Генератор случайных чисел во многом подобен сексу: когда он хорош — это прекрасно, когда он плох, все равно приятно (Джордж Марсалья, 1984)
Популярность стохастических алгоритмов все растет. Многие из них базируются на генерации большого количества различных случайных величин. Далеко не всегда равномерно распределенных. Здесь я попытался собрать информацию о быстрых и точных генераторах случайных величин с известными распределениями. Задачи могут быть разными, разными могут быть и критерии. Кому-то важно время генерации, кому-то — точность, кому-то — криптоустойчивость, кому-то — скорость сходимости. Лично я исходил из предположения, что мы имеем некий базовый генератор, возвращающий псевдослучайное целое число, равномерно распределенное от 0 до некого RAND_MAX
unsigned long long BasicRandGenerator() {
unsigned long long randomVariable;
// some magic here
...
return randomVariable;
}
и что этот генератор достаточно быстрый. Я имею ввиду, что дешевле сгенерировать с десяток случайных чисел, нежели чем посчитать логарифм или возвести в степень одно из них. Это могут быть стандартные генераторы: std::rand(), rand в MATLAB, Java.util.Random и т.д. Но имейте ввиду, что подобные генераторы редко подходят для серьезной работы. Зачастую они проваливают разные статистические тесты. А также, помните, что вы полностью зависите от них и лучше использовать свой собственный генератор, чтобы иметь представление о его работе.
В статье я буду рассказывать об алгоритмах, суть которых должна быть понятна каждому, кто хоть иногда сталкивался с теорией вероятностей. Совсем необязательно быть знакомым с теорией меры, как правило, достаточно примерно понимать, что из себя представляют функция распределения и функция плотности распределения:
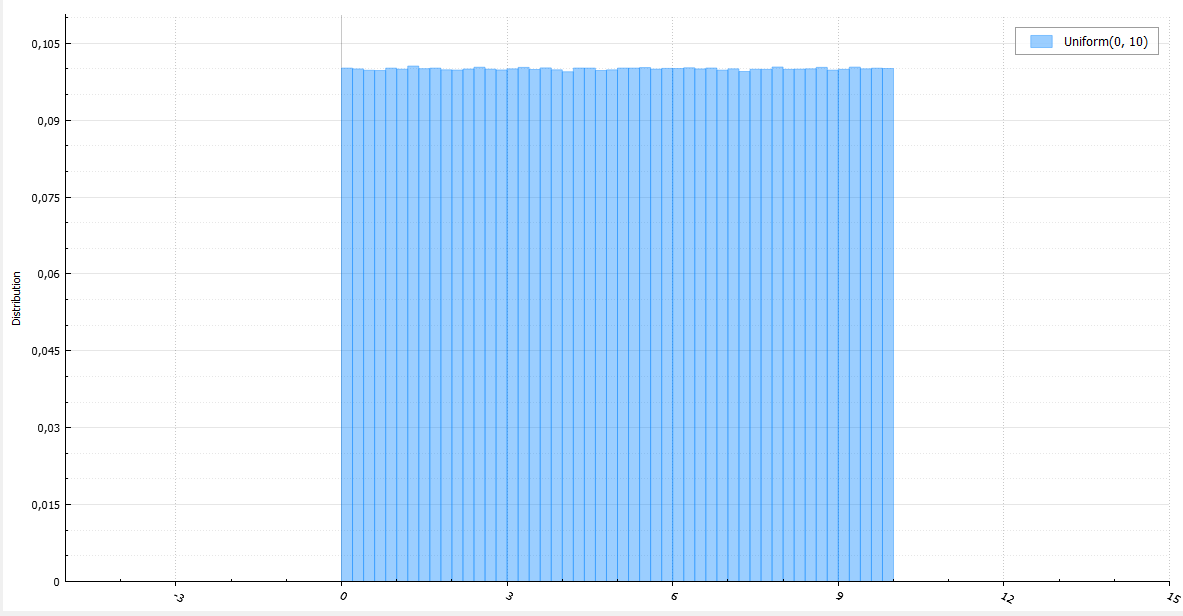
Каждый алгоритм я буду сопровождать кодом, небольшим количеством математики и гистограммой из десятка миллионов сгенерированных случайных величин.
Равномерное распределение


 Изображение предоставлено автором. Основано
Изображение предоставлено автором. Основано 

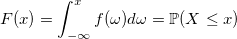
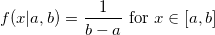
 (с) xkcd
(с) xkcd

 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как 