В предыдущих сериях (FAQ • 1 • 2 • 3 • 4 • 5 ) мы весьма подробно рассмотрели, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL поверх Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
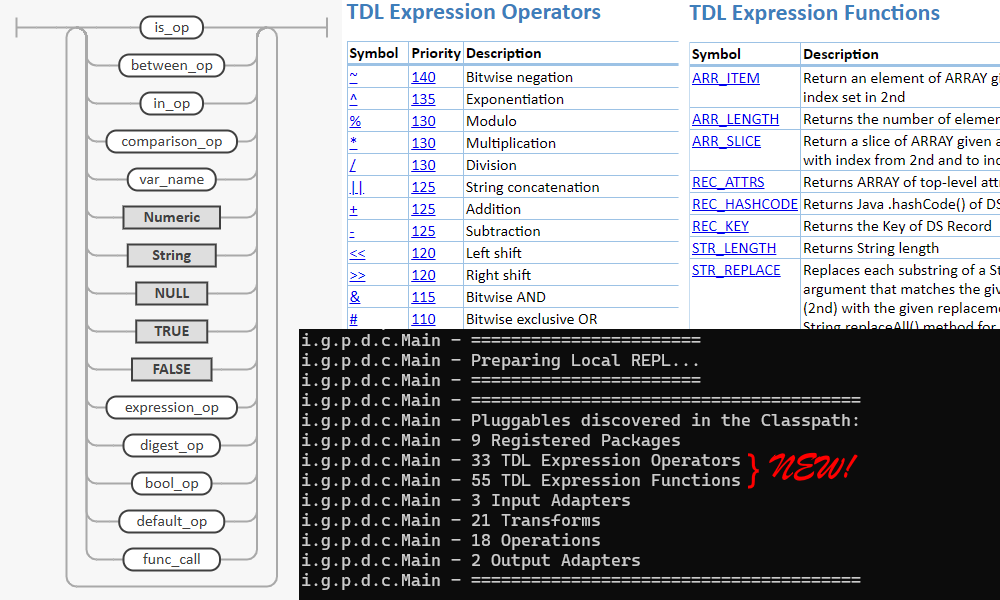
В данной части поговорим о том, как добавить в выражения SQL поддержку функций. Например,
SELECT
MAX(score1, score2, score3, score4, score5) AS max_score,
MIN(score1, score2, score3, score4, score5) AS min_score,
MEDIAN(score1, score2, score3, score4, score5) AS median_score,
score1 + score2 + score3 + score4 + score5 AS score_sum
FROM raw_scores INTO final_scores
WHERE ABS(score1 + score2 + score3 + score4 + score5) > $score_margin;— тут у нас функции MAX, MIN и MEDIAN принимают любое количество аргументов типа Double и возвращают Double, а ABS только один такой аргумент.
Вообще, кроме общей математики, в любом уважающем себя диалекте SQL как минимум должны быть функции для манипуляций с датой/временем, работы со строками и массивами. Их мы тоже обязательно добавим. В classpath, чтобы движок мог их оттуда подгружать. До кучи, ещё и операторы типа >= или LIKE, которые у нас уже были реализованы, но хардкодом, сделаем такими же подключаемыми.
Уровень сложности данной серии статей в целом высокий. Базовые понятия в тексте совсем не объясняются, да и продвинутые далеко не все. Однако, эта часть несколько проще для ознакомления, чем предыдущие. Но всё равно, понимать её будет легче, если вы уже пробежались по остальным хотя бы по диагонали.