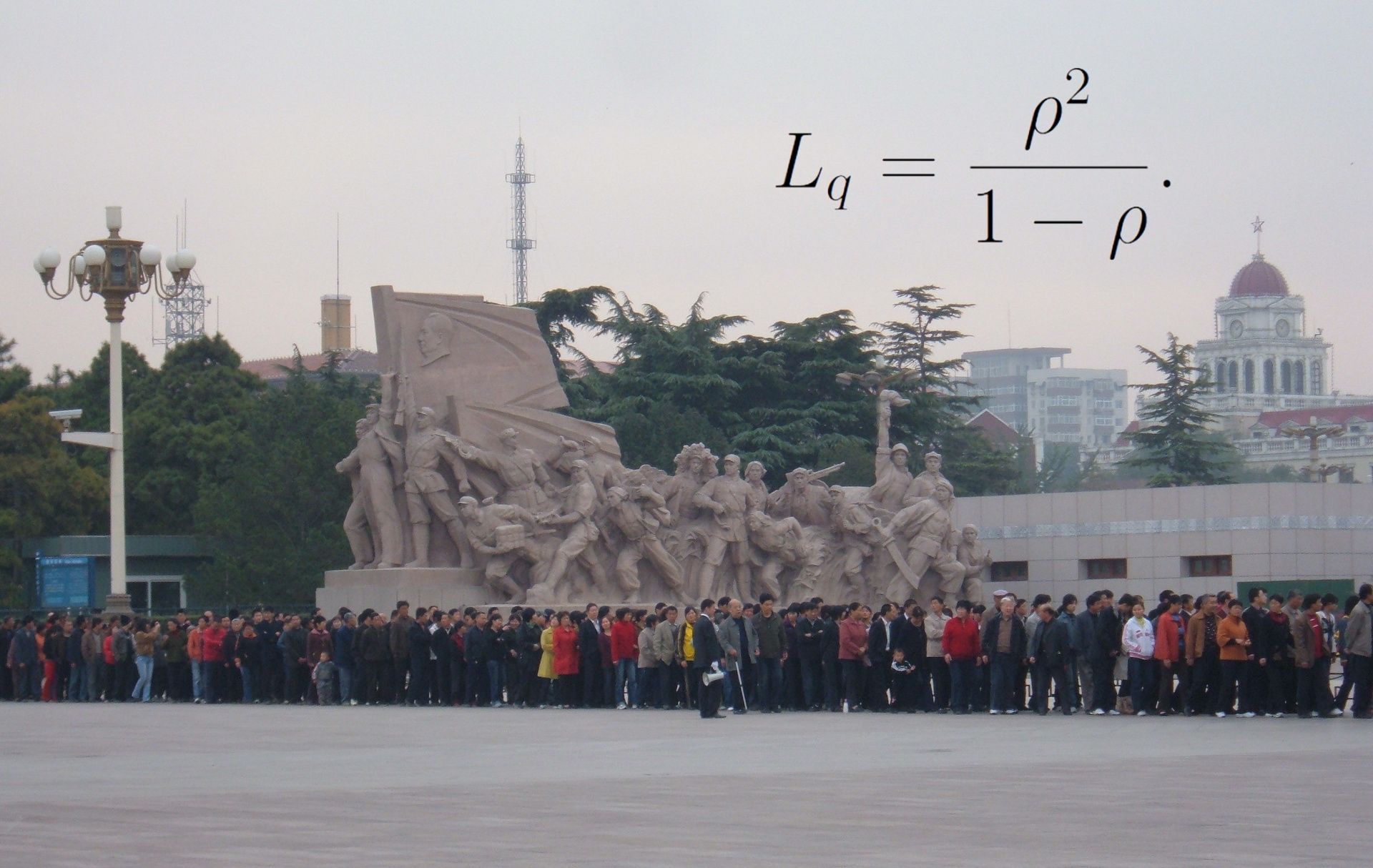Идея микросервиса заключается в том, чтобы строить приложение как набор небольших сервисов с выделенной функциональностью, каждый из которых работает в собственном процессе. Такой подход имеет ряд преимуществ, но не это тема сегодняшнего рассказа, а то, как идея микросервисной архитектуры выглядит
с точки зрения российского корпоративного бизнеса и управленцев IT на предприятиях.
Вместе с
Игорем Беспальчуком постараемся посмотреть на этот тренд с трех разных ракурсов, что очень полезно для понимания природы того, с чем мы имеем дело, и, как следствие, для того, чтобы сделать правильные выводы и принять правильное решение.
Микросервисы — одна из самых важных и значимых составляющих Web-scale архитектуры, имеющая наибольшие последствия для переделки устройства техник и паттернов в Enterprise. Трудно сейчас сказать, на каком участке сейчас находится сама технология — может быть, на самом верхнем пике, и нам предстоит еще десять раз разочароваться. Но, тем не менее, это
не повод не изучать её прямо сейчас.







 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.