. При обучении сети принято некоторую часть данных отделять и не использовать в обучении, а использовать для проверки качества обучения. И если один и тот же участок моря попал на два разных снимка и при этом один снимок попал в тренировочную последовательность, а другой в проверочную, то проверка смысл потеряет и сеть переобучится, мы не проверим свойство сети обобщать информацию, ведь данные те же самые. Борьба с эти явлением отняла много сил и времени GPU участников. Как обычно, победители и призеры не торопятся показать своим поклонникам секреты мастерства и выложить код и нет возможности его изучить и поучиться, поэтому займемся теорией.
Статья эта тоже есть просто результат любопытства и праздного интереса, ничего из нее в практике не встречается и для практических задач тут нет почти ничего для копипастинга. Это небольшое исследование свойств обучающей последовательности — рассуждения автора и код изложены, можно все проверить/дополнить/изменить самим.
Недавно закончились соревнования на kaggle по поиску судов на море. Компания Airbus предлагала провести анализ космических снимков моря как с судами так и без. Всего 192555 картинок 768х768х3 — это 340 720 680 960 байт если uint8 и это громадный объем информации и возникло смутное подозрение, что не все картинки нужны для обучения сети и в таком количестве информации очевидны повторы и избыточность. При обучении сети принято некоторую часть данных отделять и не использовать в обучении, а использовать для проверки качества обучения. И если один и тот же участок моря попал на два разных снимка и при этом один снимок попал в тренировочную последовательность, а другой в проверочную, то проверка смысл потеряет и сеть переобучится, мы не проверим свойство сети обобщать информацию, ведь данные те же самые. Борьба с эти явлением отняла много сил и времени GPU участников. Как обычно, победители и призеры не торопятся показать своим поклонникам секреты мастерства и выложить код и нет возможности его изучить и поучиться, поэтому займемся теорией.
Кто потерял ключи: по следам SSH
8 min

В 2015 году поднялась большая шумиха, когда по всему миру на различных узлах были обнаружены одинаковые SSH-отпечатки. Далее шума дело не пошло, но осадок остался. Попробуем разобраться, в чем основная опасность таких «дублей». Большая часть собранных данных актуальна для 2015 года.
Установка и нaстройка Puppet версии 3.8 на примере Centos 6.5
8 min
Puppet, Chef, Ansible — это так называемые системы управления конфигурациями, которые можно часто встретить в зарубежных IT вакансиях типа Server/DevOps Admin. Фактически же это мощные инструменты которые могут полностью настроить нулёвый сервер или же достаточно быстро массово перенастроить набор из 1-100+ серверов. Работа с пакетами, с командной строкой, файлами настроек, доступно всё.
Общий обзор можно прочитать в публикации «Как стать кукловодом».
Собственно к написанию этой начальной статьи для Puppet меня сподвигло крайне скудное описание во встречающихся в интернете результатах. И даже при использовании официальной документации умудряешься наткнуться на кучу грабель и подводных камней и получить не то, что ожидал.
Причина использования ветки 3.8, вместо 4.3 заключается в использовании именно этой версии на «моих» серверах из-за наличия именно этих пакетов в репо. Платный вариант Enterprise также не рассматривается, т. к. я с ним не работал. Причина использования Centos – он достаточно широко распространён, включая доработанные версии от Amazon.
Для локальных тестов можно использовать две виртуалки на VirtualBox под CentOS-6.5-x86_64.
Общий обзор можно прочитать в публикации «Как стать кукловодом».
Собственно к написанию этой начальной статьи для Puppet меня сподвигло крайне скудное описание во встречающихся в интернете результатах. И даже при использовании официальной документации умудряешься наткнуться на кучу грабель и подводных камней и получить не то, что ожидал.
Причина использования ветки 3.8, вместо 4.3 заключается в использовании именно этой версии на «моих» серверах из-за наличия именно этих пакетов в репо. Платный вариант Enterprise также не рассматривается, т. к. я с ним не работал. Причина использования Centos – он достаточно широко распространён, включая доработанные версии от Amazon.
Для локальных тестов можно использовать две виртуалки на VirtualBox под CentOS-6.5-x86_64.
Причины спекуляций в строительной отрасли. Монополии корпораций над данными. Войны лоббистов и развитие BIM. Часть 6
19 min
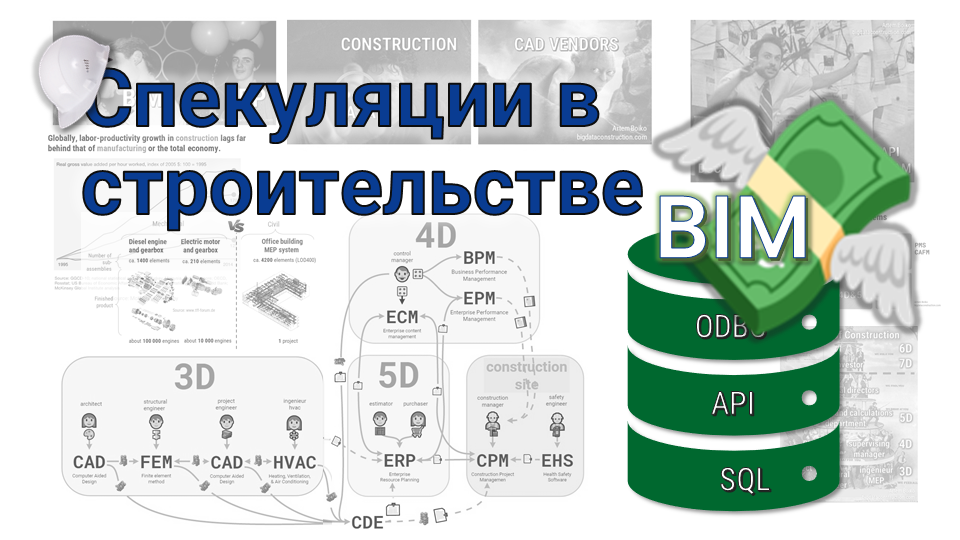
Причиной отсутствия роста производительности и распространения спекуляций в строительной отрасли является качество данных, которыми оперируют участники процессов строительства. В чем основная проблема данных в строительстве? В первую очередь, в отсутствии доверия и прозрачности в системах 3D-7D, что ведёт к появлению рисков, связанных с человеческим фактором, и созданию многоуровневой бюрократии в основных бизнес-процессах строительных компаний.
Сегодня при обмене данными между различными 3D-7D системами мы доверяем хранение наших данных корпорациям. Для поддержания своего влияния на строительную отрасль корпорации, которым невыгодна прозрачность и интероперабельность данных, монополизировали хранение и обработку данных. Вследствие этого поставщики основных CAD и ERP решений постоянно повышают цены за пользование своими продуктами, а простые пользователи вынуждены платить “комиссию” на каждом этапе передачи данных в системах 3D-7D: за подключение, импорт, экспорт и работу с данными, которые пользователи сами создали.
Ваша первая нейронная сеть на графическом процессоре (GPU). Руководство для начинающих
9 min
Tutorial

В этой статье я расскажу как за 30 минут настроить среду для машинного обучения, создать нейронную сеть для распознавания изображений a потом запустить ту же сеть на графическом процессоре (GPU).
Для начала определим что такое нейронная сеть.
В нашем случае это математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения — одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение.
С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и прочих методов.
Оборудование
Сначала разберемся с оборудованием. Нам необходим сервер с установленной на нем операционной системой Linux. Оборудование для работы систем машинного обучения требуется достаточно мощное и как следствие дорогое. Тем, у кого нет под рукой хорошей машины, рекомендую обратить внимание на предложение облачных провайдеров. Необходимый сервер можно получить в аренду быстро и платить только за время использования.
Введение в сетевую часть облачной инфраструктуры
74 min

Облачные вычисления все глубже и глубже проникают в нашу жизнь и уже наверно нет ни одного человека, который хотя бы раз не пользовался какими либо облачными сервисами. Однако что же такое облако и как оно работает в большинстве своем мало кто знает даже на уровне идеи. 5G становится уже реальностью и телеком инфраструктура начинает переходить от столбовых решений к облачным решениями, как когда переходила от полностью железных решений к виртуализированным «столбам».
Сегодня поговорим о внутреннем мире облачной инфраструктуре, в частности разберем основы сетевой части.
Явка провалена: выводим AgentTesla на чистую воду. Часть 1
7 min

Недавно в Group-IB обратилась европейская компания-производитель электромонтажного оборудования — ее сотрудник получил по почте подозрительное письмо с вредоносным вложением. Илья Померанцев, специалист по анализу вредоносного кода CERT Group-IB, провел детальный анализ этого файла, обнаружил там шпионскую программу AgentTesla и рассказал, чего ждать от подобного ВПО и чем оно опасно.
Этим постом мы открываем серию статей о том, как проводить анализ подобных потенциально опасных файлов, а самых любопытных ждем 5 декабря на бесплатный интерактивный вебинар по теме «Анализ вредоносного ПО: разбор реальных кейсов». Все подробности — под катом.
Развертывание тестового кластера VMware Virtual SAN 6.2
17 min
Tutorial
Введение
Передо мной была поставлена задача — развернуть кластер VMware Virtual SAN 6.2 для тестирования производительности, анализа возможностей, особенностей и принципов работы гиперконвергентной программной СХД от VMware.
Кроме того, созданный тестовый стенд должен стать платформой для разработки и апробирования методики тестирования распределенных СХД, в т.ч. для гиперконвергентных инфрастуктур (HCI).
Результатов тестирования и описания его методики в данной статье не будет, вероятно этому будет посвящена отдельная публикация.
Данная статья будет полезна специалистам, которые впервые сталкиваются с развертыванием кластера VMware Virtual SAN 6.2. Я постарался указать подводные камни, на которые можно напороться при поднятии кластера, что позволит значительно сократить время и нервы на их обход.
Заглянем за кулисы разработки: подборка исходных кодов классических игр
10 min
Translation
Обожаю заглядывать за кулисы. Мне интересно, как делаются вещи. Мне кажется, что большинству людей это тоже интересно.
Исторически так сложилось, что видеоигры не делятся исходниками. Конечно, они ведь предназначены для игроков. Но для программистов там всегда есть, на что посмотреть. И некоторые игры всё-таки выпускали свои исходники. А я давно намеревался сделать такую подборку.
К сожалению, почти все игры – для PC. Найти исходники для консолей или аркад почти нереально, и большинство программистов не в курсе различий подходов к программам на платформах, отличных от PC.
Многие игры после выпуска исходников были улучшены и дополнены сообществом – я намеренно даю ссылки только на оригинальные исходники. Так что, если вас вдруг интересуют апгрейды – они могут существовать.
Многие игры были рассмотрены на сайте Fabien Sanglard. Если вам интересны подробности их работы, то пожалуйте к нему.
Можно заметить, что многие игры принадлежат id Software/Apogee. Совпадение? Не думаю. id славится открытостью и привычкой выпускать исходники. Старые коммерческие игры уже не имеют ценности и были бы потеряны – не лучше ли, чтобы кто-то учился чему-то полезному на их основе?
Итак, приступим (в хронологическом порядке):
Исторически так сложилось, что видеоигры не делятся исходниками. Конечно, они ведь предназначены для игроков. Но для программистов там всегда есть, на что посмотреть. И некоторые игры всё-таки выпускали свои исходники. А я давно намеревался сделать такую подборку.
К сожалению, почти все игры – для PC. Найти исходники для консолей или аркад почти нереально, и большинство программистов не в курсе различий подходов к программам на платформах, отличных от PC.
Многие игры после выпуска исходников были улучшены и дополнены сообществом – я намеренно даю ссылки только на оригинальные исходники. Так что, если вас вдруг интересуют апгрейды – они могут существовать.
Многие игры были рассмотрены на сайте Fabien Sanglard. Если вам интересны подробности их работы, то пожалуйте к нему.
Можно заметить, что многие игры принадлежат id Software/Apogee. Совпадение? Не думаю. id славится открытостью и привычкой выпускать исходники. Старые коммерческие игры уже не имеют ценности и были бы потеряны – не лучше ли, чтобы кто-то учился чему-то полезному на их основе?
Итак, приступим (в хронологическом порядке):