
Это третья часть переведённых заметок «Good User Interface». Первые 16 частей уже ранее перевели наши коллеги из ADV на Хабре, а вторые 11 перевели мы.
Идея 28
Выбор по-умолчанию или самозаполняющиеся поля с обучением сокращают объем работы, которую должен проделать пользователь. Это стандартная техника, помогающая людям продвигаться по формам быстрее, учитывая, что их время ограничено. Одна из наиболее отвратительных вещей с точки зрения дизайна интерфейсов и конверсии посетителей в клиентов — это снова и снова просить пользователей предоставить данные, которые они уже указали ранее. Старайтесь делать поля, которые будут сами заполняться самыми популярными или уже известными значениями, а не просите людей их каждый раз заполнять. Чем меньше работы — тем лучше.
Идея 28
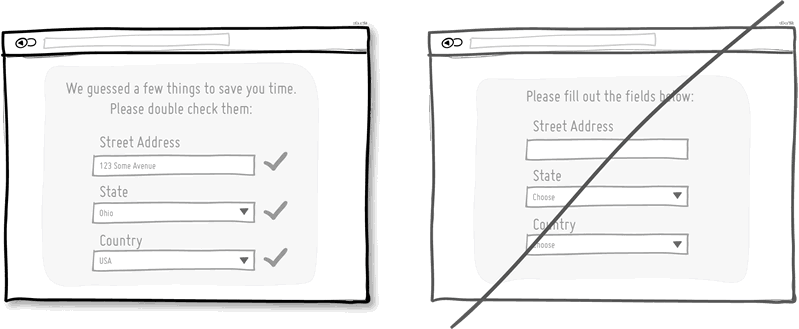
Используйте варианты по-умолчанию, не заставляя людей выбирать
Выбор по-умолчанию или самозаполняющиеся поля с обучением сокращают объем работы, которую должен проделать пользователь. Это стандартная техника, помогающая людям продвигаться по формам быстрее, учитывая, что их время ограничено. Одна из наиболее отвратительных вещей с точки зрения дизайна интерфейсов и конверсии посетителей в клиентов — это снова и снова просить пользователей предоставить данные, которые они уже указали ранее. Старайтесь делать поля, которые будут сами заполняться самыми популярными или уже известными значениями, а не просите людей их каждый раз заполнять. Чем меньше работы — тем лучше.
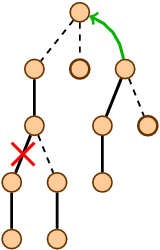 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 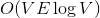 и
и 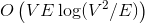 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.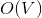 памяти и
памяти и 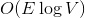 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.

 Самые непристойные и отвратительные наши поступки, выходящие за всякие нормы морали и принципов, обычно начианаются со слов «А почему бы и нет?».
Самые непристойные и отвратительные наши поступки, выходящие за всякие нормы морали и принципов, обычно начианаются со слов «А почему бы и нет?». 






 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.