Сегодня всё чаще требуется учитывать географическую привязку и выполнять поиск в локальном окружении клиента. Иными словами, регулярно возникает необходимость найти что-то (или кого-то) рядом с конкретным пользователем. «Где ближайший банкомат?», «Кто из друзей поблизости?», «Какие тут аптеки?». Подобные запросы миллионами поступают в сервисы геолокации каждый день, при этом существующие подходы к решению этой задачи не исчерпали возможностей оптимизации. Наверняка вы не раз сетовали на то, как долго обновляются метки на карте.
В этой статье эксперт отдела перспективных исследований российской компании «Криптонит» Игорь Нетай рассказывает о способе ускорить обнаружение объектов, принадлежащих одному географическому региону с произвольно заданными размерами. Материал станет частью научной работы о перспективах применения H-кривых в геохешинге.
С помощью рассмотренной в этой статье алгоритмической оптимизации можно быстрее выполнять поиск в различных масштабах — от полушария Земли до конкретного здания.
Координаты одной строкой
Удобство географической персонализации постепенно вытеснило паранойю, и во многих онлайн-сервисах теперь открыто используются данные о местоположении пользователей и различных объектов. Делаете заказ через интернет? Вам предложат забрать его в пункте выдачи поближе к дому. Вызываете такси? Сначала запрос передаётся водителям рядом с вами. Ищете кафе? На карте отобразятся ближайшие.
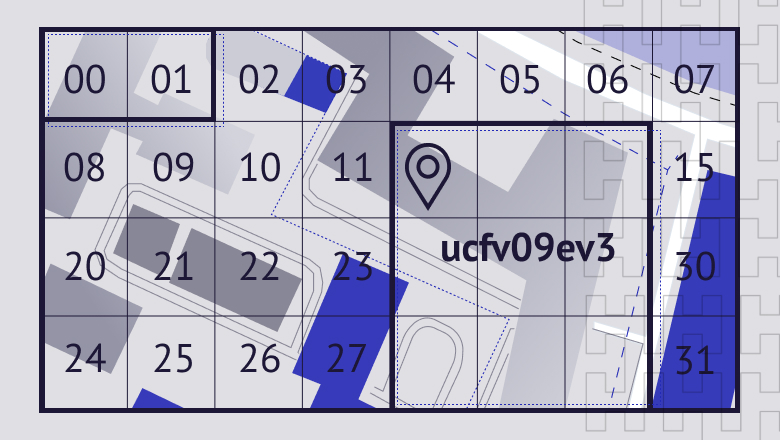
Все эти алгоритмы сводятся к решению одной и той же задачи: они определяют, какие координатные точки из базы данных входят в тот же условно заданный регион, что и указанная в запросе целевая точка (как правило, обозначающая местоположение пользователя). Для этого используется система кодирования географических координат в виде значений хеш-функции, называемых геохеши.