
У меня чудесная IT работа в русской провинции.
К тому же приличная зарплата. Даже по столичным меркам.

Несмотря на это, перед сном я мечтаю. Среди алчных мечт — получать какие-нибудь небольшие деньги за ничего-не-делание.
Ну, чтобы я спал, а денежка шла.
Доллар за день.
И доллар за ночь. Глядишь, за год можно положить под елку очередному сыну очередной iPad (=365*2$).
Понятно, для осуществления мечты нужно иметь Xcode+iPhone. Или Eclipse+Droid. Или VS+Mozart.
Мечты сбываются.
Но не сразу.
К тому же приличная зарплата. Даже по столичным меркам.
Несмотря на это, перед сном я мечтаю. Среди алчных мечт — получать какие-нибудь небольшие деньги за ничего-не-делание.
Ну, чтобы я спал, а денежка шла.
Доллар за день.
И доллар за ночь. Глядишь, за год можно положить под елку очередному сыну очередной iPad (=365*2$).
Понятно, для осуществления мечты нужно иметь Xcode+iPhone. Или Eclipse+Droid. Или VS+Mozart.
Мечты сбываются.
Но не сразу.


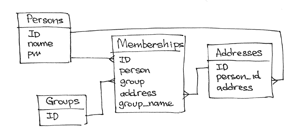 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
 Добрый день, хабровчане! Бесплатный декомпилятор и менеджер сборок от JetBrains ушел в народ – несколько дней назад на нашем сайте стал доступен
Добрый день, хабровчане! Бесплатный декомпилятор и менеджер сборок от JetBrains ушел в народ – несколько дней назад на нашем сайте стал доступен 