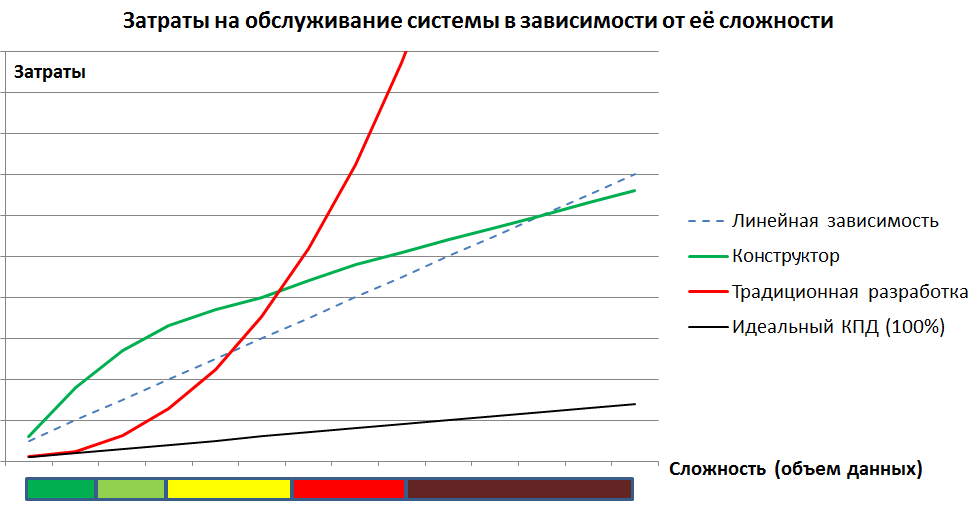
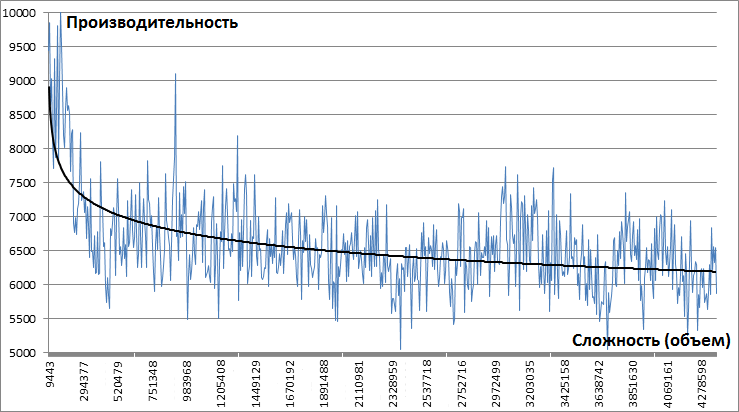
Недавно мы протестировали подход, именуемый нами QDM, при работе с большими объемами данных — сотни гигабайт. В рамках задачи мы обрабатывали по 12-24 млн записей и сравнивали производительность квинтетного решения с аналогичным функционалом в обычных таблицах.
Мы не сделали каких-то новых открытий, но подтвердили те гипотезы, что озвучивали ранее: насколько всё таки универсальный конструктор в руках условного «чайника» проигрывает профессионально настроенной базе данных.
Также мы теперь знаем, что делать в подобной ситуации — решение достаточно простое и надежное, и имеем опыт организации компромиссного решения для сколько угодно больших данных.