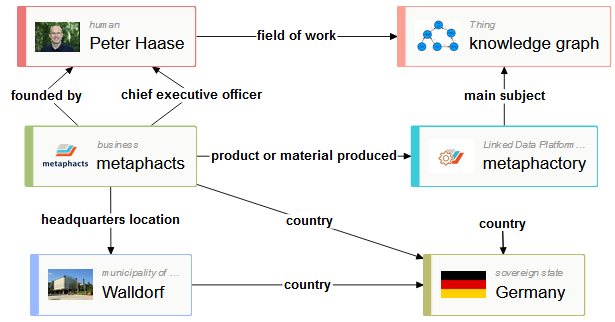
Вальдорфская компания metaphacts, более всего известная проектом ResearchSpace для Британского музея, приобрела петербургскую компанию VISmart, более всего известную библиотекой визуализации графовых данных Ontodia.
Основатель metaphacts Петер Хаазе в прошлом являлся одним из создателей точки доступа SPARQL к «Викиданным»; VISmart была резидентом Технопарка ИТМО. В более узких кругах первая компания известна также сотрудничеством с Siemens, а вторая — с Ленэнерго.
Привет, GT! 2015-й год вот-вот истечёт, все вокруг заняты завершением рабочих дел, бегают в поисках последних подарков и времени ни у кого ни на что не хватает. За последние два месяца накопилось немало новостей, которыми мы хотели бы с вами поделиться!
Под катом вы найдёте самые интересные материалы из области консьюмерских технологий Google за последние два месяца.
В этой публикации я представляю поверхностный обзор статьи от исследователей LinkedIn «Representation Learning in Heterogeneous Professional Social Networks with Ambiguous Social Connections». В указанной статье частично представлена структура графа знаний LinkedIn’s Economic Graph и относительно подробно описан метод обучения эмбеддингов Star2Vec. Я попытаюсь объяснить основные этапы построения векторных представлений, что называется "на пальцах".
Т. к. это лишь поверхностный обзор, от читателя требуются следующие познания:
1. Skip-gram и его адаптация под графы (word2veс, LINE, DeepWalk);
В студии «Финам FM» —Сергей Спивак, генеральный директор группы компаний Internest; Алексей Захаров, президент рекрутингового портала Superjob.ru. Вместе с ведущим, Максимом Спиридоновым, они говорят о новой поисковой технологии, запущенной Google, о необычной инициативе социальной сети «Одноклассники», о крупных инвестициях в социальный сервис Pinterest и о главном событие этой недели для всей Сети – об IPO соцсети Facebook.
Сегодня в русскоязычном блоге компании Google появилась новость о том, что к недавнему нововведению Knowledge Graph добавляется поддержка еще нескольких языков, а именно русского, немецкого, французского, португальского, итальянского, испанского и японского. Представитель компании рассказал, что в течении нескольких недель функционал будет доступен для всех и выдача изменится.
Больше года назад Google объявил, что отныне в их поиске используется таинственная Сеть Знаний (официальный перевод Knowledge Graph). Возможно, не все знают, что значительная часть данных Сети доступна для использования всеми желающими и доступна по прекрасно описанному API. Этой частью является база знаний Freebase, поддерживаемая Google и энтузиастами. В этой статье мы сначала немного подурачимся, а потом попробуем сделать несколько простеньких запросов на языке MQL.
Эта статья — вторая из цикла Базы знаний. Следите за обновлениями.
С декабря 2012 года в компании Google работает знаменитый изобретатель и футуролог Рэй Курцвейл. Это именно тот человек, который дал научное обоснование технологической сингулярности — взрывному научно-техническому процессу, который начнётся после появления мощного искусственного интеллекта (превосходящего человеческий) и киборгизации людей. Согласно закону Мура и экстраполяции, это должно случится примерно в 2045 году.
Google прямой дорогой идёт к технологической сингулярности. По крайней мере, именно Google вместе с НАСА стали главными спонсорами междисциплинарного Университета сингулярности, созданного в 2009 году, да и исследования Google в области роботехники и искусственного интеллекта хорошо соответствуют тому будущему, о котором говорит Курцвейл.
В Google модифицировали свою технологию Knowledge Graph, чтобы предоставлять пользователям при поиске надёжную медицинскую информацию. Обновление, над которым работала команда профессиональных врачей во главе с Капилом Парахом (Kapil Parakh), должно появиться в поисковом движке к концу этой недели. Медицинские факты выбирались только из проверенных источников силами автоматизированной системы и проверялись специалистами клиники Майо — одного из крупнейших частных медицинских центров мира.
Google выпустил API для своей базы знаний Google Knowledge Graph. Сервис уже выдает данные в формате JSON-LD (LD здесь означает Linked Data, да-да!) и использует типы schema.org. Помимо соблюдения стандартов, радостной новостью является наличие обратной совместимости с Freebase — всегда когда возможно, для идентификации сущностей используются ключи из Freebase. Программный интерфейс Freebase будет доступен в течение еще трех месяцев.
Напомню, что Knowledge Graph — это база знаний, которая в числе прочего формирует вот такие вот инфобоксы в результатах поиска:
Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала несколькостатей об инфраструктуре этого графа, который она тщательно выстроила.
Google рассказывала о своём графе знаний, но ничего о внутренней инфраструктуре. Однако в компании тоже есть для него специализированные подсистемы. На самом деле сейчас графу знаний уделяется большое внимание. Лично я поставил на эту лошадку минимум два своих повышения по службе — и начал работу над новым графом ещё в 2010 году.
Хочу представить публике фрагмент вот этой недавно вышедшей книги:
Онтологическое моделирование предприятий: методы и технологии [Текст]: монография / [С. В. Горшков, С. С. Кралин и др.; отв. ред. С. В. Горшков]. — Екатеринбург: Изд-во Уральского ун-та, 2019. — 234 с.: ил., табл.; 20 см. — Авт. указаны на обороте тит. с. — Библиогр. в конце гл. — ISBN 978-5-7996-2580-1: 200 экз.
Обложка и корешок книги
Цель выкладки этого фрагмента на Хабре троякая:
Собрать вопросы и замечания, чтобы учесть их при включении этого текста в переработанном виде в другие издания.
Внести дополнения, не очень совместимые с форматом печатной монографии: злободневные примечания (ниже они под спойлерами) и гиперссылки; а также внести исправления (ниже они никак не выделены).
Многие адепты Semantic Web и Linked Data до сих пор считают, что их круг столь узок в основном потому, что широкой публике все еще по-хорошему не объяснили, что же это такое — Semantic Web и Linked Data. Автор фрагмента, хоть к этому кругу и принадлежит, такого мнения не придерживается, но, тем не менее, считает себя обязанным сделать еще одну попытку.



 С декабря 2012 года в компании Google работает знаменитый изобретатель и футуролог Рэй Курцвейл. Это именно тот человек, который дал научное обоснование технологической сингулярности — взрывному научно-техническому процессу, который начнётся после появления мощного искусственного интеллекта (превосходящего человеческий) и киборгизации людей. Согласно закону Мура и экстраполяции, это должно случится примерно в 2045 году.
С декабря 2012 года в компании Google работает знаменитый изобретатель и футуролог Рэй Курцвейл. Это именно тот человек, который дал научное обоснование технологической сингулярности — взрывному научно-техническому процессу, который начнётся после появления мощного искусственного интеллекта (превосходящего человеческий) и киборгизации людей. Согласно закону Мура и экстраполяции, это должно случится примерно в 2045 году.

 Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала
Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала 