Как уважаемые хабровчане знают, вот уже почти год мы разрабатываем маленький компьютер (примерно с SD-карточку), работающий под OpenWRT, со встроенным Wi-Fi, USB, Ethernet, азартными играми и доступными женщинами. Дмитрий
dzhe уже несколько раз
писал про него — и, в общем, с каждым разом собирал в комментариях один и тот же вопрос: а зачем вы вообще его делаете? Ну ведь есть же Raspberry Pi, стоит он столько же, есть VoCore, Carambola, Edison, в конце концов, — зачем нужен ещё один «нанокомпьютер»?
Пожалуй, надо наконец на этот вопрос ответить — заодно отметив этим ответом появление у нас своего корпоративного блога (спасибо, Хабр!), а также запуск
отдельного веб-сайта, посвященного только этому проекту.

Если коротко: хотя изначально проект начинался как «а не сделать ли нам нанокомпьютер как у китайцев, но для себя и подешевле?», мотивация довольно быстро сместилась — мы поняли, что можем сделать его если не дешевле, то лучше и удобнее, и не только для себя.





 Сегодня я хотел бы выступить в необычном для хаба Arduino качестве и рассказать не об устройстве, а о библиотеке.
Сегодня я хотел бы выступить в необычном для хаба Arduino качестве и рассказать не об устройстве, а о библиотеке.




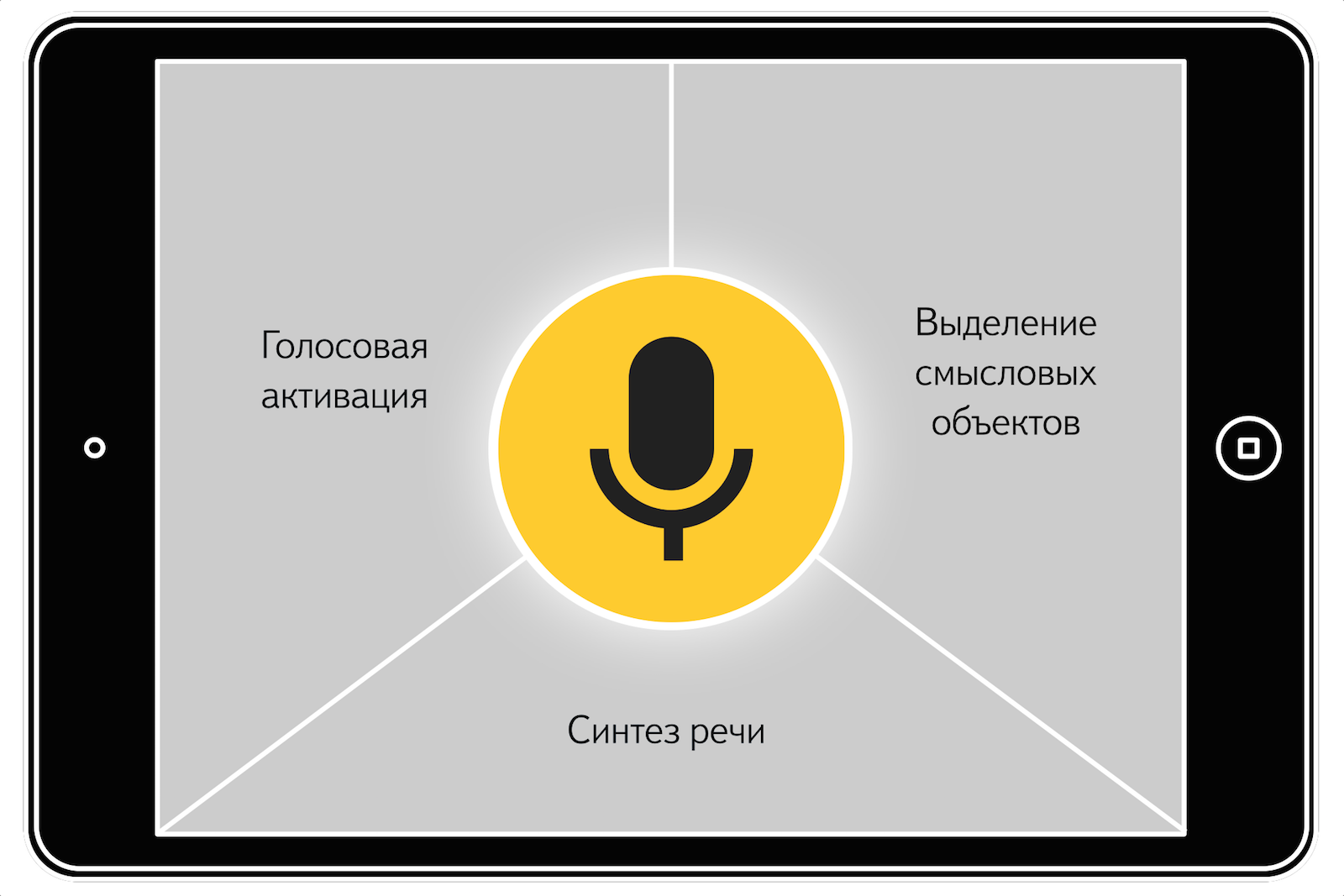


 В процессе общения в личке с
В процессе общения в личке с