
Вот некое простое значение:

И мы знаем, как к нему можно применить функцию:
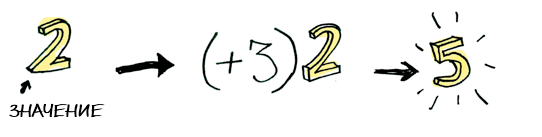
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
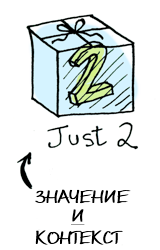
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
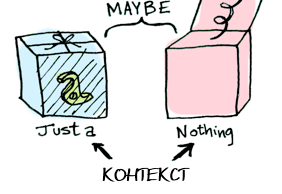
Позже мы увидим разницу в поведении функции для
И мы знаем, как к нему можно применить функцию:
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
Maybe определяет два связанных контекста:data Maybe a = Nothing | Just a
Позже мы увидим разницу в поведении функции для
Just a против Nothing. Но сначала поговорим о функторах!

 Недавно мне довелось разобраться и устранить несколько утечек памяти в популярном фреймворке Торнадо. Не беда, если вы никогда его не использовали, потому что описанное будет мало связано с ним. Рассказать я хочу о методах, которые я использовал для поиска и устранения утечек.
Недавно мне довелось разобраться и устранить несколько утечек памяти в популярном фреймворке Торнадо. Не беда, если вы никогда его не использовали, потому что описанное будет мало связано с ним. Рассказать я хочу о методах, которые я использовал для поиска и устранения утечек. Хороший понедельник, Хабр! Мы продолжаем изучение Erlang для самых маленьких.
Хороший понедельник, Хабр! Мы продолжаем изучение Erlang для самых маленьких. 