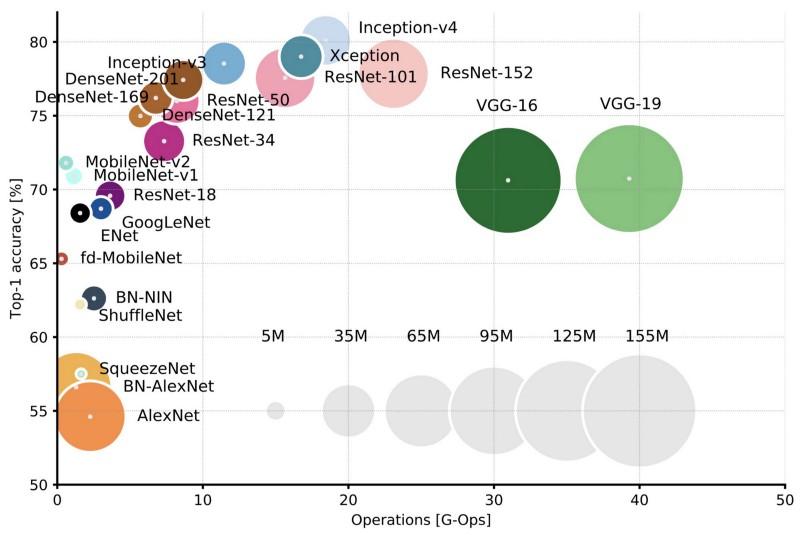
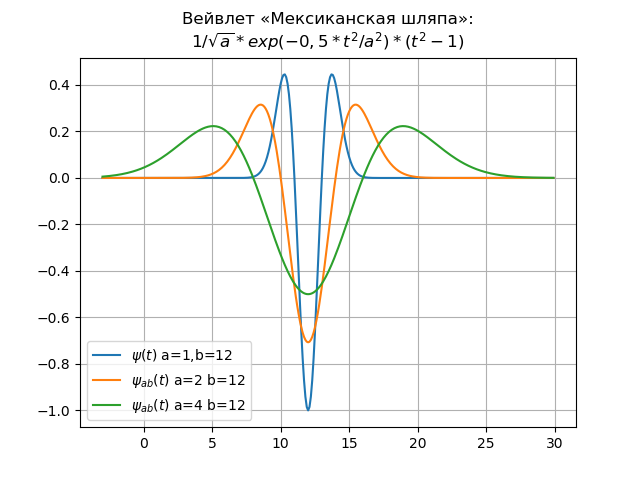
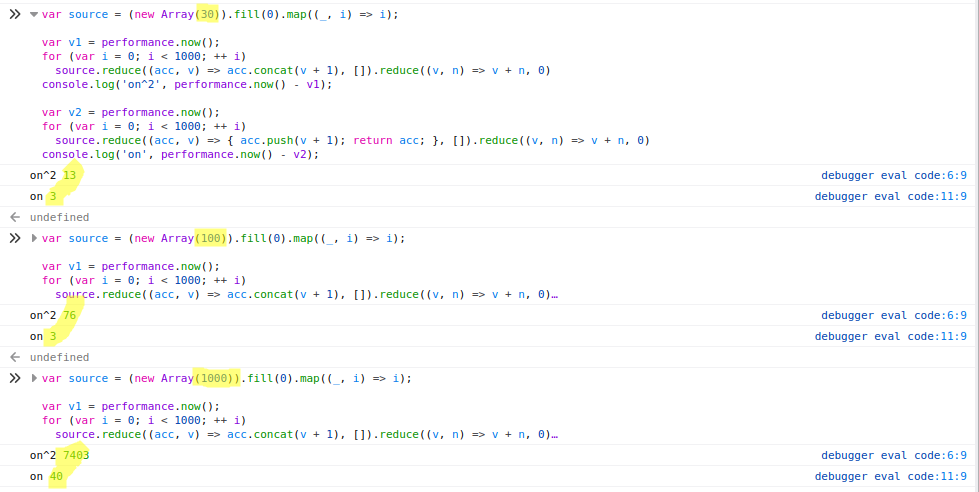
В популярных фреймворках машинного обучения TensorFlow и PyTorch при инициализации весов нейросети используются случайные числа. В этой статье мы попытаемся разобраться, почему для этих целей не используют ноль или какую-нибудь константу.
Кто хочет быстрый и короткий ответ на этот вопрос, вот он: если инициализировать веса нулями, то нейросеть может не обучаться совсем или обучаться плохо.
Кто хочет более развёрнуто узнать, что значит «плохо», может просто перемотать к заключению в конце статьи.
А тем, кто хочет в деталях разобраться с основами обучения нейронных сетей, добро пожаловать в мир математических формул. Мы детально разберём, из-за чего в механизме обучения может произойти «сбой».








 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но