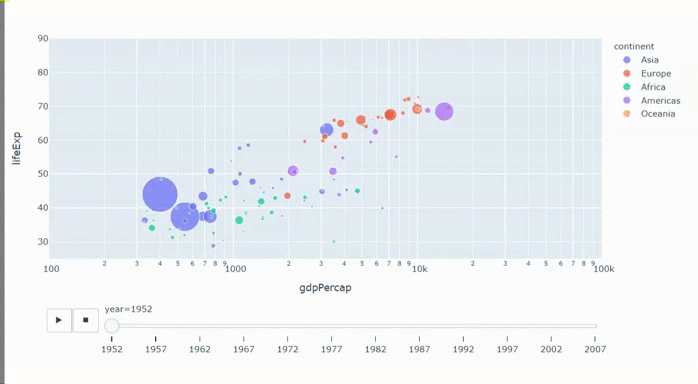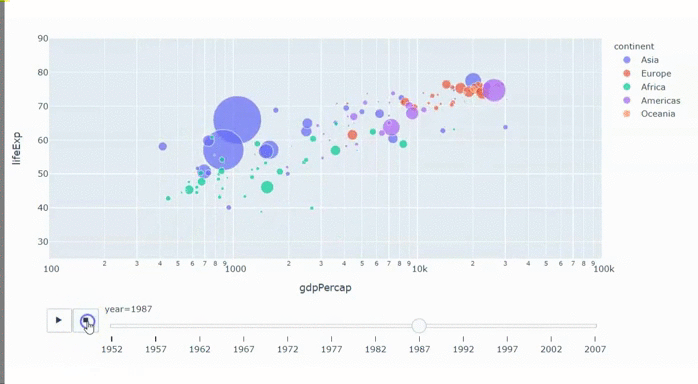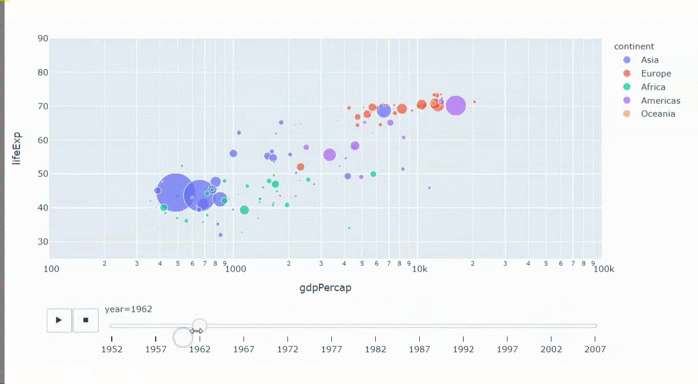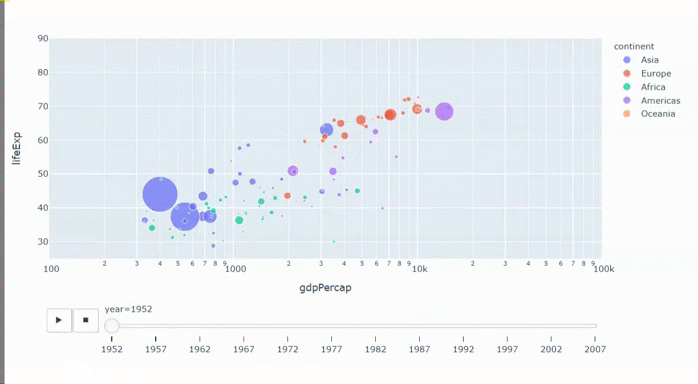
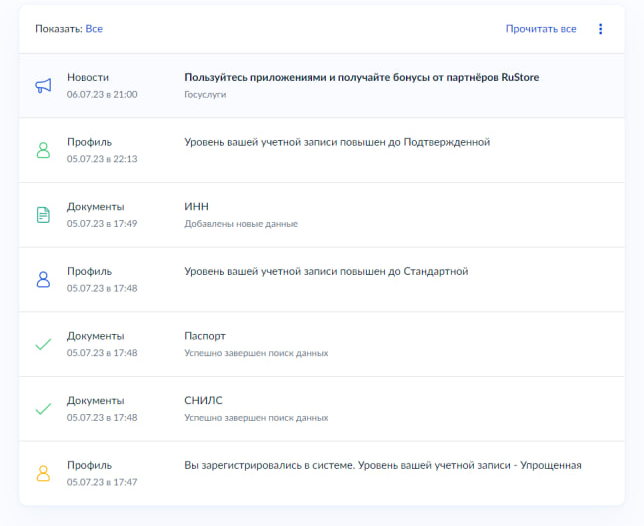
Я был достаточно неосмотрителен, чтобы эта история произошла со мной, но, возможно, достаточно технически грамотен, чтобы рассказать ее детали, сдерживая эмоции и понимая, что происходит, в отличии от большинства людей, оказашимихся в этой ситуации еще и с ощущением полного неведения.
Когда появились госуслуги, на них не было автоматического информирования о входах в аккаунт с непривычного IP, не предлагалась двухфакторная авторизация. Я создал пароль достаточно надежный - не использованный нигде ранее, и считал,что все отлично, не меняя его 5 лет. На портал заходил я редко, но авторизовывал через ЕСИА государственные сервисы. Госуслуги присылали рассылки на почту, а я был уверен, что при авторизации с подозрительного IP или попытки брутфорса меня уведомят, а аккаунт заблокируют, ведь телефонный номер Госуслуги и так знают.
По-видимому, пароль от Госуслуг мне пришел в голову еще раз в качестве пароля от какого-то сайта, где я зарегистрировался с той же почтой, и с тех пор пара "почта-пароль" слилась в базы злоумышленников. Это все, что вам нужно знать о причинах произошедшего. Теперь о последствиях.
Утром 11 июля мне потребовалось авторизоваться на сайте Госуслуг, но "пользователь с таким email не зарегистрирован". Я набрал службу поддержки, назвал свой номер СНИЛС, а мне (не спрашивая всяких контрольных вопросов, что в моем случае было как раз хорошо) техподдержка заявила, что с этим номером СНИЛС аккаунт заведен 5 июля, почта и телефон там другие, а тот, в котором была ваша почта и телефон, удалены того же числа.