Что-что?
Что-что?LINQ — это штука, которая позволяет писать запросы, чем-то похожие на SQL, прямо в коде. LINQ to Objects, собственно, позволяет писать запросы к объектам, массивам и всему тому, чем вы оперируете в коде.
Это ещё зачем?
Если у вас есть база, то у вас есть любимый ORM (или любимый голый SQL — кому как по вкусу). Но иногда объекты приходят из веб-сервисов, из файлов, да и вообще тьма тьмущая объектов может требовать нетривиальной обработки: преобразование, фильтрация, сортировка, группировка, агрегация… Применить бы привычный ORM или SQL — но базы-то нет. Тут на помощь приходит LINQ to Objects, в данном случае YaLinqo.
Что умеет?
- Самый полный порт .NET LINQ на PHP, со многими дополнительными методами. Всего реализовано более 70 методов.
- Ленивые вычисления, текст исключений и многое другое, как в оригинальном LINQ.
- Детальная документация PHPDoc к каждому методу. Текст статей адаптирован из MSDN.
- 100% покрытие юнит-тестами.
- Коллбэки можно задавать замыканиями, «указателями на функцию» в виде строк и массивов, строковыми «лямбдами» с поддержкой нескольких синтаксисов.
- Ключам уделяется столько же внимания, сколько значениям: преобразования можно применять и к тем, и к другим; большинство коллбэков принимает на вход и то, и другое; ключи по возможности не теряются при преобразованиях.
- Минимальное изобретение велосипедов: для итерации используются Iterator, IteratorAggregate и др. (и их можно использовать наравне с Enumerable); исключения по возможности используются родные похапэшные и т.п.
- Поддерживается Composer, есть пакет на Packagist.
- Никаких внешних зависимостей.
Что случилось?
Прошёл год, как вышел PHP 5.5 со всякими вкусностями типа генераторов и исправленных итераторов. Так как на моей совести самый полноценный порт LINQ на PHP, то я решил, что настало время его обновить и воспользоваться новыми фичами языка.


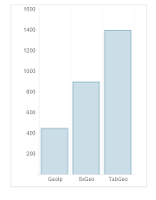 Особенностью данного тестирования является некая приближенность к реальным условиям, когда есть необходимость определять страну одного посетителя на лету за один запуск скрипта, то есть: один запуск скрипта — один ip-адрес. В подобном
Особенностью данного тестирования является некая приближенность к реальным условиям, когда есть необходимость определять страну одного посетителя на лету за один запуск скрипта, то есть: один запуск скрипта — один ip-адрес. В подобном