

Недавно мне довелось поработать над приложением, которое должно было контролировать скорость своих исходящих подключений. Например, подключаясь к одному URL приложение должно было ограничить себя, скажем, 200KiB/sec. А подключаясь к другому URL — всего 30KiB/sec.
Самым интересным моментом здесь оказалось тестирование этих самых ограничений. Мне потребовался HTTP-сервер, который бы отдавал трафик с какой-то заданной скоростью, например, 512KiB/sec. Тогда бы я мог видеть, действительно ли приложение выдерживает скорость 200KiB/sec или же оно срывается на более высокие скорости.
Но где взять такой HTTP-сервер?
Поскольку я имею некоторое отношение к встраиваемому в С++ приложения HTTP-серверу RESTinio, то не придумал ничего лучше, чем быстренько набросать на коленке простой тестовый HTTP-сервер, который способен отдавать клиенту длинный поток исходящих данных.
О том, насколько это было просто и хотелось бы рассказать в статье. Заодно узнать в комментариях, действительно ли это просто или же я сам себя обманываю. В принципе, данную статью можно рассматривать как продолжение предыдущей статьи про RESTinio под названием "RESTinio — это асинхронный HTTP-сервер. Асинхронный". Посему, если кому-то интересно прочитать о реальном, пусть и не очень серьезном применении RESTinio, то милости прошу под кат.
 «Закон масштабирования Деннарда и закон Мура мертвы, что теперь?» — пьеса в четырёх действиях от Дэвида Паттерсона
«Закон масштабирования Деннарда и закон Мура мертвы, что теперь?» — пьеса в четырёх действиях от Дэвида Паттерсона







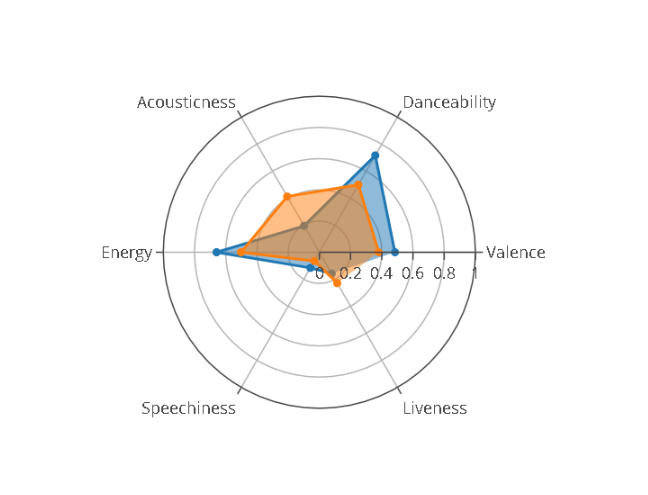
 Если в
Если в  Тема префиксных деревьев поиска уже неколько раз поднималась на хабре.
Тема префиксных деревьев поиска уже неколько раз поднималась на хабре. 