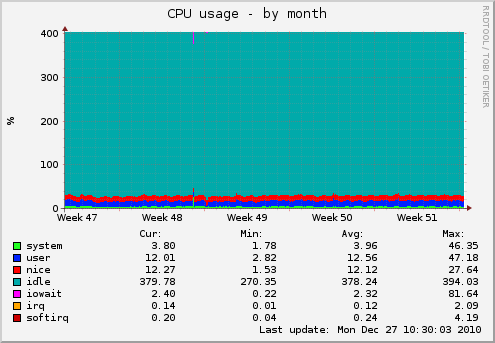
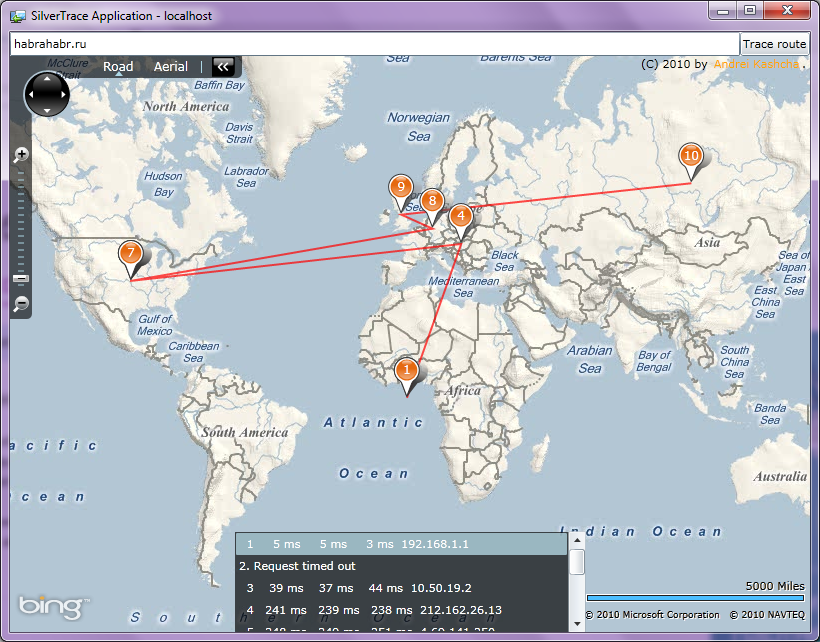
Недавно, в сети появилась статистика от Y Combinator того, где хостятся стартапы.
Недавно, в сети появилась статистика от Y Combinator того, где хостятся стартапы.Где хостятся стартапы
1 min
Недавно, в сети появилась статистика от Y Combinator того, где хостятся стартапы.
программист, синьор-помидор :)
Недавно, в сети появилась статистика от Y Combinator того, где хостятся стартапы.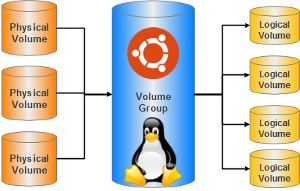 Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.

11:24:21 PM Michael: ну хз, надо пробовать 11:24:24 PM Michael: наверное так лучше 11:24:27 PM Michael: даже я думаю наверняка 11:24:36 PM Michael: но пока меня че-то останавливает 11:24:38 PM Michael: лень наверное :)

var image = $("<img>", {
src: image_url,
alt: image_description,
className: "translucent_image",
click: function() {$(this).css("opacity", "50%");}
});