
Всем привет! Меня зовут Евгений, я занимаюсь разработкой и проектированием в Ozon. Больше всего работаю с MS SQL и C#, но попадаются и другие СУБД и языки программирования.
Ozon как продукт быстро растёт: во втором квартале этого года мы доставляли больше миллиона посылок в день. Для обработки такого объёма заказов мы используем разные языки и платформы: .NET (C#), Go, MS SQL Server и PostgreSQL.
Заказы пользователей обрабатываются разными системами, которые взаимодействуют между собой. Это порождает необходимость учитывать многочисленные интеграции и приводит к проблеме дублирования данных.
Я расскажу об одном таком случае, когда наша команда потратила много времени и сил, но всё-таки нашла оптимальный способ решения проблемы дублирования данных.
Но сначала позвольте погрузить вас немного в предметную область — объясню, на примере чего будет демонстрироваться проблема дублирования данных, и освещу некоторые методы её решения.
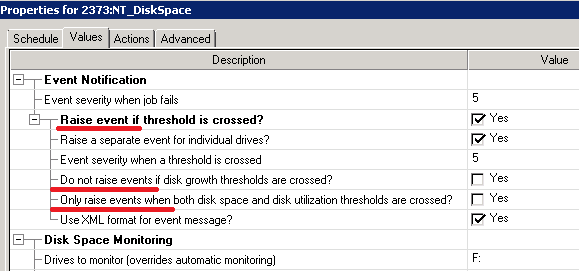









 В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.
В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.