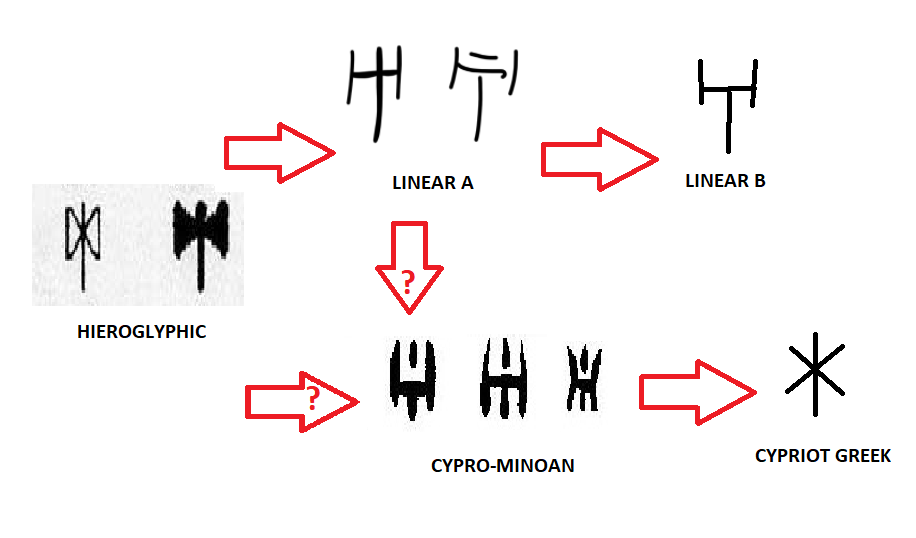
Мощнейшая древнеиндийская цивилизация по своему развитию не уступала Месопотамии и Египту, однако, в отличии от них, не оставила почти никаких письменных артефактов. Всё её лингвистическое наследие — около 1500 полустёртых надписей на осколках посуды, датированных между 2600 и 1900 гг. до н.э. Этот язык вообще не поддаётся расшифровке, потому что самый длинный фрагмент надписи составляет всего 27 символов.

Более столетия археологи безуспешно бьются над загадкой древнеиндийского языка. Обнаружено его сходство со множеством других языков, в том числе древнеславянским. В итоге, после многих лет безуспешных попыток было практически решено, что надписи на самом деле представляют собой не текст, а это просто отдельные символы политического и религиозного содержания — вот одна из научных работ, доказывающих данный тезис. Мол, у индусов того времени, возможно, совсем не было письменности.
Однако с этим оказались в корне не согласны индийские программисты, специалисты по искусственному интеллекту, которые создали специальную программу для поиска лингвистических структур в исторических надписях. Перед работой систему натренировали на трёх вербальных языках (современный английский, санскрит, шумерский) и трёх невербальных системах коммуникации (человеческая ДНК, Фортран, протеины бактерий).
Более столетия археологи безуспешно бьются над загадкой древнеиндийского языка. Обнаружено его сходство со множеством других языков, в том числе древнеславянским. В итоге, после многих лет безуспешных попыток было практически решено, что надписи на самом деле представляют собой не текст, а это просто отдельные символы политического и религиозного содержания — вот одна из научных работ, доказывающих данный тезис. Мол, у индусов того времени, возможно, совсем не было письменности.
Однако с этим оказались в корне не согласны индийские программисты, специалисты по искусственному интеллекту, которые создали специальную программу для поиска лингвистических структур в исторических надписях. Перед работой систему натренировали на трёх вербальных языках (современный английский, санскрит, шумерский) и трёх невербальных системах коммуникации (человеческая ДНК, Фортран, протеины бактерий).