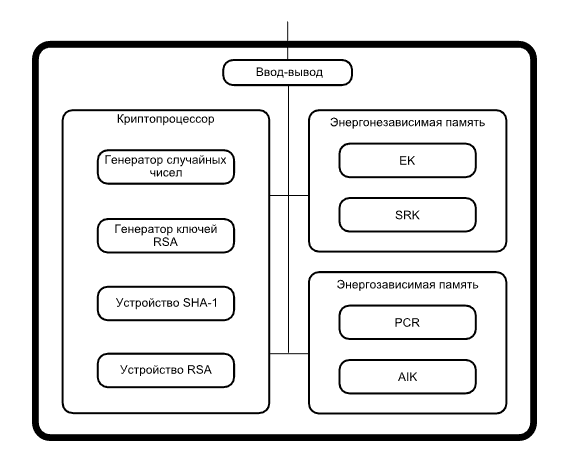
Сигнал SIGSEGV, применяемый в Linux, означает нарушение сегментирования в рамках работающего процесса. Ошибки сегментирования возникают из-за того, что программа пытается обратиться к участку памяти, который пока не выделен. Это может произойти из-за бага, случайно вкравшегося в код, либо из-за того, что внутри системы происходит некая вредоносная активность.
Сигналы SIGSEGV возникают на уровне операционной системы, но столкнуться с ними также вполне можно и в контексте контейнерных технологий, например, Docker и
Kubernetes. Когда контейнер завершает работу, выдав код возврата 139, дело именно в том, что он получил сигнал SIGSEGV. Операционная система завершает процесс контейнера, чтобы предохраниться от нарушения целостности памяти.
Если ваши контейнеры то и дело завершают работу с кодом возврата, то важно исследовать, что именно вызывает ошибки сегментирования. Часто следы ведут к программным ошибкам в языках, открывающих вам прямой доступ к памяти. Если такая ошибка возникает в том контейнере, где выполняется сторонний образ, то виной тому может быть баг в стороннем софте или несовместимость образа со средой.
В этой статье будет объяснено, что представляют собой сигналы SIGSEGV, как они влияют на работу ваших контейнеров с Linux в Kubernetes. Также я подскажу, как отлаживать ошибки сегментации в вашем приложении, а если они возникают – как с ними справляться.