Думаю многие фрилансеры и не только, задавались этим вопросом. Сначала написал целый абзац текста, а потом подумал зачем лить воду? В общем вот конкретика:

Сергей @Vanger13
User
u-Nebula: первое свидание
8 min
Сразу хочется извиниться за задержку с обзорной статьей по движку и поблагодарить за поддержку и комментарии к предыдущему посту. Отклонение от ранее взятых обязательств было вызвано возней с нашим художеством и желанием сделать вводную статью с использованием Lisp’a. К сожалению поддержка Lisp’a у нас пока весьма сырая так, что мы воспользуемся надежным Tcl. В конце пути, у нас должна получится визуализация медитативно-расслабляющего плана (применять в случае зимней депрессии).
Под катом текст, код и картинки.
Под катом текст, код и картинки.
Ход «Voronoi»
9 min
Вместо предисловия
Урок русского языка вгрузинскойнерусской школе.
Учительница:
— Дэти, это нэльзя понять, это надо запомнить: ОТ ВАС пишется раздельно, а
КВАС — вместе.
Анекдот взят тут.
Введение
На написание статьи вдохновила игра «Wesnoth» — пошаговая стратегия с элементами RPG. В этой игре персонажи перемещаются по карте, состоящей из шестиугольных полигонов. Таким образом, окруженный со всех сторон персонаж может быть атакован шестью вражескими. По этой причине тактическая составляющая в игре очень важна. Возник вопрос: как повлияет на игровой процесс переход от карты с фиксированной геометрией полигонов на карту с произвольной геометрией?
Как хакер издевался над преступником, своровавшим его ПК
1 min
Хакер под ником Zoz выступил на конференции Defcon 18 с 20-минутным рассказом, как ему удалось обнаружить десктоп, украденный год назад. История действительно необычная (слайды презентации, видео (см. с 3:15)).
Zoz месяцами выслеживал, когда где-нибудь на аукционах появятся комплектующие с его серийными номерами, но безуспешно. Аккаунт в сервисе DynDNS (привязка домена к динамическому IP-адресу) тоже не подавал признаков жизни. Через 30 дней они прислали письмо, что если желаете сохранить аккаунт в режиме отсутствия активности, то нужно купить апгрейд до версии Pro. В октябре 2009 года Zoz сделал это — и удача повернулась у нему лицом.
7 мая 2010 года в аккаунте DynDNS появилась странная запись.
Zoz месяцами выслеживал, когда где-нибудь на аукционах появятся комплектующие с его серийными номерами, но безуспешно. Аккаунт в сервисе DynDNS (привязка домена к динамическому IP-адресу) тоже не подавал признаков жизни. Через 30 дней они прислали письмо, что если желаете сохранить аккаунт в режиме отсутствия активности, то нужно купить апгрейд до версии Pro. В октябре 2009 года Zoz сделал это — и удача повернулась у нему лицом.
7 мая 2010 года в аккаунте DynDNS появилась странная запись.
Qt + QML на простом примере
13 min
 Qt является удобным и гибким средством для создания кросс-платформенного программного обеспечения. Входящий в его состав QML предоставляет полную свободу действий при создании пользовательского интерфейса.
Qt является удобным и гибким средством для создания кросс-платформенного программного обеспечения. Входящий в его состав QML предоставляет полную свободу действий при создании пользовательского интерфейса. Об удобстве использования связки Qt и QML уже говорилось не раз, поэтому не буду дальше распространяться о плюсах, минусах, а приведу, шаг за шагом, пример простого Qt приложения.
Как я наказал Firaxis или история о том, как перебрать бинарный движок через глушитель
6 min

Речь пойдёт о далёком 2005 году, когда только-только вышла Civilization4 от Sid Meier. К тому времени я плотно висел в Civilization3, прошёл её раз дцать на самых разных картах, и тут вышла долгожданная четвёрка. Это были годы P3-512Mb для mid-end и P4-1Gb в hi-end. Только топовые конфиги в те годы имели два гига памяти на борту.
Civilization 4 вышла с графикой уровня года 2002-2003го, что в принципе нормально для мэинстрима тех времён, особенно учитывая что это пошаговая стратегия, а не шутер. Но жрала с течением игры до 900Mb оперативки, что приводило к жуткому свопу, особенно на больших картах, особенно к концу игры, особенно на ноутбуках. Народ недоумевал, я тоже. Учитывая, что в те же годы вышел Far Cry с куда более красивой графикой, и который вполне игрался на максимуме даже с 512Mb на борту, такое поведение Civilization 4 выглядело крайне странным. Захотелось разобраться и покарать…
Латентно-семантический анализ
4 min
Как находить тексты похожие по смыслу? Какие есть алгоритмы для поиска текстов одной тематики? – Вопросы регулярно возникающие на различных программистских форумах. Сегодня я расскажу об одном из подходов, которым активно пользуются поисковые гиганты и который звучит чем-то вроде мантры для SEO aka поисковых оптимизаторов. Этот подход называет латентно-семантический анализ (LSA), он же латентно-семантическое индексирование (LSI)

Объединяем две локальные сети через интернет. Vpn lan to lan. Asus wl520gu+dd-wrt и FreeBSD+mpd5
3 min
Введение.
Мне повезло работать в организации которая развивается, и время от времени возникают новые задачи, позволяющие и мне расти. На этот раз мне было необходимо объединить головной офис и второй филиал. Задача для меня не новая, но к её решению я решил подойти иначе нежели раньше.
На текущий момент в головном офисе установлена FreeBSD + mpd5 в качестве PPTP сервера. В первом филиале аналогично(за исключением того что используется как vpn клиент). Так же есть 8 точек где установлено по одному компьютеру с ОС Windows XP «цепляющихся» к головному стандартным клиентом этой ОС.
Мне необходимо создать еще один туннель между двумя сетями, но любимую ОС FreeBSD я использовать не могу, в силу ограниченного места для установки роутера во втором филиале(это магазин розничной торговли, все оборудование приютилось на узеньком стелаже). К тому же хотелось попробовать прошивку dd-wrt, о которой так много слышал, в деле.
Мне повезло работать в организации которая развивается, и время от времени возникают новые задачи, позволяющие и мне расти. На этот раз мне было необходимо объединить головной офис и второй филиал. Задача для меня не новая, но к её решению я решил подойти иначе нежели раньше.
На текущий момент в головном офисе установлена FreeBSD + mpd5 в качестве PPTP сервера. В первом филиале аналогично(за исключением того что используется как vpn клиент). Так же есть 8 точек где установлено по одному компьютеру с ОС Windows XP «цепляющихся» к головному стандартным клиентом этой ОС.
Мне необходимо создать еще один туннель между двумя сетями, но любимую ОС FreeBSD я использовать не могу, в силу ограниченного места для установки роутера во втором филиале(это магазин розничной торговли, все оборудование приютилось на узеньком стелаже). К тому же хотелось попробовать прошивку dd-wrt, о которой так много слышал, в деле.
[Перевод] Java Best Practices. Преобразование Char в Byte и обратно
4 min
Сайт Java Code Geeks изредка публикует посты в серии Java Best Practices — проверенные на production решения. Получив разрешение от автора, перевёл один из постов. Дальше — больше.
Метод динамического программирования для подсчёта числа циклов на прямоугольной решетке
11 min
Эта статья адресована тем читателям, кто занимается программированием алгоритмов, и особенно интересуется труднорешаемыми задачами. Тем хабралюдям, которые против размещения алгоритмов на Хабре следует немедленно прекратить читать данную работу.
В статье я покажу как использовать метод динамического программирования по профилю для решения задачи о подсчёте количества гамильтоновых циклов на прямоугольной решётке размером m на n. На Хабре есть несколько статей, посвященных теме динамического программирования (например, эта), но нигде не идёт речь о более сложном применении метода. Данный подход также можно называть методом матрицы переноса, кому как нравится.
Предупреждаю, что статья содержит около 2000 слов (8 страниц А4), но дорогу осилит идущий.
В статье я покажу как использовать метод динамического программирования по профилю для решения задачи о подсчёте количества гамильтоновых циклов на прямоугольной решётке размером m на n. На Хабре есть несколько статей, посвященных теме динамического программирования (например, эта), но нигде не идёт речь о более сложном применении метода. Данный подход также можно называть методом матрицы переноса, кому как нравится.
Предупреждаю, что статья содержит около 2000 слов (8 страниц А4), но дорогу осилит идущий.
Компрессия данных в системах промышленной автоматизации. Алгоритм SwingingDoor
5 min
Здравствуйте, уважаемые читатели. Хочу представить вашему вниманию описание алгоритма компрессии данных SwingingDoor и рассказать о том, как мы его применяем.
По роду деятельности я занимаюсь разработкой решений в области промышленной автоматизации, а более конкретно — разработкой информационных систем производства. Их назначение — предоставлять информацию для людей и других систем. Они предоставляют оперативные, самые последние данные, а также данные за прошлое. Данные поступают из многочисленных систем контроля (СК), количество параметров измеряется десятками тысяч.
Зачем использовать компрессию, почему бы не хранить все данные?
По роду деятельности я занимаюсь разработкой решений в области промышленной автоматизации, а более конкретно — разработкой информационных систем производства. Их назначение — предоставлять информацию для людей и других систем. Они предоставляют оперативные, самые последние данные, а также данные за прошлое. Данные поступают из многочисленных систем контроля (СК), количество параметров измеряется десятками тысяч.
Зачем использовать компрессию, почему бы не хранить все данные?
Система непересекающихся множеств и её применения
10 min
Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
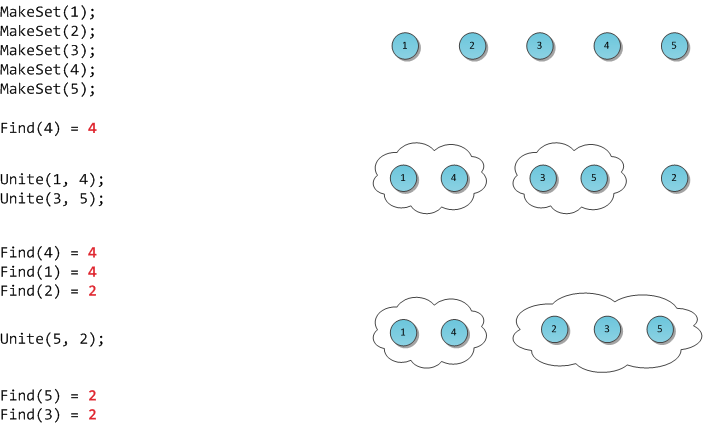
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
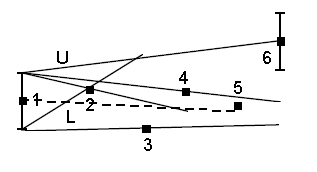
На рисунке я продемонстрирую работу такой гипотетической структуры.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
Мини-задачка: «олд-скульное» дерево
3 min
Постановка задачи
Буквально несколько дней назад Eric Lippert на своем блоге Fabulous Adventures In Coding опубликовал очень простую, но занимательную задачку:
Есть дерево, заданное с помощью класса Node, в котором есть Children с теми же самыми Node и какой-то Text (чуть ниже приведу код класса). Необходимо сгенерировать строку такого вида (включая переносы строк):
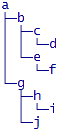 Использовать нужно юникодовые символы "│ ├ ─ └" (вспомним старые добрые картинки с псевдографикой). Цель, которую поставил себе Эрик — выяснить, какие предпочтения будут сделаны при составлении решения: рекурсивное (так как дерево), более быстрое или более читабельное.
Использовать нужно юникодовые символы "│ ├ ─ └" (вспомним старые добрые картинки с псевдографикой). Цель, которую поставил себе Эрик — выяснить, какие предпочтения будут сделаны при составлении решения: рекурсивное (так как дерево), более быстрое или более читабельное.Естественные алгоритмы. Реализация алгоритма поведения роя пчёл
2 min
В моей предыдущей статье описывался алгоритм поведения роя пчёл и применение его для решения задач оптимизации и синтеза. Вооружившись С++ и OpenGL я написал программу, реализующую этот самы алгоритм в двухмерном пространстве, и отображающую роение «пчёл».
В качестве испытательной функции была выбрана следующая функция:=-J_{0}(x^2 + y^2)-0.1*|1-x|-0.1*|1-y|")



В качестве испытательной функции была выбрана следующая функция:



Внутри MP3. А как оно всё устроено?
5 min

Однажды мне понадобилось решить простенькую (как мне тогда казалось) задачу – в PHP-скрипте узнать длительность mp3-файла. Я слышал о ID3 тегах и сразу подумал, что информация о длительности хранится либо в тегах, либо в заголовках mp3-файла. Поверхностные поиски в интернете показали что за пару-тройку минут решить эту задачу не получится. Поскольку от природы я довольно любопытен а время не поджимало — решил не использовать сторонние инструменты а разобраться в одном из самых популярных форматов самостоятельно.
Если Вам интересно, что там внутри – добро пожаловать под кат (трафик).
Асимптотический анализ алгоритмов
7 min
Прежде чем приступать к обзору асимптотического анализа алгоритмов, хочу сказать пару слов о том, в каких случаях написанное здесь будет актуальным. Наверное многие программисты читая эти строки, думают про себя о том, что они всю жизнь прекрасно обходились без всего этого и конечно же в этих словах есть доля правды, но если встанет вопрос о доказательстве эффективности или наоборот неэффективности какого-либо кода, то без формального анализа уже не обойтись, а в серьезных проектах, такая потребность возникает регулярно.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
Видеоверсия семинара Калерво Ярвелина (Kalervo Järvelin)
1 min
Translation
11 августа в Яндексе прошел семинар Калерво Ярвелина «Why do people use short queries in real life? A session-based analysis of short query effectiveness».
Мы благодарим всех, кто посетил данное мероприятие.
Для тех, кто не смог посетить семинар, мы подготовили видеоверсию выступления:
Скачать презентацию докладчика и видео в хорошем качестве можно на странице научных семинаров.
Юлия Симутенко, обучаем и развиваем
Декартово дерево: Часть 2. Ценная информация в дереве и множественные операции с ней
14 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Тема сегодняшней лекции
В прошлый раз мы с вами познакомились — скажем прямо, очень обширно познакомились — с понятием декартового дерева и основным его функционалом. Только до сих мы с вами использовали его одним-единственным образом: как «квази-сбалансированное» дерево поиска. То есть пускай нам дан массив ключей, добавим к ним случайно сгенерированные приоритеты, и получим дерево, в котором каждый ключ можно искать, добавлять и удалять за логарифмическое время и минимум усилий. Звучит неплохо, но мало.
К счастью (или к сожалению?), реальная жизнь такими пустяковыми задачами не ограничивается. О чем сегодня и пойдет речь. Первый вопрос на повестке дня — это так называемая K-я порядковая статистика, или индекс в дереве, которая плавно подведет нас к хранению пользовательской информации в вершинах, и наконец — к бесчисленному множеству манипуляций, которые с этой информацией может потребоваться выполнять. Поехали.
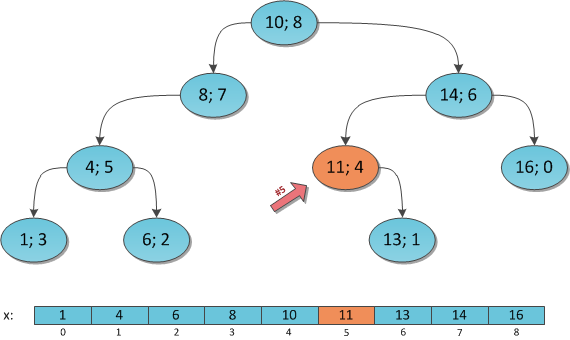
Ищем индекс
В математике, K-я порядковая статистика — это случайная величина, которая соответствует K-му по величине элементу случайной выборки из вероятностного пространства. Слишком умно. Вернемся к дереву: в каждый момент времени у нас есть декартово дерево, которое с момента его начального построения могло уже значительно измениться. От нас требуется очень быстро находить в этом дереве K-й по порядку возрастания ключ — фактически, если представить наше дерево как постоянно поддерживающийся отсортированным массив, то это просто доступ к элементу под индексом K. На первый взгляд не очень понятно, как это организовать: ключей-то у нас в дереве N, и раскиданы они по структуре как попало.
Оптимизация ПО для iPhone: живой пример
7 min
Программирование на платформе iOS (той, что еще недавно называлась iPhone OS) – странное сочетание радости от плодотворной работы и муки плавания против течения. У каждого разработчика свое мнение относительно того, какая из этих компонент преобладает. Лично мне это занятие нравится, поэтому мне показалось уместным поделиться впечатлениями от процесса работы над очередным проектом.
В конце марта мне предложили написать мобильную версию Bookmate для iPhone. Дизайн большей части приложения был уже готов в виде толстенного PSD, на стороне сервера работа кипела, мне же оставалось, как говорится, «всего лишь» написать клиентскую часть на Objective-C.
В этой статье речь пойдет о первом контейнере с граблями, нас атаковавшими. Если Вы играете в Starcraft, более подходящей будет аналогия с зергами, которые вдруг полезли изо всех щелей в типично-неимоверных количествах.
В конце марта мне предложили написать мобильную версию Bookmate для iPhone. Дизайн большей части приложения был уже готов в виде толстенного PSD, на стороне сервера работа кипела, мне же оставалось, как говорится, «всего лишь» написать клиентскую часть на Objective-C.
В этой статье речь пойдет о первом контейнере с граблями, нас атаковавшими. Если Вы играете в Starcraft, более подходящей будет аналогия с зергами, которые вдруг полезли изо всех щелей в типично-неимоверных количествах.
Декартово дерево: Часть 1. Описание, операции, применения
15 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в обзорном посте многоуважаемого winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть пост про двоичные деревья поиска того же winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы — куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
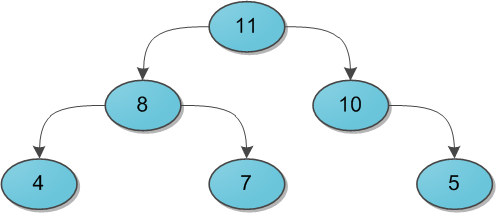
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.