paper link
hf implementation
Для ответа на вопрос в заголовке - погрузимся в статью.
Саммари статьи:
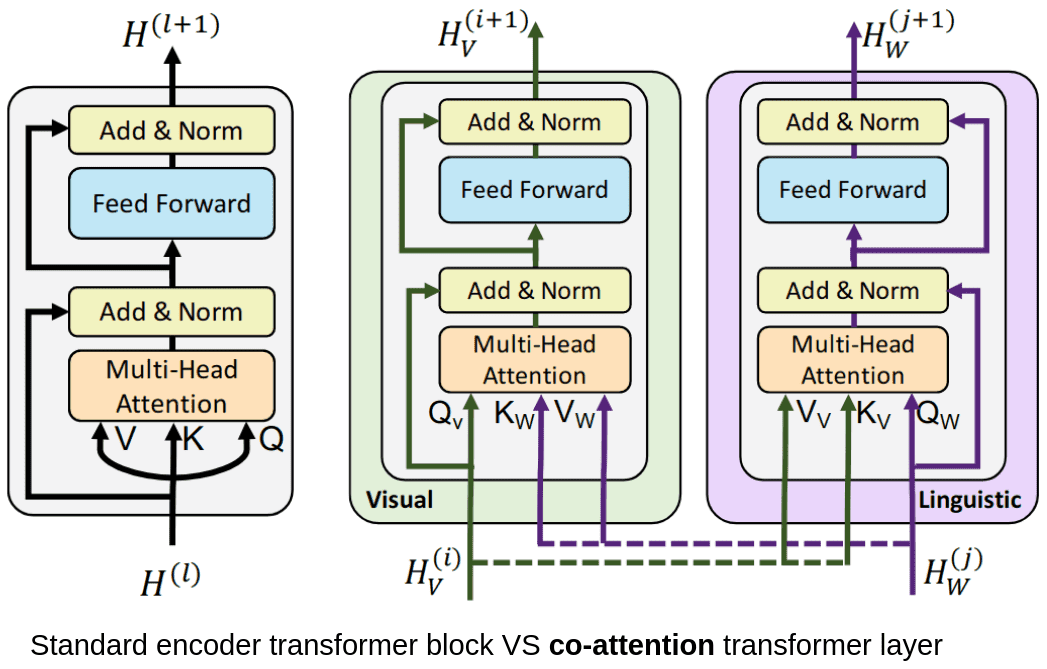
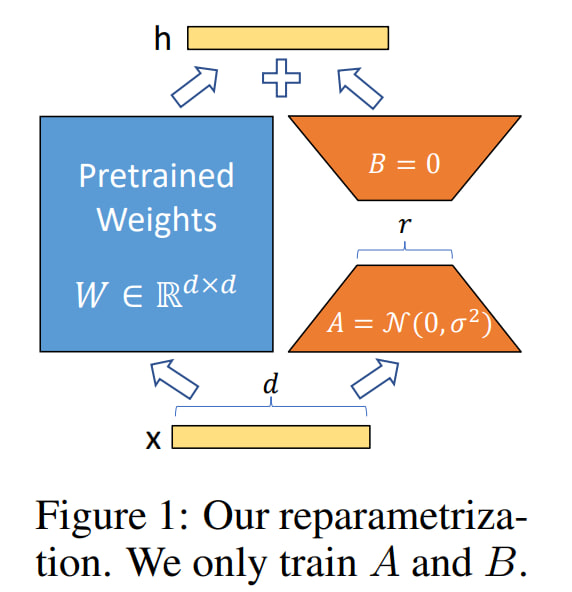
Обычно LLM-ку предобучают на огромном корпусе, потом адаптируют на down-stream tasks. Если LLM-ка была большая, то мы не всегда можем в full fine-tuning. Авторы статьи предлагают Low-Rank Adaptation (LoRA), который замораживает предобученные веса модели и встраивает "rank decomposition matrices" в каждый слой трансформера, очень сильно понижая кол-во обучаемых параметров для downstream tasks.
Compared to GPT-3 175B fine‑tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on‑par or better than finetuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.
Многие NLP-приложения требуют решения разных задач, что зачастую достигается путем дообучения большой модели на несколько разных downstream tasks. Самая важная проблема в классическом fine-tuning'е - новая модель содержит столько же параметров, сколько начальная.
Есть работы, где авторы адаптируют только некоторые параметры или обучают внешний модуль для каждой новой задачи. Таким образом, нам необходимо для каждой новой задачи хранить лишь веса, связанные с этой задачей. Однако, имеющиеся методы страдают от:
Inference latency (paper 1 - Parameter-Efficient Transfer Learning for NLP).
Reduced model's usable sequence length (paper 2 - Prefix-Tuning: Optimizing Continuous Prompts for Generation).
Часто не достигают бейзлайнов, если сравнивать с "классическим" fine-tuning'ом