
Гуд ньюз эвриван! Спустя полтора года работы восьми айтишников с суммарным опытом в IT 130 лет достигнут результат в виде учебника по тестированию, которого еще никто и никогда не делал.

Разработчик интересных штук
Гуд ньюз эвриван! Спустя полтора года работы восьми айтишников с суммарным опытом в IT 130 лет достигнут результат в виде учебника по тестированию, которого еще никто и никогда не делал.


TLDR — это не готовое решение, это попытка самостоятельно разобраться, подобрать архитектуру и обучить генеративно-состязательную модель (GAN) для увеличения картинок в 2 или 4 раза. Я не претендую на то, что моя модель или путь рассуждений лучше каких-то других. Кроме того, относительно недавно стали популярны трансформеры и diffusion модели — заметки не про них.
С заметками не получилось линейной структуры повествования — есть отступления "в сторону" и уточнения. Можно пропускать нерелевантные заметки. Например, описание подготовки данных нужно, если вы хотите воспроизвести эксперименты — а в остальных случаях можно пропустить. Я написал каждую отдельную заметку по-возможности цельной и независимой от других.
Я уже был знаком со свёрточными сетками, но мне хотелось попробовать генеративно-состязательные сети. Понять, почему используют те или иные подходы. Попробовать свои идеи. Посмотреть, насколько быстро можно научить модель и насколько хорошо она будет работать.
Для обучения оказалось достаточно возможностей моего ПК. Какие-то простые эксперименты занимали десятки минут или несколько часов, самый длинный с обучением финальной большой модели — трое суток.

Вы, наверное, слышали про dalle-2, midjourney, stable diffusion? Слышали о моделях, которые по тексту генерируют картинку. Совсем недавно они продвинулись настолько, что художники протестуют, закидывая в стоки картинки с призывом запретить AI, а недавно, вообще, в суд подали! В этой статье будем разбираться, как такие модели работают. Начнем с азов и потихоньку накидаем деталей и техник генерации.

Поветрия
Я наблюдаю за развитием IT в течение приблизительно четверти века, и с каждым днём меня всё сильнее удручает происходящее.
Постоянно мы слышим, что какой-нибудь паттерн или язык становится всё более модным, а что-то, напротив, — уходит в историю. А ещё различные поветрия о "хорошо или плохо" будто волнами перекатываются через это вот всё.
Кто-нибудь скажет, что это — естественный ход событий — просто одна технология заменяет другую. И он будет прав и неправ одновременно.
Увы, новые вещи (коих не так чтобы вообще есть) всё чаще приносят с собой и очевидно деструктивные, будто навязываемые извне, паттерны.
В прошлом частота таких деструкций была невысокой, но выглядит так, что она нарастает по экспоненциальной кривой.
В этой статье я хотел бы поговорить о причинах происходящего.

В пост включены библиотеки, которые были запущены или приобрели популярность в этом году, хорошо поддерживаются, а также просто классные и достойные внимания. Подборка в значительной степени ориентирована на библиотеки по ИИ и науке о данных, но сюда так же включен ряд библиотек, которые могут быть полезны для целей, не связанных с наукой о данных.

Open-source проекты, сторонние инструменты и библиотеки - это то, за что мы действительно любим Python. В этой статье я собрал самые полезные, валидированные сообществом и проверенные временем инструменты, конфигурации которых можно встретить в популярных проектах с открытым исходным кодом.
Инструменты распределены по этапам/сферам разработки. По каждому из них я дам небольшое описание и попытаюсь рассказать о его пользе. Если утилита имеет дополнительные расширения/плагины, то я расскажу про самые полезные (на мой взгляд).

Я люблю давать простые задачки студентам на лекции. Во-первых, понятно, скольких мы потеряли, во-вторых, это переключение из режима потребления информации в режим выдачи результатов, в третьих — возможность проявить себя для шустрых. Сплошные плюсы!
Одна из простых задач звучит так: «При переводе картинки из цветового пространства RGB в YUV мы выполняем прореживание, то есть выкидываем каждый четный столбец и каждую четную строку в компонентах U и V (все компоненты пикселя по 1 байту). Вопрос: во сколько раз меньше данных у нас стало?» Эта операция называется chroma subsampling и широко используется при сжатии видео, например.
Забавно, что когда-то давно, когда винчестеры были меньше, а дискеты больше, студенты реально отвечали на этот вопрос быстро. А в последние годы регулярно народ в ступор впадает. Приходится разбирать по частям: «Если выкинуть каждую четную строку и каждый четный столбец, во сколько раз меньше данных будет у компоненты?» Почти хором: «В четыре». Начинаю подкалывать: «Отлично! У нас было 3 яблока, первое осталось как есть, а от второго и третьего осталось по четвертинке. Во сколько раз меньше яблок у нас стало?» Народ ржет, но, наконец-то, дает правильный ответ (заметим, не все).
Это было бы смешно, если бы от способности быстро в уме прикинуть результат не зависела способность быстрее создавать сложные алгоритмы.
И хорошо видно, как эта способность в широких массах студентов заметно плавно падает. Причем не только в нашей стране. Придуман даже специальный термин: «цифровое слабоумие» ("digital dementia") — снижение когнитивных способностей, достаточно серьезное, чтобы повлиять на повседневную деятельность человека.
Кому интересно как теряют мозг студенты масштабы бедствия и что с этим делать — добро пожаловать под кат!

В статье на примере определения интента по фразе клиента, полученной в текстовом виде показаны подходы для решения поставленной задачи, выбор метрик и моделей.
Сделан обзор на актуальные подходы для ускорения работы нейронных сетей, представлены библиотеки ONNX и ONNX Runtime.
Проведены тесты с использованием фреймоворков ONNX и ONNX Runtime, используемых для ускорения работы моделей перед выводом их в продуктовую среду.
Представлены графические зависимости и блоки кода.

Некоторые издательства журналов предлагают доступ к научным статьям сразу после публикации, а некоторые через какое-то время.
Однако стоимость одной статьи от платных издателей может составлять 150 долларов, что не так уж и мало по сравнению с размером стипендии студента.
Здесь собраны совершенно бесплатные ресурсы, где вы можете найти интересующую Вас научную статью.
В связи с уникальной сложившейся политической ситуацией в Российской Федерации, меня отключили от моей честно оплаченной подписки на сервис Netflix. Также, с уходом больших кинокомпаний с российского рынка, не остается большой надежды на трансляцию свежего кино и сериалов в отечественных онлайн кинотеатрах. Поэтому я принял волевое решение создать домашний сервер для видеохостинга, а также скачивания и раздачи торрентов на одноплатном компьютере Raspberry Pi, который был куплен по наитию и, как и у тысяч программистов-энтузиастов по всему миру, лежал без дела который год.


В этой статье я хочу поделиться недавно открытым для себя инструментарием, позволяющим создавать кроссплатформенные автотесты для приложений на QT.
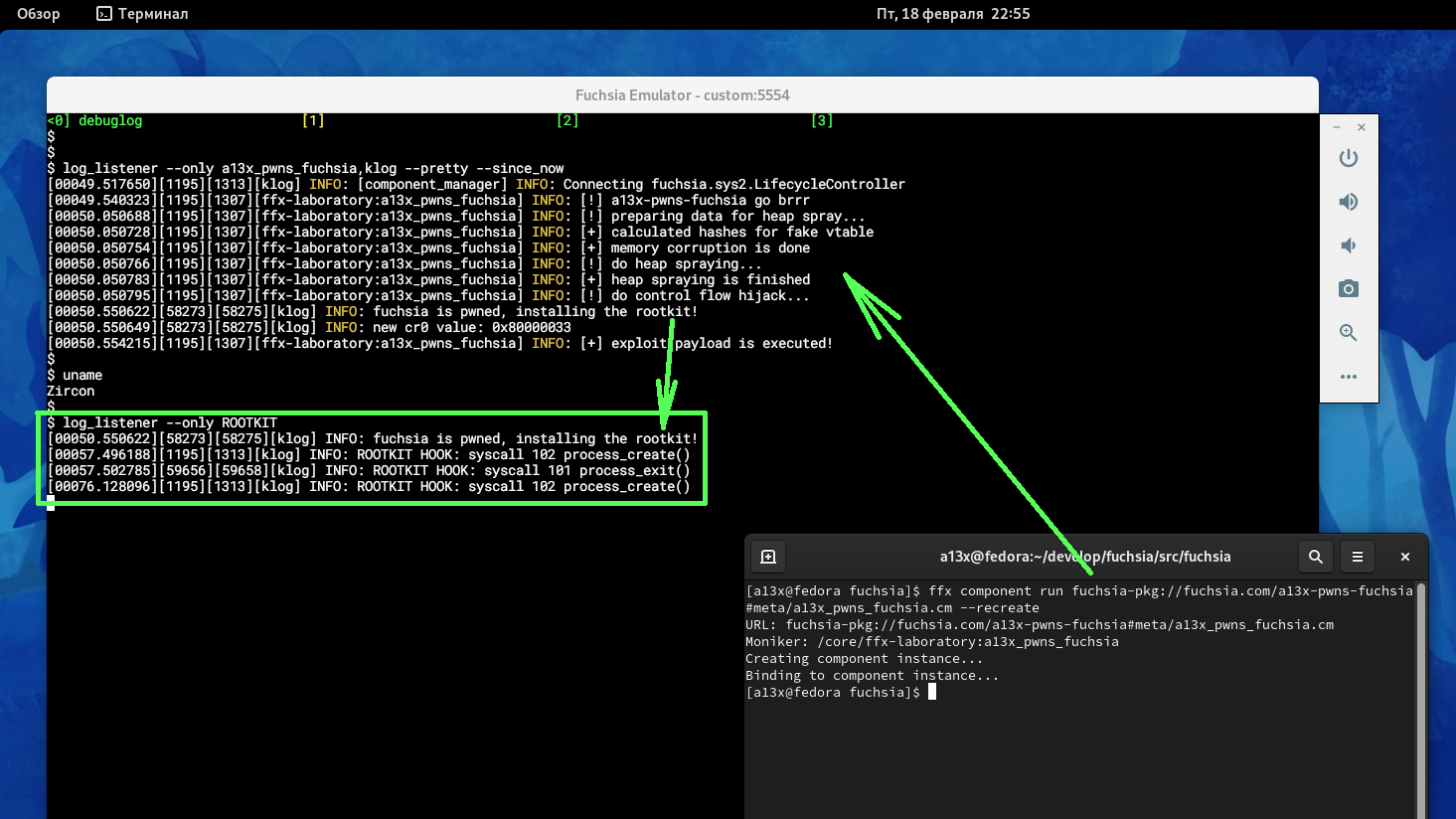
Fuchsia — это операционная система общего назначения с открытым исходным кодом, разрабатываемая компанией Google. Эта операционная система построена на базе микроядра Zircon, код которого написан на C++. При проектировании Fuchsia приоритет был отдан безопасности, обновляемости и быстродействию.
Как исследователь безопасности ядра Linux я заинтересовался операционной системой Fuchsia и решил посмотреть на нее с точки зрения атакующего. В этой статье я поделюсь результатами своей работы.

Предупреждение: в статье присутствуют заголовки реальных новостей. Я отношусь к ним исключительно как к рабочему материалу, не представляю какую-либо точку зрения на политическую или экономическую ситуацию в какой бы то ни было стране.
https://fakt309.github.io/thisisthewall/
В языках программирования строки сравниваются очень просто, если строка отличается хотя бы на один символ, то возвращает false.
Но вот что если мы хотим не просто получать дискретное значение (true / false), а дифференцированное, например в процентах. Ведь согласитесь строки test и testing гораздо ближе к друг другу, чем test и abcd. Для данной проблемы существует множество решений, мы поговорим о самый популярных алгоритмах (также об их модификациях):
Расстояние Хэмминга
Расстояние Левенштейна
Сходство Джаро — Винклера
Коэффициент Сёренсена
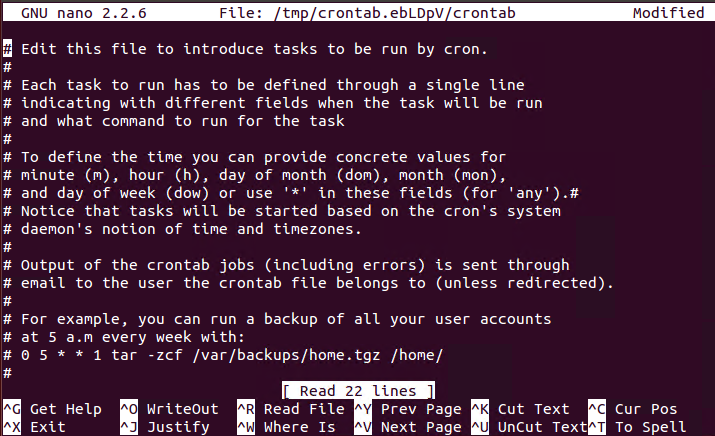
Планировщик задач cron(8) существует с 7 версии Unix, а его синтаксис crontab(5) знаком даже тем, кто нечасто сталкивается с системным администрированием Unix. Это стандартизированный, довольно гибкий, простой в настройке и надёжно работающий планировщик, которому пользователи и системные пакеты доверяют управление важными задачами. Материалом о лучших практиках работы с cron делимся к старту курса по Fullstack-разработке на Python.



Была у меня мечта - писать backend на C++. А вот разбираться в unix socket'ах, TCP, многопоточной/асинхронной обработке запросов и во многом другом совсем не хотелось. Не верил я, что до сих пор нет каких-то минималистичных фреймворков. И сегодня я вам расскажу, как можно просто сделать HTTP API микросервис на C++ с помощью фреймворка Drogon.