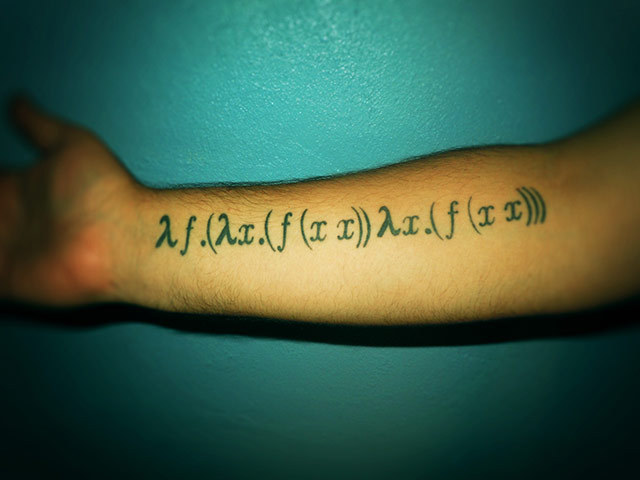Это устройство ставится в электрощиток, измеряет потребляемую мощность, напряжение, а также другие параметры сети и собирает статистику. Данные передаются на Народный мониторинг или по MQTT.


User

Эта история началась в начале марта этого года. ChatGPT тогда был в самом расцвете. Мне в Telegram пришёл Саша Кукушкин, с которым мы знакомы довольно давно. Спросил, не занимаемся ли мы с Сашей Николичем языковыми моделями для русского языка, и как можно нам помочь.
И так вышло, что мы действительно занимались, я пытался собрать набор данных для обучения нормальной базовой модели, rulm, а Саша экспериментировал с существующими русскими базовыми моделями и кустарными инструктивными наборами данных.
После этого мы какое-то время продолжали какое-то время делать всё то же самое. Я потихоньку по инерции расширял rulm новыми наборами данных. Посчитав, что обучить базовую модель нам в ближайшее время не светит, мы решили сосредоточиться на дообучении на инструкциях и почти начали конвертировать то, что есть, в формат инструкций по аналогии с Flan. И тут меня угораздило внимательно перечитать статью.

? Upd. Добавили пример запуска в Colab'е.
Друзья, свершилось. Сегодня мы рады сообщить вам о релизе в открытый доступ нейросетевой модели, которая лежит в основе сервиса GigaChat.
Про то, что такое GigaChat и как мы его обучаем, вы можете прочитать в нашей предыдущей статье. Скажу лишь, что главной его частью, ядром, порождающим креативный ответ на ваш запрос, является языковая модель обученная на огромном количестве разнообразных текстов — сотен тысяч книг, статей, программного кода и т.д. Эта часть (pretrain) затем дообучается на инструкциях, чтобы лучше соответствовать заданной форме ответа. Обучение такого претрейна занимает около 99% от всего цикла обучения и требует значительного количества ресурсов, которыми обычно обладают только крупные компании.
Этот претрейн, названный ruGPT-3.5, мы выкладываем на Hugging Face под лицензией MIT, которая является открытой и позволяет использовать модель в коммерческих целях. Поговорим о модели подробнее.

Компьютерное зрение – это увлекательная область искусственного интеллекта, имеющая огромное значение в реальном мире. Forbes ожидает, что к 2022 году рынок компьютерного зрения достигнет оборота 50 миллиардов долларов, а всех нас ждет новая волна стартапов в этой области [1]. В своей статье я хотел бы поделиться своим опытом и опытом Data Science-команды компании Accenture по созданию цифрового решения потоковой аналитики на базе компьютерного зрения.
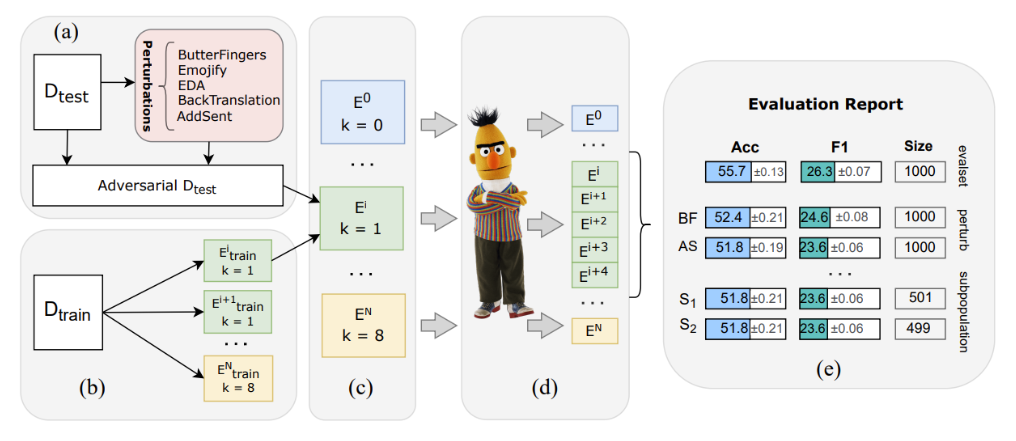
Мы в SberDevices обучаем и оцениваем языковые модели для русского языка уже давно — так, например, за два года существования бенчмарка Russian SuperGLUE через его систему оценки прошли более 1500 сабмитов. Мы продолжаем разрабатывать инструменты для русского языка и в этой статье расскажем, как создали новый бенчмарк, который:
- опирается на оценку моделей в режимах zero-shot и few-shot;
- использует новую библиотеку RuTransform для создания состязательных атак и трансформации данных с учётом особенностей русского языка на уровне слов и предложений — библиотека может быть использована как инструмент для аугментации данных;
- позволяет проводить детальный анализ качества модели на подмножествах тестовой выборки с учётом длин примеров, категории целевого класса, а также предметной области.


Задача контроля водителя очень актуальна в наше время. Должный контроль за состоянием водителей поможет сохранить здоровье автолюбителей, избежать многих дорожно-транспортных происшествий, тем самым снизив количество человеческих жертв.
В конце 2022 года нашей команде поступил запрос на решение данной задачи. Было необходимо предложить подходы, используя которые можно понять, насколько устал водитель, занят ли он какими-либо посторонними делами за рулем, куда он смотрит при выполнении маневров, открыты ли у него глаза (не спит ли он) и т.д.
После продолжительного изучения существующих исследований в данной области, было принято решение начать работу с разработки следующих прототипов.
Мы стоим, как обычно, на пороге очередной технологической революции (я уже запутался какой там номер...). IoT или Интернет вещей принесет новые бизнес модели, новые сценарии использования и приведет к очередному переделу всего рынка телекома.
Как и в любом деле существует куча направлений, конкурирующих решений, технологий — короче каша еще та. И что из этого получится — сложно сказать с полной уверенностью.
Есть несколько системных направлений разработки, как бы некая матрица потребностей, где решения ранжируются по скорости передачи данных и по расстоянию передачи данных. Есть NFC и BLE для платежей. Есть LoRa и ZigBee для датчиков, а есть решения на основе сотовой связи 4G&5G, например LTE-M и NB-IoT.

На мой взгляд (так как я работаю с сотовой связью) самый простой и готовый для развертывания сегмент IoT — это Интернет вещей на базе сотовой сети с использованием eSIM. Вот про это я и расскажу с точки зрения железа и софта, но на уровне "интересно знать".

С наступающим Хабровчане! Есть мнение что, устройство без корпуса нельзя считать законченным и без него оно будет лежать в разобранном виде, собирая пыль. Поэтому в этой финальной части смоделируем и напечатаем на 3D принтере свой корпус.
И наконец – подведём итоги по проекту, сколько было затрачено финансов, допущено ошибок, а также поделюсь с вами своими планами на Хабр и не только

В нашей прошлой статье мы ускорили наши модели в 10 раз, добавили новые высококачественные голоса и управление с помощью SSML, возможность генерировать аудио с разной частотой дискретизации и много других фишек.
В этот раз мы добавили:
eugeny);ё со словарем в 4 миллиона слов и точностью 100% (но естественно с рядом оговорок);Пока улучшение интерфейсов мы отложили на некоторое время. Ускорить модели еще в 3+ раза мы тоже смогли, но пока с потерей качества, что не позволило нам обновить их прямо в этом релизе.
Попробовать модель как обычно можно в нашем репозитории и в колабе.

Привет Хабр! Меня зовут Ильдар. Мне 29 лет. Программирую с 2003 года. За свою жизнь создал 4 фреймворка и язык программирования. В этом посте я поделюсь своим опытом, инсайтами, которые я получил при разработке языка программирования BAYRELL Language. Заранее прощу прощения за возможные синтаксические и пунктуационные ошибки в тексте и отсутствие картинок.