
Несмотря на огромную популярность аппарата графических моделей для решения задачи структурной классификации, задача настройки их параметров по обучающей выборке долгое время оставалась открытой. В своем докладе Дмитрий Ветров, рассказал об обобщении метода опорных векторов и некоторых особенностях его применения для настройки параметров графических моделей. Дмитрий – руководитель группы Байесовских методов, доцент ВМК МГУ и преподаватель в ШАДе.
Видеозапись доклада.
План доклада:
Сама концепция машинного обучения довольно несложная – это, если говорить образно, поиск взаимосвязей в данных. Данные представляются в классической постановке набором объектов, взятых из одной и той же генеральной совокупности, у каждого объекта есть наблюдаемые переменные, есть скрытые переменные. Наблюдаемые переменные (дальше будем их обозначать X) часто называются признаками, соответственно, скрытые переменные (T) — это те, которые подлежат определению. Для того, чтобы эту взаимосвязь между наблюдаемыми и скрытыми переменными установить, предполагается, что у нас есть обучающая выборка, т.е. набор объектов, для которых известны и наблюдаемые и скрытые компоненты. Глядя на нее, мы пытаемся настроить некоторые решающие правила, которые нам позволят в дальнейшем, когда мы видим набор признаков, оценить скрытые компоненты. Процедура обучения приблизительно выглядит следующим образом: фиксируется множество допустимых решающих правил, которые как правило задаются с помощью весов (W), а дальше каким-то образом в ходе обучения эти веса настраиваются. Тут же с неизбежностью возникает проблема переобучения, если у нас слишком богатое семейство допустимых решающих правил, то в процессе обучения мы легко можем выйти на случай, когда для обучающей выборки мы прекрасно прогнозируем ее скрытую компоненту, а вот для новых объектов прогноз оказывается плохой. Исследователями в области машинного обучения было потрачено немало лет и усилий для того, чтобы эту проблему снять с повестки дня. В настоящее время, кажется, что худо-бедно это удалось.
Видеозапись доклада.
План доклада:
- Байесовские методы в машинном обучении.
- Задачи с взаимозависимыми скрытыми переменными.
- Вероятностные графические модели
- Метод опорных векторов и его обобщение для настройки параметров графических моделей.
Сама концепция машинного обучения довольно несложная – это, если говорить образно, поиск взаимосвязей в данных. Данные представляются в классической постановке набором объектов, взятых из одной и той же генеральной совокупности, у каждого объекта есть наблюдаемые переменные, есть скрытые переменные. Наблюдаемые переменные (дальше будем их обозначать X) часто называются признаками, соответственно, скрытые переменные (T) — это те, которые подлежат определению. Для того, чтобы эту взаимосвязь между наблюдаемыми и скрытыми переменными установить, предполагается, что у нас есть обучающая выборка, т.е. набор объектов, для которых известны и наблюдаемые и скрытые компоненты. Глядя на нее, мы пытаемся настроить некоторые решающие правила, которые нам позволят в дальнейшем, когда мы видим набор признаков, оценить скрытые компоненты. Процедура обучения приблизительно выглядит следующим образом: фиксируется множество допустимых решающих правил, которые как правило задаются с помощью весов (W), а дальше каким-то образом в ходе обучения эти веса настраиваются. Тут же с неизбежностью возникает проблема переобучения, если у нас слишком богатое семейство допустимых решающих правил, то в процессе обучения мы легко можем выйти на случай, когда для обучающей выборки мы прекрасно прогнозируем ее скрытую компоненту, а вот для новых объектов прогноз оказывается плохой. Исследователями в области машинного обучения было потрачено немало лет и усилий для того, чтобы эту проблему снять с повестки дня. В настоящее время, кажется, что худо-бедно это удалось.

 Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»


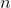 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то 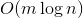 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 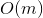 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.

 С каждым новом поколением процессоры Intel вбирают в себя все больше технологий и функций. Некоторые из них у всех на слуху (кто, например, не знает про гипертрединг?), о существовании других большинство неспециалистов даже не догадываются. Откроем всем хорошо известную базу знаний по продуктам Intel
С каждым новом поколением процессоры Intel вбирают в себя все больше технологий и функций. Некоторые из них у всех на слуху (кто, например, не знает про гипертрединг?), о существовании других большинство неспециалистов даже не догадываются. Откроем всем хорошо известную базу знаний по продуктам Intel 