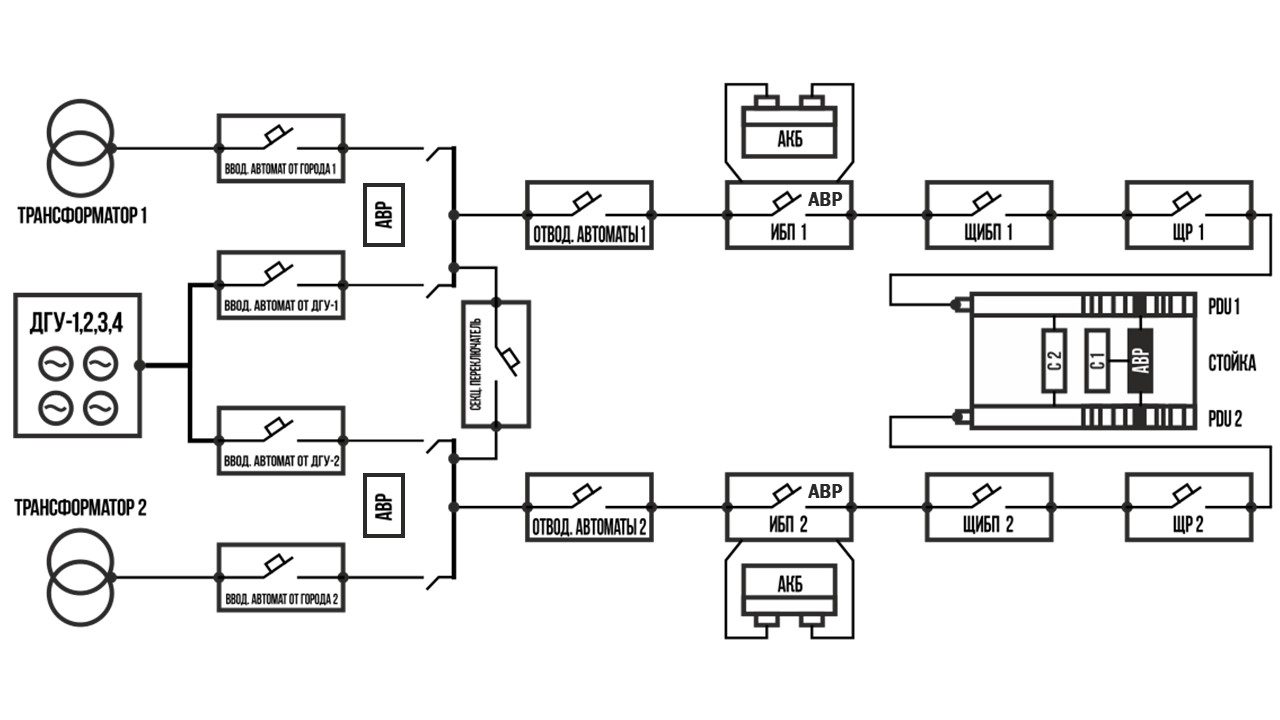
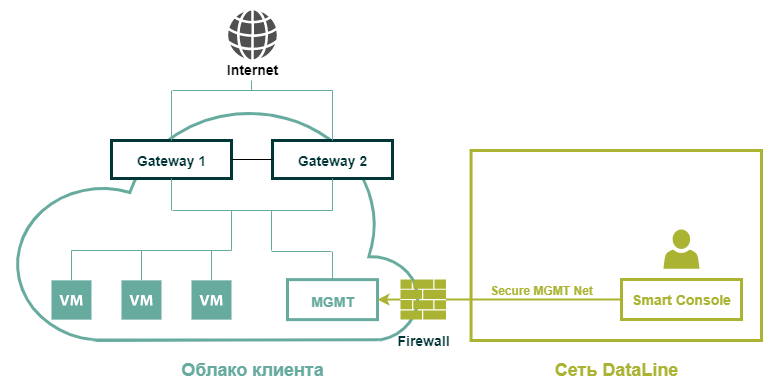
Привет, Хабр! Меня зовут Антон Клочков, я сетевой архитектор в компании DataLine, а также участник проекта linkmeup. Я занимаюсь сетями более 10 лет и за это время успел поработать в больших и маленьких телеком-операторах, крупных корпорациях и небольших бизнесах.
На практике я не раз убеждался, что физика упряма и обязательно отомстит за попытки пренебречь ее законами. За ошибки в физике сети я расплачивался квартальными премиями, исправлением косяков по ночам и «любовью» пользователей. Зато такая школа жизни запоминается раз и навсегда.
Сегодня хочу поделиться подборкой историй про физику сетей и сформулировать правила сетевой жизни, которые вывел на практике.

На практике я не раз убеждался, что физика упряма и обязательно отомстит за попытки пренебречь ее законами. За ошибки в физике сети я расплачивался квартальными премиями, исправлением косяков по ночам и «любовью» пользователей. Зато такая школа жизни запоминается раз и навсегда.
Сегодня хочу поделиться подборкой историй про физику сетей и сформулировать правила сетевой жизни, которые вывел на практике.
Дисклеймер: в статье собраны истории из моего опыта в больших и малых энтерпрайзах и операторах связи. Многие из них случились со мной или коллегами еще на заре карьеры. Большинство персонажей — собирательные образы, любые совпадения случайны. Мое мнение может не совпадать с мнением компании DataLine.