Лучшее в фрилансерской работе это то, что вы свободны в создании вашего собственного графика и правил. Однако это может быть и плохим фактором. Без нормально структурированного офисного пространства многие фрилансеры в конце дня могут задуматься – куда же делось все их время. Может быть трудно получить максимальную пользу от всего рабочего дня. Чтобы помочь таким фрилансерам, мы хотим представить некоторые простые пути для увеличения продуктивности.

User
Сравнение эффективности способов запуска веб-приложений на языке Python
8 min
Последнее время в области веб-разработок стал набирать популярность язык программирования Python. Однако, массовому распространение Python мешает проблема эффективного запуска приложений на этом языке. Пока, в большинстве случаев, это удел выделенных или виртуальных серверов. Модульные языки в отличии от монолитного в базовой функциональности php на каждый запрос подгружают как минимум runtime-библиотеку, а как максимум — ещё несколько десятков запрашиваемых пользователем модулей. Поэтому классический подход наподобие mod_php для Python и Perl не очень уместен, а держать приложение постоянно в памяти было дороговато. Но время движется, техника стала мощнее и дешевле, и уже достаточно давно можно спокойно говорить о постоянно запущенных процессах с приложением в рамках массового хостинга.
Время от времени, в сети появляются различные предложения как запустить приложение на Python. Например, недавно хостинг Джино уникально поправил mod_python и предложил хостинг именно с его помощью. Следом за ним, некий хостинг Locum вообще отринул mod_python с его безопасностью (создаётся впечатление, что суть самобытная безопасность — это единственная проблема АйТи на пути к нирване) и провёл победоносное тестирование modwsgi против fastcgi. Комьюнити же, судя по проведённому мною поиску, разрывается между mod_python и FastCGI. Причём, FastCGI обычно имеется ввиду тот, что идёт в поставке Django — flup. Являясь популярным хостингом Python-приложений, мы не смогли пройти мимо и решили внести свою лепту в эту священную войну.
О чём тут
Время от времени, в сети появляются различные предложения как запустить приложение на Python. Например, недавно хостинг Джино уникально поправил mod_python и предложил хостинг именно с его помощью. Следом за ним, некий хостинг Locum вообще отринул mod_python с его безопасностью (создаётся впечатление, что суть самобытная безопасность — это единственная проблема АйТи на пути к нирване) и провёл победоносное тестирование modwsgi против fastcgi. Комьюнити же, судя по проведённому мною поиску, разрывается между mod_python и FastCGI. Причём, FastCGI обычно имеется ввиду тот, что идёт в поставке Django — flup. Являясь популярным хостингом Python-приложений, мы не смогли пройти мимо и решили внести свою лепту в эту священную войну.
Верни мои деньги, банкомат
13 min
Бывает такое, что привычная, казалось бы, вещь, встречается с такой изюминкой, после которой начинаешь смотреть на эту вещь совершенно иначе. Так случилось и у меня… пару лет снимал деньги с карточки в сотне мест и бед не знал… а тут приехал в один городок и в первом же банкомате мне повстречалась эта самая изюминка. Причем место и обстоятельство были такими, что за пару мгновений пищи для размышления и впечатлений накопилось недели на две вперед.

Управление ботнетом через Твиттер
1 min
На Хабре было уже много топиков, посвящённых техническим аспектам работы ботнетом. Как известно, стандартный ботнет состоит из заражённых компьютеров (зомби) и управляющих серверов (C&C). Связь между ними поддерживается по самым разным протоколам: от IRC до P2P и HTTP. Однако на последней хакерской конференции Defcon был продемонстрирован ещё один интересный способ управления ботнетом — через твиттер.
Концепция проста до гениальности. Создаётся аккаунт на твиттере (новые аккаунты могут создаваться постоянно по заданному алгоритму, чтобы избежать блокировки) и твиттербот, который подписывается на него и воспринимает все твиты как команды на исполнение. Например, твит “cmd: look at 1.2.3.4” может запускать DDoS-атаку на адрес 1.2.3.4.
На Defcon'е был продемонстрирован в действии твиттербот KreiosC2, который реально может использоваться для управления ботнетом. Среди поддерживаемых фич — динамическое изменение языка управления (чтобы избежать фильтрации в твиттере), отсылка команд в закодированном (base64) и/или зашифрованном виде.

Концепция проста до гениальности. Создаётся аккаунт на твиттере (новые аккаунты могут создаваться постоянно по заданному алгоритму, чтобы избежать блокировки) и твиттербот, который подписывается на него и воспринимает все твиты как команды на исполнение. Например, твит “cmd: look at 1.2.3.4” может запускать DDoS-атаку на адрес 1.2.3.4.
На Defcon'е был продемонстрирован в действии твиттербот KreiosC2, который реально может использоваться для управления ботнетом. Среди поддерживаемых фич — динамическое изменение языка управления (чтобы избежать фильтрации в твиттере), отсылка команд в закодированном (base64) и/или зашифрованном виде.
Обзор литературы по Data Mining
7 min
Добрый день!
Публикация нескольких статей о Data Mining показала высокий интерес сообщества к данной теме. Много вопросов было задано по типу «где почитать» и «с чего начать». Предлагаю вашему вниманию подборку литературы, ресурсов для уверенного старта в данной области.
Публикация нескольких статей о Data Mining показала высокий интерес сообщества к данной теме. Много вопросов было задано по типу «где почитать» и «с чего начать». Предлагаю вашему вниманию подборку литературы, ресурсов для уверенного старта в данной области.

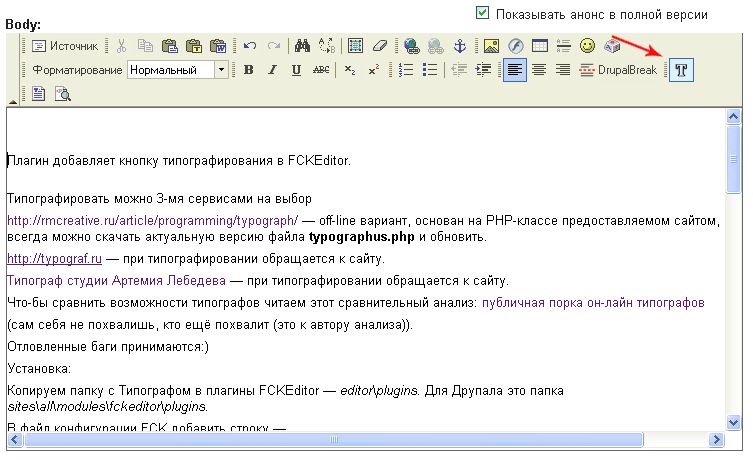
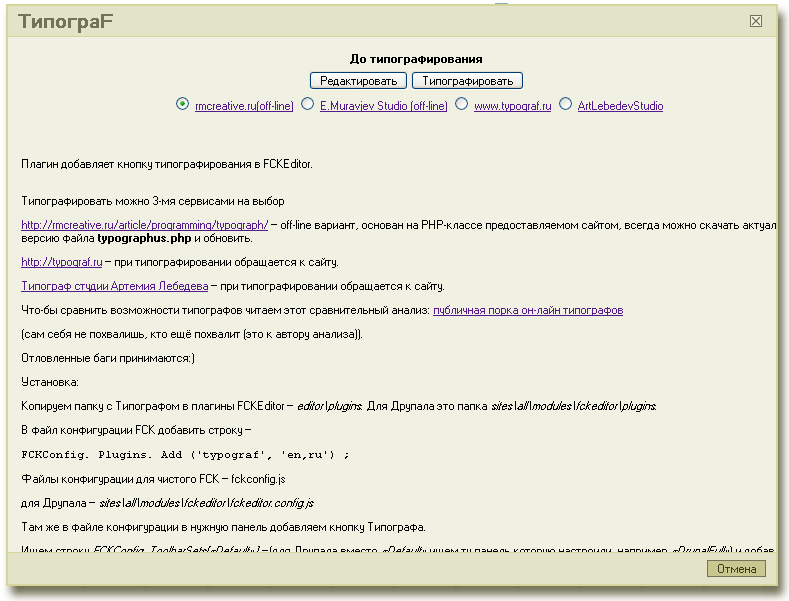
Типограф (плагин к редактору FCK)
1 min
(Пора выйти из тени)
О моем плагине уже писал товарищ
Теперь можно типографировать 4-мя типографами.
К уже имеющимся
rmcreative.ru/article/programming/typograph, typograf.ru,
Типограф студии Артемия Лебедева.
Добавил ещё один off-line типограф — студии Евгения Муравьева.
Все типографы настроены на работу с UTF-8.
Страница — Типограф для FCKEditor
Плагин делался первоначально для себя и так как к посту не было ни одного коммента, то и не правился.
О моем плагине уже писал товарищ
Теперь можно типографировать 4-мя типографами.
К уже имеющимся
rmcreative.ru/article/programming/typograph, typograf.ru,
Типограф студии Артемия Лебедева.
Добавил ещё один off-line типограф — студии Евгения Муравьева.
Все типографы настроены на работу с UTF-8.
Страница — Типограф для FCKEditor
Плагин делался первоначально для себя и так как к посту не было ни одного коммента, то и не правился.
Одно слово для выпускника: статистика (перевод)
5 min
Translation

Оригинал
Взял на себя смелость перевести интересную статью из The New York Times.
Закончив Гарвард по специальности “Археология и антропология”, Кэрри Граймс изучала виды поселений Майя, отмечая на карте места, где были найдены артефакты. Но потом ее увлекло то, что она называет “все эти математические и компьютерные штуки”, которые были частью ее работы.
Очищаем веб-страницы от информационного шума
5 min
Приветствую всех!
Предыдущие мои статьи были, в основном, о теоретической части Data Mining, сегодня хочу рассказать о практическом примере, который используется в кандидатской диссертации (в связи с этим данный пример на данном этапе развития нельзя считать полноценным работающим проектом, но прототипом его считать можно).
Будем очищать веб-страницы от «информационного шума».
Предыдущие мои статьи были, в основном, о теоретической части Data Mining, сегодня хочу рассказать о практическом примере, который используется в кандидатской диссертации (в связи с этим данный пример на данном этапе развития нельзя считать полноценным работающим проектом, но прототипом его считать можно).
Будем очищать веб-страницы от «информационного шума».
TAG_ADD Plugin
3 min
 Привет, %username%
Привет, %username%Как-то раз мне пришлось писать форму для добавления постов в блог. Помимо стандартных полей (название, дата, текст и.т.д.) необходимо было привинтить юзабельную форму добавления тегов.
Т.к. я кодю в jQuery, то и выбор был однозначным.
Вот необходимые задачи, которые я поставил перед собой:
- Легко в настройке
- Все теги храняться в одном файле (в кэше)
- Минимальная нагрузка на сервер и клиента
- Список тегов — подсказок открывается только для выбранного запроса на определенный тег.
«Кредитные хакеры»: методика банковских манипуляций
2 min
Продолжаем освещать самые интересные доклады с хакерской конференции Defcon. Кроме сугубо технических тем, там обсуждали и другие темы, не имеющие прямого отношения к IT. Например, технологии махинаций с получением банковских кредитов. Подробнейший доклад (полный текст) на эту тему представил известный специалист Кристофер Согоян (Christopher Soghoian). Именно его квартиру за подобные выходки в 2006 году обыскивало ФБР (в тот раз он сделал сайт, помогающий распечатать фальшивые авиабилеты, ничем не отличающиеся от настоящих).
Кредитный хакинг представляет собой список легальных приёмов, которые не запрещены законодательно и которые не предусматривают проникновения в чужие компьютерные системы. Но фактически эти приёмы предназначены для обмана банков и кредитных бюро. За счёт знания технологий их работы, и за счёт излишней формализации ими выдачи кредитов умные потребители могут получать кредиты с нулевой ставкой и стирать некоторую информацию из своих кредитных историй.
Приём первый
Подача множества кредитных запросов в течение нескольких часов в ряд банков. Поскольку запрос на кредитную историю обрабатывается несколько дней, банки не имеют возможности принять в расчёт параллельные запросы. То есть каждый из них действует так, словно у человека нет других задолженностей.
Данный способ могут использовать граждане с высоким кредитным рейтингом. Если прокачать рейтинг до приемлемого уровня (это довольно несложно), то потом можно в один момент завести карточки с совокупным лимитом на сотни тысяч долларов, воспользоваться бонусами на открытие карточки, а также получить кредит с нулевой процентной ставкой (это спецпредложение на 12-18 месяцев для погашения старых долгов, практикуется почти во всех банках для переманивания клиентов: кредитный хакер может вместо погашения долгов весь кредитный лимит положить на депозит).
Кредитный хакинг представляет собой список легальных приёмов, которые не запрещены законодательно и которые не предусматривают проникновения в чужие компьютерные системы. Но фактически эти приёмы предназначены для обмана банков и кредитных бюро. За счёт знания технологий их работы, и за счёт излишней формализации ими выдачи кредитов умные потребители могут получать кредиты с нулевой ставкой и стирать некоторую информацию из своих кредитных историй.
Приём первый
Подача множества кредитных запросов в течение нескольких часов в ряд банков. Поскольку запрос на кредитную историю обрабатывается несколько дней, банки не имеют возможности принять в расчёт параллельные запросы. То есть каждый из них действует так, словно у человека нет других задолженностей.
Данный способ могут использовать граждане с высоким кредитным рейтингом. Если прокачать рейтинг до приемлемого уровня (это довольно несложно), то потом можно в один момент завести карточки с совокупным лимитом на сотни тысяч долларов, воспользоваться бонусами на открытие карточки, а также получить кредит с нулевой процентной ставкой (это спецпредложение на 12-18 месяцев для погашения старых долгов, практикуется почти во всех банках для переманивания клиентов: кредитный хакер может вместо погашения долгов весь кредитный лимит положить на депозит).
Анализ рыночной корзины и ассоциативные правила
3 min
В продолжении темы о Data Mining поговорим о том, с чего все начиналось. А начиналось все с анализа рыночной корзины (market basket analysis).
Из глоссария BaseGroup:
Анализ рыночной корзины — процесс поиска наиболее типичных шаблонов покупок в супермаркетах. Он производится путем анализа баз данных транзакций с целью определения комбинаций товаров, связанных между собой. Иными словами, выполняется обнаружение товаров, наличие которых в транзакции влияет на вероятность появления других товаров или их комбинаций.
Результаты, полученные с помощью анализа рыночной корзины, позволяют оптимизировать ассортимент товаров и запасы, размещение их в торговых залах, увеличивать объемы продаж за счет предложения клиентам сопутствующих товаров. Например, если в результате анализа будет установлено, что совместная покупка макарон и кетчупа является типичным шаблоном, то разместив эти товары на одной и той же витрине можно «спровоцировать» покупателя на их совместное приобретение.
Из глоссария BaseGroup:
Анализ рыночной корзины — процесс поиска наиболее типичных шаблонов покупок в супермаркетах. Он производится путем анализа баз данных транзакций с целью определения комбинаций товаров, связанных между собой. Иными словами, выполняется обнаружение товаров, наличие которых в транзакции влияет на вероятность появления других товаров или их комбинаций.
Результаты, полученные с помощью анализа рыночной корзины, позволяют оптимизировать ассортимент товаров и запасы, размещение их в торговых залах, увеличивать объемы продаж за счет предложения клиентам сопутствующих товаров. Например, если в результате анализа будет установлено, что совместная покупка макарон и кетчупа является типичным шаблоном, то разместив эти товары на одной и той же витрине можно «спровоцировать» покупателя на их совместное приобретение.
Поиск нечетких дубликатов. Алгоритм шинглов для веб-документов
4 min
Ранее я показал элементарную реализацию алгоритма шинглов, позволяющую определять, являются ли два документа почти дубликатами или нет. В этот раз я поясню реализацию алгоритма, описанную Зеленковым Ю. Г. и Сегаловичем И.В. в публикации «Сравнительный анализ методов определения нечетких дубликатов для Web-документов».
Этим я начинаю серию из трех теоретических статей, в которых постараюсь доступным языком описать принцип алгоритмов шинглов, супершинглов и мегашинглов для сравнение веб-документов.
Этим я начинаю серию из трех теоретических статей, в которых постараюсь доступным языком описать принцип алгоритмов шинглов, супершинглов и мегашинглов для сравнение веб-документов.
Кешируем блоки HTML при помощи nginx
3 min
Не секрет, что пользователи любят, когда контент на сайте обновляется чаще, чем раз в год. Эту любовь пользователей к динамическим страничкам разделяют и поисковики. Google, например, умеет определять наличие обновляющихся блоков на страничке и добавляет ей немного кармы (читай, PR).
Однако динамический контент довольно плохо сочетается с большими нагрузками. Для веб-сервера, отдача статической странички — намного более простая задача, чем запуск кода, который сгенерит эту страничку динамически. В некоторых случаях может выручить прегенерация всех возможных вариантов странички, но это не спасёт, если их слишком много, или страница обновляется слишком часто.
Однако динамический контент довольно плохо сочетается с большими нагрузками. Для веб-сервера, отдача статической странички — намного более простая задача, чем запуск кода, который сгенерит эту страничку динамически. В некоторых случаях может выручить прегенерация всех возможных вариантов странички, но это не спасёт, если их слишком много, или страница обновляется слишком часто.
AMQP по-русски
4 min
Сегодня довольно мало информации о протоколе AMQP (Advanced Message Queueing Protocol) и его применении, особенно на русском языке. А вообще это — замечательный, уже достаточно широко поддерживаемый открытый протокол для передачи сообщений между компонентами системы с низкой задержкой и на высокой скорости. При этом семантика обмена сообщениями настраивается под нужды конкретного проекта. Такие решения существовали и ранее, но это первый стандарт, для которого существует большое количество свободных реализаций.
Основная идея состоит в том, что отдельные подсистемы (или независимые приложения) могут обмениваться произвольным образом сообщениями через AMQP-брокер, который осуществляет маршрутизацию, возможно гарантирует доставку, распределение потоков данных, подписку на нужные типы сообщений. В качестве классических примеров обычно приводятся финансовые приложения, связанные, например, с доставкой потребителям информации о курсах ценных бумаг в режиме реального времени, также возможно RPC-взаимодействие двух подсистем, которые не имеют связи друг с другом (взаимодействие через общий протокол AMQP) и так далее и тому подобное.
Сегодня тема доставки информации в реальном времени является крайне актуальной (достаточно вспомнить хотя бы Twitter, Google Wave). И здесь системы передачи сообщений могут служить внутренним механизмом обмена данными, который обеспечивает доставку данных (изменений данных) клиентам.
Я не ставлю своей целью сегодня рассказать о том, как писать приложения для AMQP. Хочу лишь немного рассказать о том, что это совсем не страшно, не очень сложно, и действительно работает, хотя стандарт находится еще в развитии, выходят новые версии протокола, брокеров и т.п. Но это уже вполне production-quality. Расскажу лишь базовые советы, чтобы помочь “въехать” в протокол.
Основная идея состоит в том, что отдельные подсистемы (или независимые приложения) могут обмениваться произвольным образом сообщениями через AMQP-брокер, который осуществляет маршрутизацию, возможно гарантирует доставку, распределение потоков данных, подписку на нужные типы сообщений. В качестве классических примеров обычно приводятся финансовые приложения, связанные, например, с доставкой потребителям информации о курсах ценных бумаг в режиме реального времени, также возможно RPC-взаимодействие двух подсистем, которые не имеют связи друг с другом (взаимодействие через общий протокол AMQP) и так далее и тому подобное.
Сегодня тема доставки информации в реальном времени является крайне актуальной (достаточно вспомнить хотя бы Twitter, Google Wave). И здесь системы передачи сообщений могут служить внутренним механизмом обмена данными, который обеспечивает доставку данных (изменений данных) клиентам.
Я не ставлю своей целью сегодня рассказать о том, как писать приложения для AMQP. Хочу лишь немного рассказать о том, что это совсем не страшно, не очень сложно, и действительно работает, хотя стандарт находится еще в развитии, выходят новые версии протокола, брокеров и т.п. Но это уже вполне production-quality. Расскажу лишь базовые советы, чтобы помочь “въехать” в протокол.
Бизнес кейсы использования Data Mining. Часть 1
3 min
Привет, хабр.
Очень рад, что тема Data Mining интересна сообществу.
В данном топике (а если понравится, — в серии топиков) расскажу, какие примеры использования Data Mining есть в Российском и не только бизнесе. Почему я пишу об этом? Я работаю в компании, которая тесно связана с ВЦ РАН (Вычислительный центр Российской академии наук), что позволяет нам иметь отличный научно-исследовательский отдел и разрабатывать новые проекты, применяя отечественные достижения в математике. В данном топике будет больше бизнеса, чем науки, но если последняя все же вас интересует, тогда вам сюда: mmro.ru или сюда: www.machinelearning.ru
Итак, поехали:
Очень рад, что тема Data Mining интересна сообществу.
В данном топике (а если понравится, — в серии топиков) расскажу, какие примеры использования Data Mining есть в Российском и не только бизнесе. Почему я пишу об этом? Я работаю в компании, которая тесно связана с ВЦ РАН (Вычислительный центр Российской академии наук), что позволяет нам иметь отличный научно-исследовательский отдел и разрабатывать новые проекты, применяя отечественные достижения в математике. В данном топике будет больше бизнеса, чем науки, но если последняя все же вас интересует, тогда вам сюда: mmro.ru или сюда: www.machinelearning.ru
Итак, поехали:
DNS Amplification (DNS усиление)
6 min
Не так давно столкнулся с проблемой (и ее решением) учитывая актуальность этой темы в последнее время, а также то, сколько людей сейчас страдают от этой беды, решил объединить информацию в одну статью. Может быть кому-то еще она будет полезной.
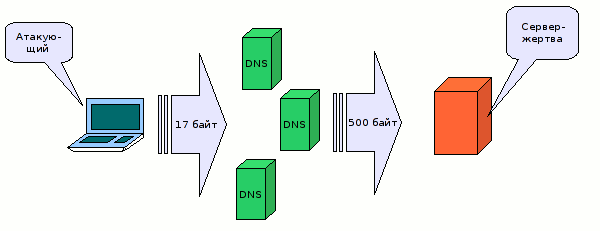
Пару недель назад я заметил странную активность, направленную на мой DNS-сервер. Сразу скажу, что использую шлюз на Linux, соответственно там установлен DNS-сервер bind. Активность заключалась в том, что на порт 53 (DNS) моего сервера сыпалось по несколько UDP пакетов в секунду с различных IP-адресов:
10:41:42.163334 IP 89.149.221.182.52264 > MY_IP.53: 22912+ NS?. (17)
10:41:42.163807 IP MY_IP.53 > 89.149.221.182.52264: 22912 Refused- 0/0/0 (17)
Начало
Пару недель назад я заметил странную активность, направленную на мой DNS-сервер. Сразу скажу, что использую шлюз на Linux, соответственно там установлен DNS-сервер bind. Активность заключалась в том, что на порт 53 (DNS) моего сервера сыпалось по несколько UDP пакетов в секунду с различных IP-адресов:
10:41:42.163334 IP 89.149.221.182.52264 > MY_IP.53: 22912+ NS?. (17)
10:41:42.163807 IP MY_IP.53 > 89.149.221.182.52264: 22912 Refused- 0/0/0 (17)
Основы
8 min
Сегодня я постараюсь рассказать самые основы, такие, как базовые типы данных, типы функций, ФВП, списки (в том числе и бесконечные).
Последующие статьи:
Типы данных, паттерн матчинг и функции
Классы типов, монады
Последующие статьи:
Типы данных, паттерн матчинг и функции
Классы типов, монады
Кластеризация memcached и выбор ключа кэширования
4 min
Серия постов под общим заглавием “Web, кэширование и memcached” продолжается. В первом мы поговорили о memcached, его архитектуре и возможном применении.
Сегодня речь пойдет о:
Следующий пост будет посвящен атомарности операций и счетчикам в memcached.
Сегодня речь пойдет о:
- выборе ключа кэширования;
- кластеризации memcached и алгоритмах распределения ключей.
Следующий пост будет посвящен атомарности операций и счетчикам в memcached.
Кэширование и memcached
7 min
Этим постом хочу открыть небольшую серию постов по материалам доклада на HighLoad++-2008. Впоследствии весь текст будет опубликован в виде одной большой PDF-ки.
Введение
Для начала, о названии серии постов: посты будут и о кэшировании в Web’е (в высоконагруженных Web-проектах), и о применении memcached для кэширования, и о других применениях memcached в Web-проектах. То есть все три составляющие названия в различных комбинациях будут освещены в этой серии постов.