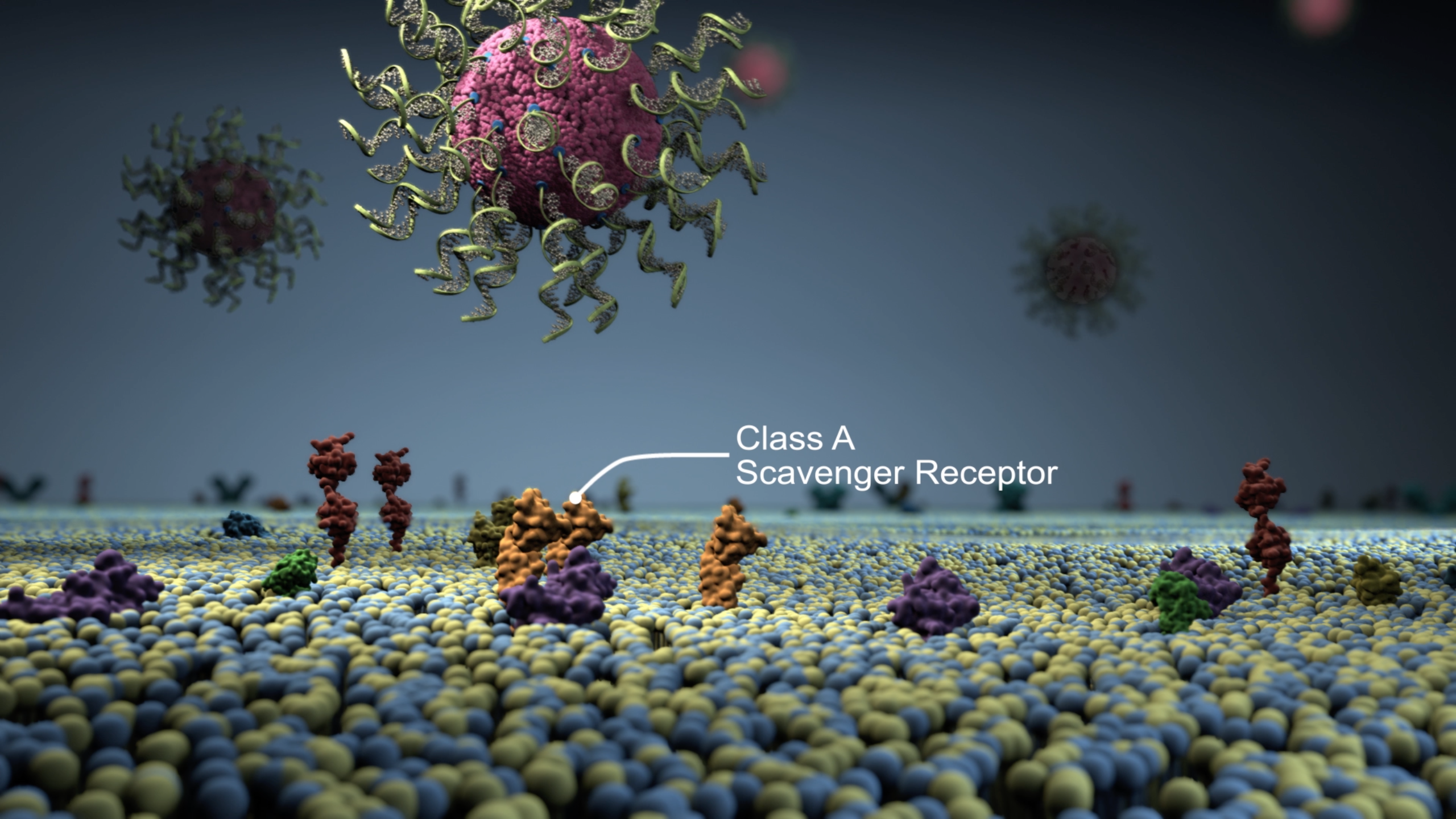
Программист, подписывающийся псевдонимом Fleabit, уже полгода разрабатывает свой язык программирования. Сразу же возникает вопрос: ещё один язык? Зачем?
Вот его аргументы:
- Разработка движка игры и разработка игры на этом движке — две очень разные задачи, и для них удобно использовать разные языки, при условии, что код на них хорошо стыкуется друг с другом. Например, код на языке с garbage collection и на языке с явным управлением памятью было бы сложно объединить в одном проекте.
- Rust идеально подходит для разработки движка игры: из языков, ориентированных на производительность скомпилированного кода, в нём максимум выразительных средств — enum-ы с полями; pattern matching с деструктуризацией; макросы, генерирующие произвольный код во время компиляции; и т.п. С другой стороны, для описания игровой механики Rust подходит плохо: задержки на перекомпиляцию усложняет подход «подправить и тут же проверить, что получилось»; строгое управление памятью усложняет использование одних данных одновременно несколькими объектами; а генераторы/сопрограммы, позволяющие удобно реализовать кооперативную многозадачность между внутриигровыми сущностями, ещё не реализованы.
- Для игровой механики идеально подходил бы скриптовый язык наподобие JavaScript, Lua, Python или Ruby; но интеграция кода на них в проект на Rust — нетривиальная задача, отчасти из-за того, что эти полновесные языки программирования устроены запредельно сложно. Вдобавок, внутри игры напрашивается очень простой garbage collector, отрабатывающий после генерации каждого кадра, чтобы частота кадров оставалась постоянной — без внезапных подвисаний раз в десять минут, когда GC решил пройтись по всем объектам, созданным за эти десять минут. Другое важное преимущество GameLisp перед популярными скриптовыми языками — гомоиконичность, упрощающая обработку и генерацию кода макросами.





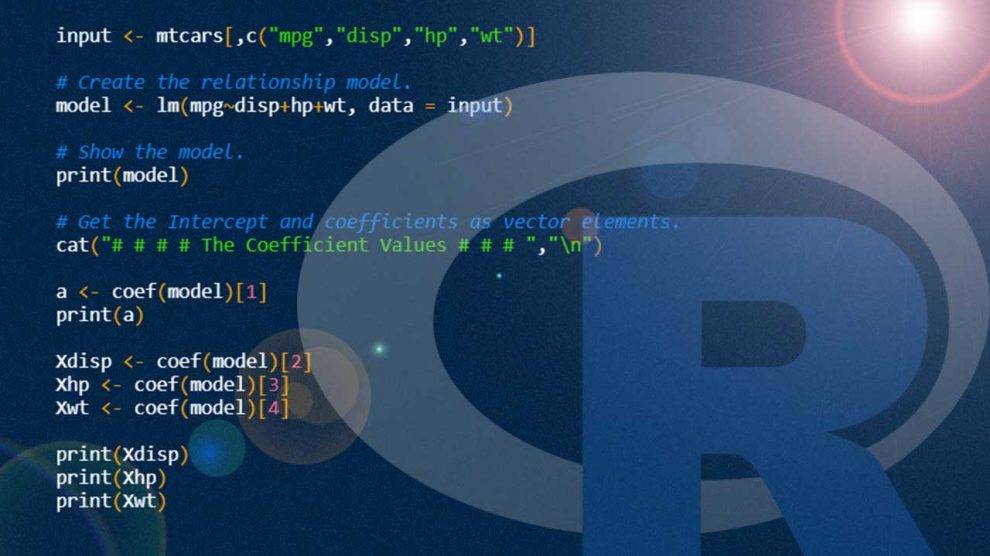

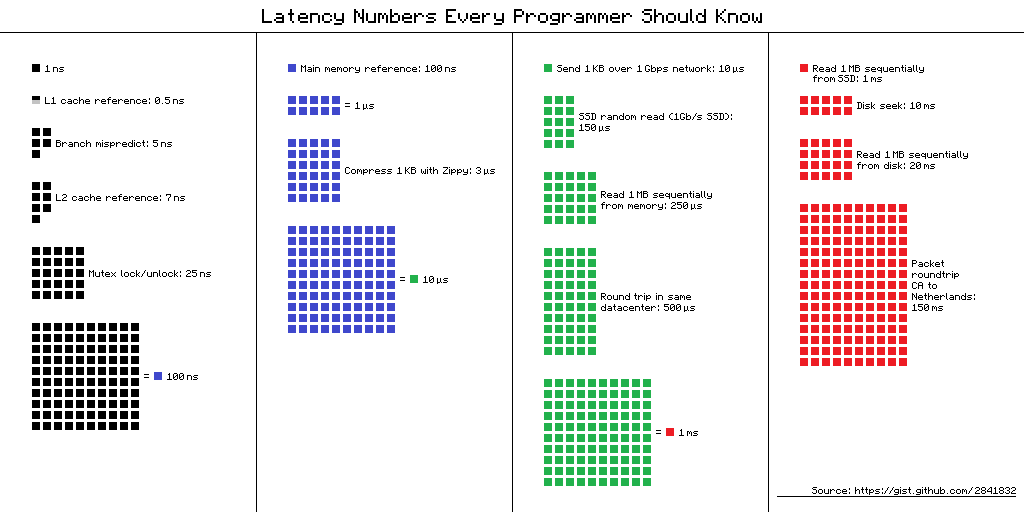



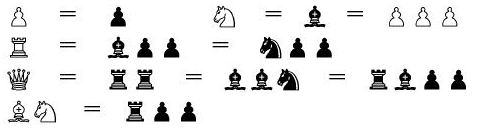 Здравствуй, Хабр!
Здравствуй, Хабр!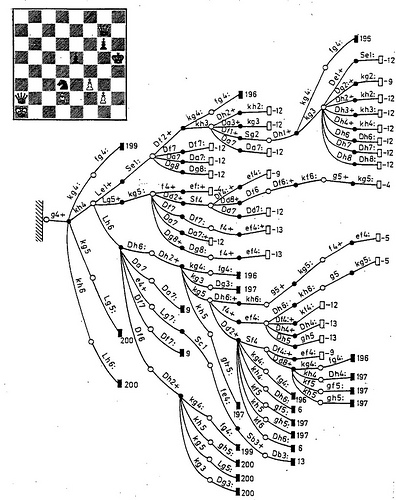

 Разумно было бы предполагать, что для ядра довольно легко будет ничего не делать – но это не так. На конференции
Разумно было бы предполагать, что для ядра довольно легко будет ничего не делать – но это не так. На конференции