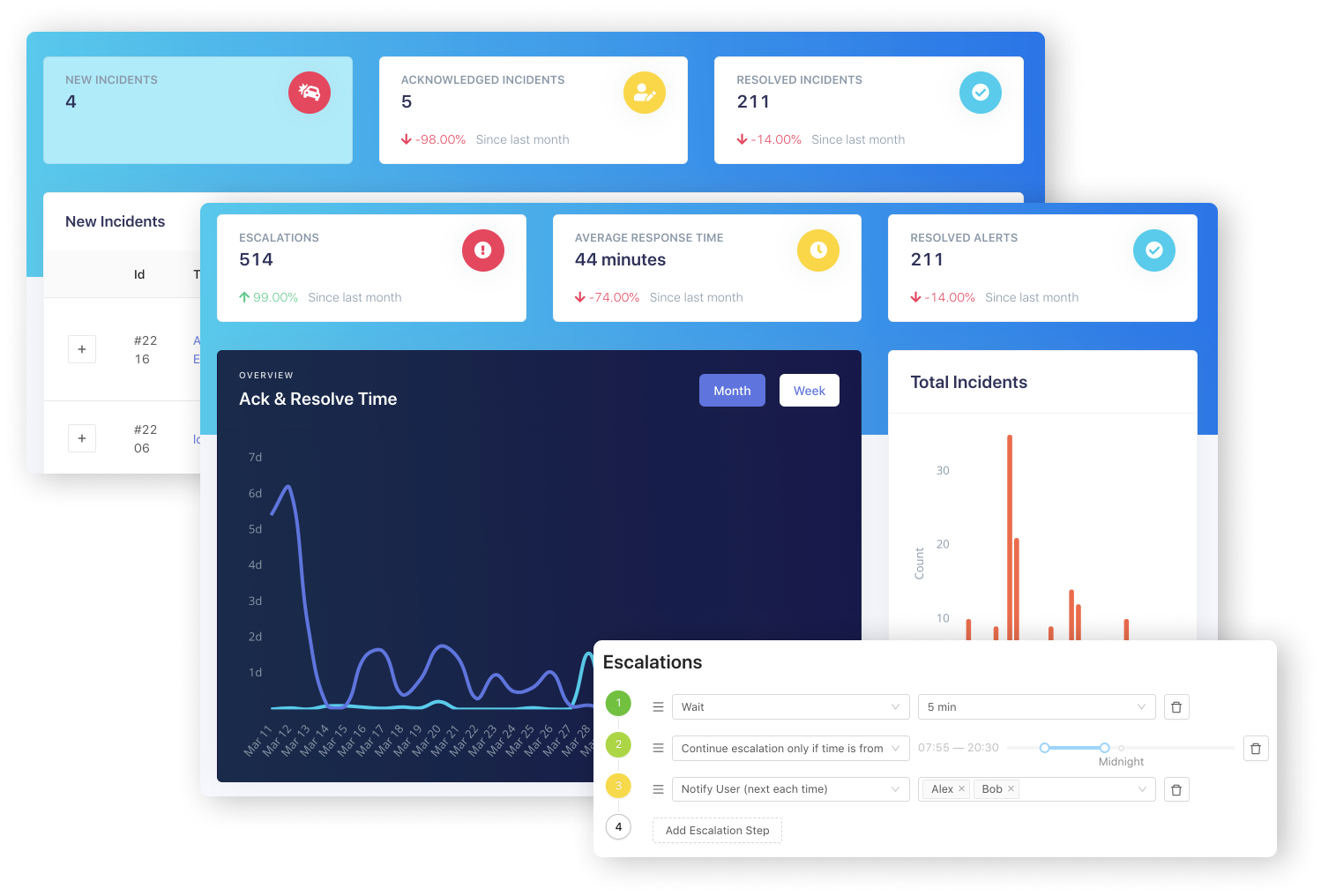
Мы в Dropbox считаем, что управление инцидентами — это центральный элемент нашей системы по обеспечению надёжности. И хотя мы также используем проактивные методы, такие как хаос-инжиниринг (сhaos engineering), то, как мы реагируем на инциденты существенное влияет на опыт наших пользователей. Во время потенциального сбоя сайта или проблемы с продуктом на счету каждая минута.
Ключевые компоненты нашего процесса управления инцидентами существуют уже несколько лет, но мы видим возможности для постоянного развития в этой области. Изменения, которые мы внесли с течением времени, включают в себя как технологические, так и организационные, и процедурные улучшения.
В этом посте мы расскажем подробно о нескольких уроках, которые Dropbox вынесли из опыта управления инцидентами. Вероятнее всего, не каждый из пунктов можно найти в методичке по структуре управления инцидентами, и не стоит думать, что эти улучшения универсальны для любой компании. (Полезность этих уроков зависит от вашего технологического стека, размеров организации и других факторов). Вместо этого мы надеемся, что эта статья послужит примером, как вы можете систематически анализировать реакцию на инциденты в вашей компании и улучшать её так, чтобы удовлетворить потребности ваших пользователей.