
Если ты ИТшник, то
нельзя просто так взять и выйти на работу 2-го января: пересмотреть 3-ий сезон битвы экстрасенсов или запись программы «Гордон» на НТВ (дело
умственных способностей вкуса).
Нельзя потому, что у других сотрудников обязательно будут для тебя подарки: у секретарши закончился кофе, у МП — закончились дедлайны, а у администратора баз данных —
амнезия память.
Оказалось, что инженеры из команды Hadoop тоже любят побаловать друг друга новогодними сюрпризами.
2008
2 января. Упуская подробное описание эмоционально-психологического состояния лиц, участвующих в описанных ниже событиях, сразу перейду к факту: поставлен таск
MAPREDUCE-279 «Map-Reduce 2.0». Оставив шутки про число, обращу внимание, что до 1-ой стабильной версии Hadoop остается чуть менее 4 лет.
За это время проект Hadoop пройдет эволюцию из маленького инновационного снежка, запущенного в 2005, в большой снежный
com ком, надвигающийся на ИТ, в 2012.
Ниже мы предпримем попытку разобраться, какое же значение январский таск MAPREDUCE-279 играл (и, уверен, еще сыграет в 2013) в эволюции платформы Hadoop.

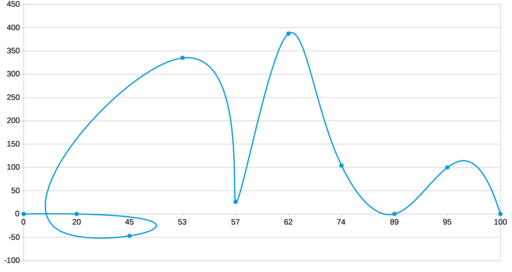




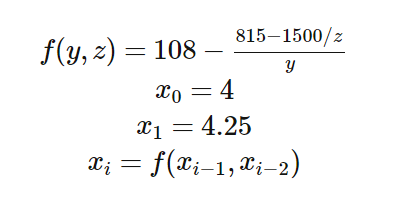


 Когда-то, впервые встретив Unix, я был очарован логической стройностью и завершенностью системы. Несколько лет после этого я яростно изучал устройство ядра и системные вызовы, читая все что удавалось достать. Понемногу мое увлечение сошло на нет, нашлись более насущные дела и вот, начиная с какого-то времени, я стал обнаруживать то одну то другую фичу про которые я раньше не знал. Процесс естественный, однако слишком часто такие казусы обьединяет одно — отсутствие авторитетного источника документации. Часто ответ находится в виде третьего сверху комментария на stackoverflow, часто приходится сводить вместе два-три источника чтобы получить ответ на именно тот вопрос который задавал. Я хочу привести здесь небольшую коллекцию таких плохо документированных особенностей. Ни одна из них не нова, некоторые даже очень не новы, но на каждую я убил в свое время несколько часов и часто до сих пор не знаю систематического описания.
Когда-то, впервые встретив Unix, я был очарован логической стройностью и завершенностью системы. Несколько лет после этого я яростно изучал устройство ядра и системные вызовы, читая все что удавалось достать. Понемногу мое увлечение сошло на нет, нашлись более насущные дела и вот, начиная с какого-то времени, я стал обнаруживать то одну то другую фичу про которые я раньше не знал. Процесс естественный, однако слишком часто такие казусы обьединяет одно — отсутствие авторитетного источника документации. Часто ответ находится в виде третьего сверху комментария на stackoverflow, часто приходится сводить вместе два-три источника чтобы получить ответ на именно тот вопрос который задавал. Я хочу привести здесь небольшую коллекцию таких плохо документированных особенностей. Ни одна из них не нова, некоторые даже очень не новы, но на каждую я убил в свое время несколько часов и часто до сих пор не знаю систематического описания. По обеим сторонам нашего плоского бытия
По обеим сторонам нашего плоского бытия 

 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.

