
От переводчика
С удовольствием ознакомился с этими рекомендациями и теперь предлагаю вам перевод.
Введение
Это руководство описывает правила для оформления и форматирования HTML и CSS кода. Его цель — повысить качество кода и облегчить совместную работу и поддержку инфраструктуры.
Это относится к рабочим версиям файлов использующих HTML, CSS и GSS
Разрешается использовать любые инструменты для минификации компиляции или обфускации кода, при условии, что общее качество кода будет сохранено.


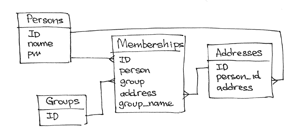 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
