Internet Explorer 8, как много в этом имени для рядового веб-разработчика :-) Браузер, который с одной стороны до сих пор удерживает значительную часть рынка (а значит не может быть просто так проигнорирован), а с другой — обладает тяжелым наследием IE6 в виде массы «особенностей» поведения и отсутствием поддержки целого ряда новых и вкусных технологий которые так хочется использовать. Эта двойственность породила целый ряд т.н. polyfills — JS скриптов которые призваны хоть немного подтянуть IE6-8 до уровня современных браузеров. Об одном из них и пойдет речь в данной статье.

KAndy @KAndy
User
Шаблонизация в JavaScript с использованием Razor
5 min
В силу всё большего и большего усложнения веб-приложений на стороне клиента, хочется иметь шаблонизаторы, которые работали бы прямо на клиенте. И таких средств, надо сказать, появилось не мало. Но так как я легких путей не ищу все они мне не нравятся, я решил сделать свой с блэкджеком и дамами лёгкого поведения (я так понял, на Хабре жестко карают и банят, если этой фразы нет в посте).
И вот я решил создать строготипизированный шаблонизатор на Razor.
И вот я решил создать строготипизированный шаблонизатор на Razor.
Как стать Zend PHP 5 Certified Engineer
3 min
Свершилось, ура! Теперь я имею почетный статус ZCE :)
Поэтому хотел бы поделиться своим опытом подготовки к сертификации, ну и заодно провести небольшой ликбез на тему сертификации по PHP.
Поэтому хотел бы поделиться своим опытом подготовки к сертификации, ну и заодно провести небольшой ликбез на тему сертификации по PHP.
Плоский GeoIP или диапазон в одной колонке
4 min
В опубликованной накануне (февраль, 2012) статье озаглавленной «Определение страны по IP: тестируем скорость алгоритмов» сравнивались реализации на уровне БД и нативной реализации. Мы же предлагаем рассмотреть ещё более оптимальный и простой алгоритм, который может быть реализован как в БД, так и в нативном варианте – плоские диапазоны.
Unity3d. Уроки от Unity 3D Student (B00-B03)
5 min
Добрый день. Предлагаю свой вариант перевода уроков по Unity3d от www.unity3dstudent.com
Данная статья представляет из себя первый набор базовых (из раздела Beginner) уроков. Уроки в основном нацелены на изучение скриптинга и использование компонентов.
Поэтому предполагается, что с основами работы в GUI Unity вы слегка знакомы. Если нет, изучите вводный раздел на этом же сайте.
Уроки достаточно ясные и короткие, так что трудностей в процессе их изучения должно возникать минимум.
PS: А хорошо это или плохо — вопрос достаточно сложный.
В некоторых местах уроков есть минимальные косметические изменения, не затрагивающие основную суть.
Введение.
Данная статья представляет из себя первый набор базовых (из раздела Beginner) уроков. Уроки в основном нацелены на изучение скриптинга и использование компонентов.
Поэтому предполагается, что с основами работы в GUI Unity вы слегка знакомы. Если нет, изучите вводный раздел на этом же сайте.
Уроки достаточно ясные и короткие, так что трудностей в процессе их изучения должно возникать минимум.
PS: А хорошо это или плохо — вопрос достаточно сложный.
В некоторых местах уроков есть минимальные косметические изменения, не затрагивающие основную суть.
Интерактивная визуализация данных Envision.js
1 min
Envision.js библиотека для создания быстрых динамических и интерактивных визуализаций данных на HTML5.
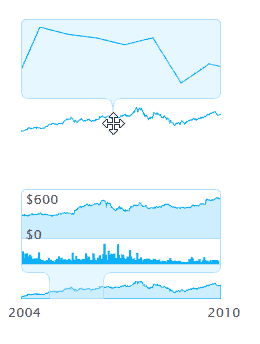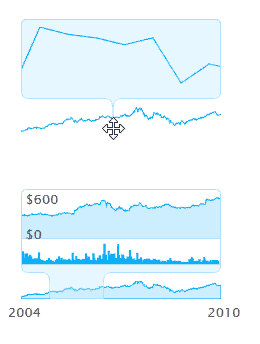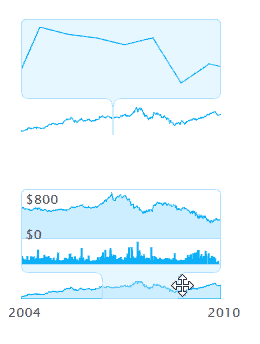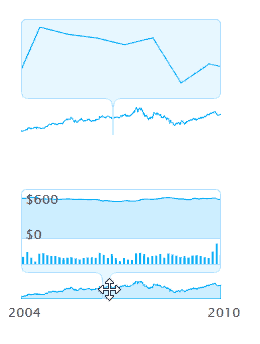
Возможности:
1) Визуализация в реальном времени.
2) Временная шкала
3) Визуализация валют ( как на яндексе прям )
4) Поддержка Ajax в интерактиве.
5) Можно побаловаться фракталами.
Возможности:
1) Визуализация в реальном времени.
2) Временная шкала
3) Визуализация валют ( как на яндексе прям )
4) Поддержка Ajax в интерактиве.
5) Можно побаловаться фракталами.
Использование ShtumiUsefulBundle в Symfony2 — несколько полезных вещей в одном бандле
7 min
Разрабатывая проекты на базе нового, но уже ставшего очень популярным фреймворка Symfony2 невольно сталкиваешься с кусками кода, которые с минимальными изменениями, а то и вовсе без них кочуют из одного проекта в другой. Собрав несколько таких «кусков» воедино я создал ShtumiUsefulBundle, об использовании которого хочу рассказать.
Система мониторинга мнений методом поточечной взаимной информации
4 min
Здравствуйте.
Если вы занимаетесь DataMining, анализом текстов на выявление мнений или вам просто интересны статистические модели для оценки эмоциональной окраски предложений — эта статья может оказаться интересной.
Далее, чтобы не тратить время потенциального читателя впустую на груду теории и рассуждений, сразу краткие результаты.
Реализованный подход работает приблизительно с 55% точностью в трех классах: негативный, нейтральный, позитивный. Как говорит Википедия, 70% точность приблизительно равна точности человеческих суждений в среднем (в силу субъективности трактований каждого).
Следует отметить, что существует немало утилит с точностью выше полученной мной, но описанный подход, можно достаточно просто усовершенствовать (будет описано ниже) и получить в итоге 65-70%. Если после всего вышеизложенного у вас осталось желание читать — добро пожаловать под кат.
Если вы занимаетесь DataMining, анализом текстов на выявление мнений или вам просто интересны статистические модели для оценки эмоциональной окраски предложений — эта статья может оказаться интересной.
Далее, чтобы не тратить время потенциального читателя впустую на груду теории и рассуждений, сразу краткие результаты.
Реализованный подход работает приблизительно с 55% точностью в трех классах: негативный, нейтральный, позитивный. Как говорит Википедия, 70% точность приблизительно равна точности человеческих суждений в среднем (в силу субъективности трактований каждого).
Следует отметить, что существует немало утилит с точностью выше полученной мной, но описанный подход, можно достаточно просто усовершенствовать (будет описано ниже) и получить в итоге 65-70%. Если после всего вышеизложенного у вас осталось желание читать — добро пожаловать под кат.
Фильтр Калмана — Введение
5 min
Фильтр Калмана — это, наверное, самый популярный алгоритм фильтрации, используемый во многих областях науки и техники. Благодаря своей простоте и эффективности его можно встретить в GPS-приемниках, обработчиках показаний датчиков, при реализации систем управления и т.д.
Про фильтр Калмана в интернете есть очень много статей и книг (в основном на английском), но у этих статей довольно большой порог вхождения, остается много туманных мест, хотя на самом деле это очень ясный и прозрачный алгоритм. Я попробую рассказать о нем простым языком, с постепенным нарастанием сложности.
Про фильтр Калмана в интернете есть очень много статей и книг (в основном на английском), но у этих статей довольно большой порог вхождения, остается много туманных мест, хотя на самом деле это очень ясный и прозрачный алгоритм. Я попробую рассказать о нем простым языком, с постепенным нарастанием сложности.
Шустрый 128-битный LFSR (MMX required)
4 min
Случайные числа — темная лошадка обеспечения механизмов безопасности в цифровой среде. Незаслуженно оставаясь в тени криптографических примитивов, они в то же время являются ключевым элементом для генерации сессионных ключей, применяются в численных методах Монте-Карло, в имитационном моделировании и даже для проверки теорий формирования циклонов!
При этом от качества реализации самого генератора псевдослучайных чисел зависит и качество результирующей последовательности. Как говорится: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».

Вариантов реализации генератора псевдослучайных чисел достаточно много: Yarrow, использующий традиционные криптопримитивы, такие как AES-256, SHA-1, MD5; интерфейс CryptoAPI от Microsoft; экзотичные Chaos и PRAND и другие.
Но цель этой заметки иная. Здесь я хочу рассмотреть особенность практической реализации одного весьма популярного генератора псевдослучайных чисел, широко используемого к примеру в Unix среде в псевдоустройстве /dev/random, а также в электронике и при создании потоковых шифров. Речь пойдёт об LFSR (Linear Feedback Shift Register).
Дело в том, что есть мнение, будто в случае использования плотных многочленов, состояния регистра LFSR очень медленно просчитываются. Но как мне видится, зачастую проблема не в самом алгоритме (хотя и он конечно не идеал), а в его реализации.
При этом от качества реализации самого генератора псевдослучайных чисел зависит и качество результирующей последовательности. Как говорится: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».
Вариантов реализации генератора псевдослучайных чисел достаточно много: Yarrow, использующий традиционные криптопримитивы, такие как AES-256, SHA-1, MD5; интерфейс CryptoAPI от Microsoft; экзотичные Chaos и PRAND и другие.
Но цель этой заметки иная. Здесь я хочу рассмотреть особенность практической реализации одного весьма популярного генератора псевдослучайных чисел, широко используемого к примеру в Unix среде в псевдоустройстве /dev/random, а также в электронике и при создании потоковых шифров. Речь пойдёт об LFSR (Linear Feedback Shift Register).
Дело в том, что есть мнение, будто в случае использования плотных многочленов, состояния регистра LFSR очень медленно просчитываются. Но как мне видится, зачастую проблема не в самом алгоритме (хотя и он конечно не идеал), а в его реализации.
Новый aggregation framework в MongoDB 2.1
12 min
В релизе 2.1 было заявлена реализация такой функциональности, как новый фреймворк агрегирования данных. Хотелось бы рассказать о первых впечатлениях от этой весьма интересной штуки. Данный функционал должен позволить в некоторых местах отказаться от Map/Reduce и написания кода на JavaScript в пользу достаточно простых конструкций, предназначенных для группировки полей почти как в SQL.
Connect 2 — Новые дополнения, улучшения и документация!
4 min

Не так давно, а именно 2011-10-05 вышла новая версия фреймворка connect 2.0. На хабре был замечен пробел, а тут выдалось пару свободных часов. Буду писать сразу про версию 2.0.1 вышедшую 29 февраля. Во второй версии сделали много очень нужных и долгожданных изменений.
Анализ случайных последовательностей с помощью простых графических тестов
4 min
Аннотация
Данная статья содержит описание метода графического тестирования случайных последовательностей, на соответствия критериям истинно случайным последовательностям. В статье приводиться обзор метода «Приблизительной энтропии» входящего в состав пакета тестирования NIST, также приводятся сравнительный анализ последовательностей полученных при помощи ГПСЧ описанных в статье Ocelot Генерация случайных чисел на микроконтроллерах.
Использование TPL Dataflow для многопоточной компрессии файлов
4 min
На небольшом примере я расскажу как используя библиотеку TPL Dataflow можно решить довольно не тривиальную задачу многопоточной компрессии файлов в течении 15 минут.
Равномерное выравнивание блоков по ширине
4 min
Продолжая свои «css-раскопки» возникла новая идея, разобрать по косточкам ещё одну актуальную тему, которая касается равномерного выравнивания блоков по ширине. В принципе мои доскональные исследования я уже запостил у себя в блоге, но так как прошлая моя работа очень понравились Хабра-сообществу, то я решил сделать здесь небольшой краткий обзорчик этой статьи, чтобы ни одна хабра-душа не пропустили её наверняка. Так что, как говорил Гагарин: «Поехали».
В общем в задачах вёрстки периодически возникают моменты, когда появляется необходимость выровнять какой-нибудь список по ширине экрана. При этом пункты этого списка должны выравниваться равномерно, прижимаясь своими крайними элементами к границам контейнера, а расстояние между ними должно быть одинаковым.

В общем в задачах вёрстки периодически возникают моменты, когда появляется необходимость выровнять какой-нибудь список по ширине экрана. При этом пункты этого списка должны выравниваться равномерно, прижимаясь своими крайними элементами к границам контейнера, а расстояние между ними должно быть одинаковым.
Почти кроссбраузерный beforeprint
3 min
Для Internet Explorer впервые реализовали события beforeprint и afterprint, и долгое время он был единственным, кто их поддерживает. Затем подтянулась Mozilla, поддерживающая эти события с 6-ой версии своего браузера. Вебкит очень долго не решался на реализацию, и наконец полностью от неё отказался, отсылая нас к интерфейсу matchMedia. Опера, насколько автор смог разобраться, не реализовала ни события, ни matchMedia, хотя не исключено недостаточное гугление этого вопроса.
На основании всего вышеизложенного хочется поделиться с читателями простым плагином jQuery, который добавляет поддержку методов beforeprint и afterprint.
На основании всего вышеизложенного хочется поделиться с читателями простым плагином jQuery, который добавляет поддержку методов beforeprint и afterprint.
Оптимизация ORDER BY — о чем многие забывают
2 min
На тему оптимизации MySQL запросов написано очень много, все знают как оптимизировать SELECT, INSERT, что нужно джоинить по ключу и т.д. и т.п.
Но есть один момент, тоже неоднократно описанный во всех мануалах, но почему-то про него все забывают.
Но есть один момент, тоже неоднократно описанный во всех мануалах, но почему-то про него все забывают.
Алгоритм Ляна-Кнута для расстановки мягких переносов
4 min
При работе с текстом часто возникает потребность корректно расставить переносы. Задача на первый взгляд не такая уж очевидная, нужно учитывать особенности каждого языка, чтобы решить, в каком месте разорвать слово. Как правильно формализовать такие требования, и как потом применить их в алгоритме? Одно из самых распространенных на сей день решений предложил Франклин Марк Лян, студент известного профессора Дональда Кнута. Алгоритм так и называется – «Алгоритм Ляна-Кнута», он применяется в издательской системе TeX, автор которой опять же Д. Кнут.
Алгоритм основан на сравнении исходного слова с набором правил (шаблонов). Чем больше правил и чем качественнее они составлены, тем лучше будут расставляться переносы. В пакете TeX можно найти готовые бесплатные наборы правил для многих языков, нужно только внимательно смотреть на условия использования и распространения.
Алгоритм основан на сравнении исходного слова с набором правил (шаблонов). Чем больше правил и чем качественнее они составлены, тем лучше будут расставляться переносы. В пакете TeX можно найти готовые бесплатные наборы правил для многих языков, нужно только внимательно смотреть на условия использования и распространения.
Пара вопросов на несколько экранов. (.NET)
9 min
Пролог
Вряд ли эта статья войдёт в чьё-то избранное, так как статьёй как таковой и не является. Здесь нет никакого сборника мудростей для новичков. Здесь нет ни строчки кода. Здесь нет картинок для привлечения внимания. Скорее, этот пост — это вопросы и мысли вслух простого программиста аутсорсинговой компании. Потому и будет чем-то напоминать порезанный и склееный воедино диалог (ну, в данном случае, скорее, монолог) из курилки в офисе IT компании. Вероятно, на многие вопросы мне смогут ответить те разработчики, которые очень хорошо знакомы с .NET CMS Orchard и Umbraco. Хотелось бы на всякий случай воззвать к вашей интеллигентности — не устраивайте здесь священные войны, пожалуйста. Вы ведь уже давно сами поняли, что плюсы и минусы есть везде и, более того, при существовании двух популярных решений на одну проблему, их отношение приблизительно равно единице. Также, хотелось бы попросить прощения за получившееся полотенце.
MySQL в NGINX: использование блокирующих библиотек в неблокирующем сервере
7 min
Как известно, при разработке высоконагруженных серверов часто применяется событийная модель работы с сокетами. Ключевым компонентом системы при этом является epoll (во FreeBSD и Windows есть свои решения, но остановимся на Линуксе). Функция epoll_wait, будучи единственным блокирующим вызовом, возвращает нам информацию обо всех сетевых событиях, которые нас интересуют. Подобным образом, конечно, работает и всем известный сервер NGINX.
Событийная модель программирования делает код весьма своеобразным, как будто выворачивает его наизнанку. Но эта проблема не так страшна. Есть другая проблема — использование в событийно-ориентированном коде существующих библиотек, изначально не предназначенных для него. Если подобная библиотека делает блокирующие вызовы (например, connect, recv и т.д.), вся событийная модель может потерять смысл т.к. окончания одного такого вызова будут ждать все остальные клиенты, что совершенно неприемлемо, если вы пишете серьезный продукт.
Событийная модель программирования делает код весьма своеобразным, как будто выворачивает его наизнанку. Но эта проблема не так страшна. Есть другая проблема — использование в событийно-ориентированном коде существующих библиотек, изначально не предназначенных для него. Если подобная библиотека делает блокирующие вызовы (например, connect, recv и т.д.), вся событийная модель может потерять смысл т.к. окончания одного такого вызова будут ждать все остальные клиенты, что совершенно неприемлемо, если вы пишете серьезный продукт.