Многие слышали о высокоуровневом поисковом сервере
ElasticSearch, но не все знают, что многие используют его не совсем по прямому назначению. Речь идет о реалтайм-аналитике различных структурированных и не очень данных.
Эта статья также назрела ввиду того, что многие крупные интернет-проекты рунета в 2014 году получили письма счастья от Google Analytics с предложением заплатить $150 000 за возможность использовать их продукт. Я лично считаю, что ничего плохого в том, чтобы оплатить труд программистов и администраторов нет. Но при этом это довольно серьезные инвестиции, и, может, вложения в собственную инфраструктуру и специалистов, даст большую гибкость в дальнейшем.
Аналитика в ElasticSearch основана на полнотекстовом поиске и фасетах. Фасеты в поиске — это некая агрегация по определенному признаку. Вы часто сталкивались с фасетами-фильтрами в интернет-магазинах: в левой или правой колонке есть уточняющие галочки. Ниже пример тестового фасетного поиска у нас на главной странице
http://indexisto.com/.
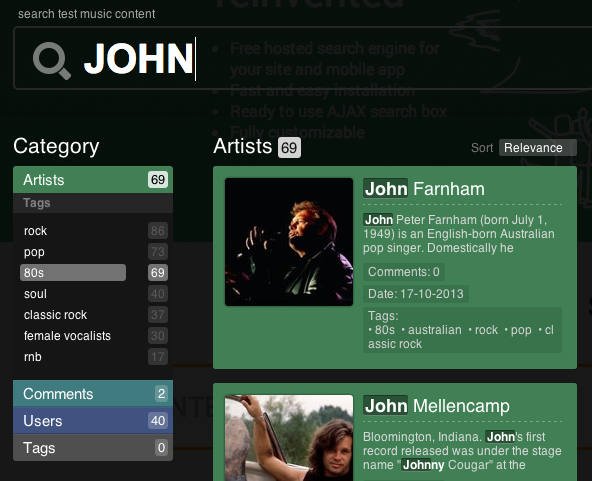
Буквально неделю назад вышла стабильная версия поискового сервера ElasticSearch 1.0, в которой разработчики настолько серьезно поработали над фасетами, что даже назвали их Aggregation.
Так как тема еще не освещалась на Хабре, я хочу рассказать, что из себя представляют аггрегации в ElasticSearch, какие возможности открываются и есть ли жизнь без Hadoop.




 Телекомпания CBC News
Телекомпания CBC News 




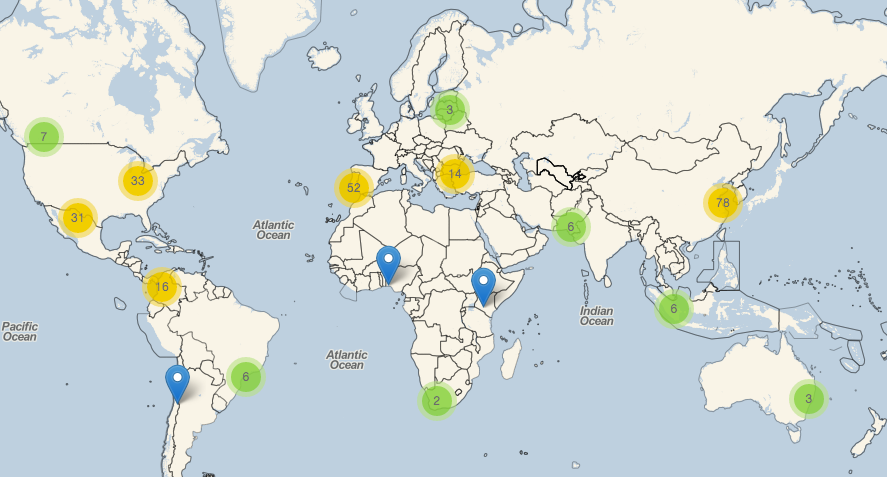
{kind=link}