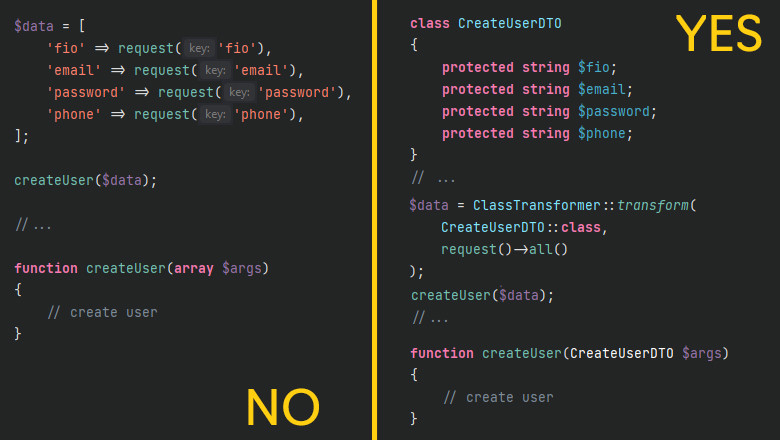
В последнее время было немало горестных рассуждений о последствиях
решения Google использовать HTML-элемент <canvas> для рендеринга всего, что видно на экране при работе с Google Docs. И то, что это многих беспокоит, вполне понятно. Когда-то веб был задуман как система для работы с тщательно структурированной информацией, полной осмысленных метаданных и рассчитанной на совместное её использование многими людьми. Но, вместо этого, тот веб, который мы видим сегодня, представляет собой довольно сложно и запутанно устроенные приложения, которые работают в браузерных «песочницах».
Решение Google, которое заключается в том, чтобы перейти от вывода на страницы HTML-элементов к рисованию пикселей на <canvas>, нельзя назвать чем-то таким, чего раньше никто не видел и не пробовал. Другие передовые веб-приложения уже вышли далеко за пределы традиционных схем работы с HTML-элементами. Так, в Google Maps вывод данных на <canvas> используется уже многие годы. В VS Code для отрисовки идеального интерфейса
терминала тоже используется <canvas>. А в подающем надежды наборе инструментов Google Flutter, который позволяет создавать кросс-платформенные интерфейсы, в веб-браузере, по умолчанию, используется
рендеринг с использованием <canvas>.
Но в этот раз происходящее вызывает несколько иные ощущения. А именно, появляется такое чувство, что рендеринг в <canvas> и другие современные технологии, вроде WebAssembly, увели нас за точку невозврата. Все привыкли к схеме работы, когда страница загружает, в виде обычного текста, JavaScript-код, который выполняется, взаимодействуя с HTML-элементами, видимыми в «инструментах разработчика». Сейчас возникает такое впечатление, что это — лишь небольшой этап на пути постоянно развивающихся технологий веб-разработки.