Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA. Сегодня познакомлю вас с библиотекой Gluon Time Series, которую используют для работы с временными рядами.

Пользователь
Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA. Сегодня познакомлю вас с библиотекой Gluon Time Series, которую используют для работы с временными рядами.

Привет! Меня зовут Василий Копытов, я руковожу группой разработки рекомендаций в Авито. Мы занимается системами, которые предоставляют пользователю персонализированные объявления на сайте и в приложениях. На примере нашего основного сервиса покажу, когда стоит переходить с Python на Go, а когда нужно оставить всё как есть. В конце дам несколько советов по оптимизации сервисов на Python.

Мы, команда NtechLab, постараемся понятным языком рассказать, из чего на самом деле состоят самые современные алгоритмы распознавания лиц, с которыми каждый из нас сталкивается в повседневной жизни, порассуждаем, на что они способны и на что — пока нет, и попробуем ответить на вопросы о том, когда технология работает хорошо, а когда плохо, и от чего это зависит.

Мы хотим познакомить вас с самым авторитетным на сегодняшний день «чемпионатом мира» по распознаванию лиц, NIST Face Recognition Vendor Test (FRVT) — что он из себя представляет, для чего создан, как проходит соревнование и главное, насколько он действительно важен для разработчиков и бизнеса.

Последние 15 лет профессор Колумбийского университета Йохан де Йонг посвятил тому, что собирал основополагающие теоремы алгебраической геометрии в одном месте. Его творение, Stacks Project, предлагает новую модель организации и визуализации математических сведений.
К старту флагманского курса по Data Science рассказываем о проекте профессора.

Правильное построение ETL-процессов (преобразования данных) — сложная задача, а при большом объёме обрабатываемых данных неизбежно возникают проблемы с ресурсами. Поэтому нам требуется выискивать новые архитектурные решения, способные обеспечить стабильность расчётов и доступность данных, а при необходимости и масштабируемость — с минимальными усилиями.
Когда я пришел в Ozon, мне пришлось столкнуться с огромным количеством ETL-джоб. Прежде чем применить модель машинного обучения, сырые данные проходят множество этапов обработки. А само применение модели (то, ради чего существует команда) занимает всего 5% времени.
Генерация 3D-моделей из текстового описания и видеозаписей, сделанных на обыкновенный смартфон, конкурент DALL-E, ускоренная GAN-инверсия и многое другое в подборке материалов за декабрь, а также небольшие новости о будущем дайджеста.

В качестве предисловия оговорюсь, что на Хабре я впервые, решил представить свою дебют на этой платформе, так сказать. Речь здесь не пойдёт о рисовании картин с использованием AI и графических паттернов. Скорее наоборот, превращение классического изобразительного исксства в многочисленную последовательность нейронных сетей в итоговым кодом в заключительном виде. Расскажу предысторию. В начале этого года, случайным образом, попало в моё поле зрения одно заманчивое словосочетание - digital art. И так как я в теме crypto уже давненько, я не смел не поинтересоваться, каким образом искусство (будь то живопись или музыка) коррелирует с криптой, и как это происходит (и для чего))) на просторах блокчейна. В итоге ознакомления с этой идеей, и не только идеей, но и инфраструктурой NFT (Non-Fungible-Token, невзаимозаменяемый цифровой актив), я с радостью обнаружил что уже хочу создать что-то подобное, но в своём, авторском исполнении. Парой слов опишу, что зверёк по имени НФТ это хэшированное изображение в любом формате, записанное в сети блокчейн в формате, являющегося аналогом ERC-721 в сети Ethereum (для тех кто ещё не в курсе темы). Задуманному быть конечно, но сказать легко, а вот сделать - труднее. Особенно, когда делаешь что-то впервые. Начал я с изучения подобных платформ на просторах всемирной паутины, начиная с крупнейших маркетплейсов opensea.io, makersplace.com, и не очень крупных, pixeos.art, ghostmarket.io и много много других.
Кроме маркетплейсов, я обнаружил чисто minting-платформы, как правило тематические, т.е. они занимаются только созданием NFT карточек и как-правило одного направления. Криптокотики всякие (с них всё и началось!), Криптопанки и прочая фауна. Нашлось кроме всего пару аутсайдеров, которые вовсе создавали неформатные NFT, с прицелом на автоматическое масштабирование за счёт пользователей, к примеру на одной из платформ за NFT контент принимаются уникальные ссылки в интернете, на другой - регистрируются домены, а заодно и снимок с NFT. Не буду сильно углубляться в обозревание ежедневно растущего формата цифровых активов NFT, а лучше наконец-то перейду к своей задумке.
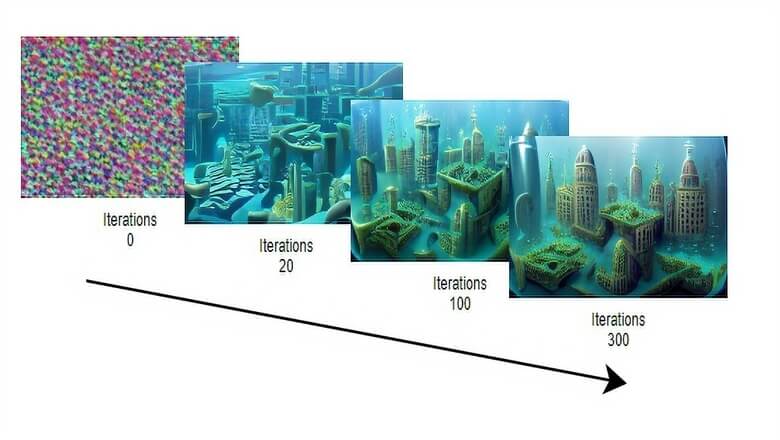
Автор статьи рассказывает, как за неделю создал Text2Art.com — генератор изображений на основе VQGAN+CLIP, способный рисовать пиксель-арт и живопись, а также изображать то, что вы напишете в текстовом поле.
Для интерфейса используется Gradio, модель работает на сервере FastAPI, а системой очереди сообщений служит Firebase. Подробностями делимся к старту курса по ML и DL.

Курсы упорядочены по степени необходимости, начиная с базовых знаний, без которых будет тяжело даваться дальнейшее изучение (линейная алгебра, статистика, базовое знание python и т.д.), переходя к более сложным. Старался избавиться от избыточности, оставляя только самые ценные, на мой взгляд, курсы. Эти бесплатные курсы легко заменят вам платные.
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: "inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null". Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.

В русском языке порядок слов в предложении практически не важен.
«Я тебя люблю», «Я люблю тебя», «Тебя я люблю», «Люблю я тебя». Нюансы есть, но при этом каждый из этих вариантов грамматически правильный.
В английском все не совсем так. Есть фраза «I love you», а «You love I» — уже нет, так говорить неправильно. Вот только в английском есть свои способы, как сделать язык богаче и не привязываться к жесткой структуре «подлежащее-глагол-сказуемое».
Об этом сегодня и поговорим. Как правильно организовать порядок слов в английском предложении и не показаться скучным. Спойлер: «опсашком» в заголовке — это не описка, а реальный мнемонический инструмент. Обо всем расскажем в статье.

Рассказываем как перестать переживать о том, что вы не знаете Hadoop и вывести работу с данными в компании на новый уровень, как быстро и без больших затрат создать в аналитическое хранилище, наладить процессы загрузки туда данных, дать возможность аналитикам строить отчеты в современных BI инструментах и применять машинное обучение.

ROS - самая популярная открытая робототехническая платформа в настоящий момент. Я и мои коллеги в Samsung Research - основные контрибьюторы Navigation2 Stack, важнейшего компонента ROS, который отвечает за движение роботов.
В этой статье я расскажу в целом о ROS, о разрабатываемом нами стеке и о том, как организована коллективная работа над проектом. В заключение - о нашем треке в школе разработчика COMMoN, которую мы со Стивом Масенски из Samsung Research America, лидером проекта ROS2 Navigation Stack, проведем в августе-сентябре этого года в рамках конференции Samsung Open Source Conference Russia. Участники школы получат шанс внести вклад в репозиторий стека и сделать свой коммит в известный проект.


Недавно я начал изучать machine learning. Начал с прекрасного, на мой взгляд, курса от Andrew Ng. И чтобы не забыть, а так же повторить выученное решил создать репозиторий Machine Learning in Octave. В нем я собрал математические формулы для гипотез, градиентных спусков, "cost function"-ов, сигмоидов и прочих фундаментальных для машинного обучения "штук". Так же добавил туда упрощенные и доработанные примеры реализации некоторых популярных алгоритмов (нейронная сеть, линейная/логистическая регрессия и пр.) для MatLab/Octave. Надеюсь эта информация будет полезна для тех из вас, кто планирует начать изучение machine learning-а.