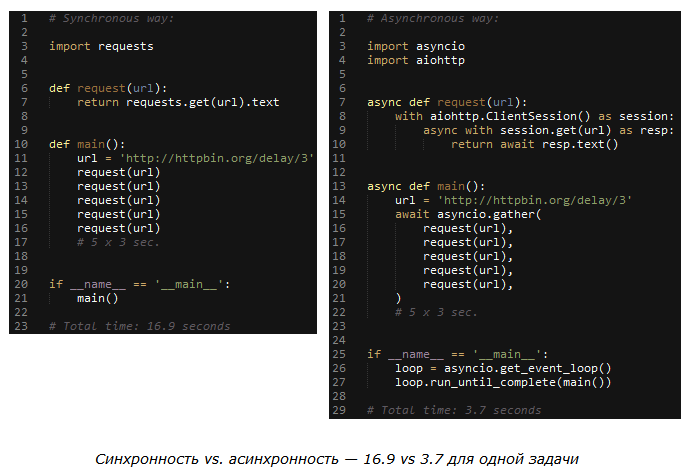
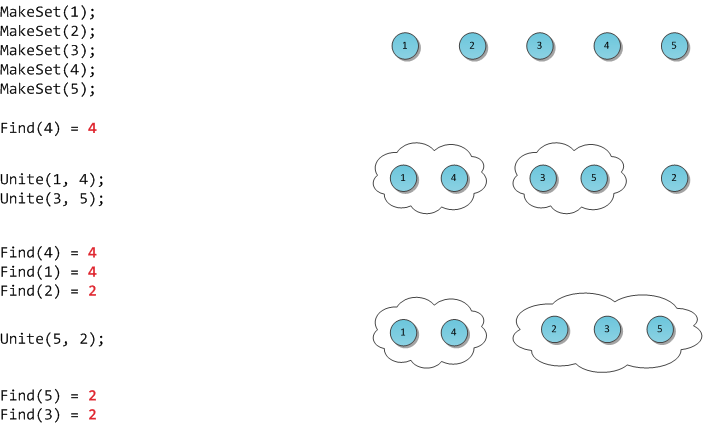
Внутреннее устройство словарей в Python не ограничивается одними лишь бакетами и закрытым хешированием. Это удивительный мир разделяемых ключей, кеширования хешей, DKIX_DUMMY и быстрого сравнения, которое можно сделать ещё быстрее (ценой бага с примерной вероятностью в 2^-64).
Если вы не знаете количество элементов в только что созданном словаре, сколько памяти расходуется на каждый элемент, почему теперь (CPython 3.6 и далее) словарь реализован двумя массивами и как это связано с сохранением порядка вставки, или просто не смотрели презентацию Raymond Hettinger «Modern Python Dictionaries A confluence of a dozen great ideas». Тогда добро пожаловать.
Впрочем, люди знакомые с лекцией, тоже могут найти немного подробностей и свежей информации, и для совсем новичков, не знакомых с бакетами и закрытым хешированием, статья тоже будет интересна.
Если вы не знаете количество элементов в только что созданном словаре, сколько памяти расходуется на каждый элемент, почему теперь (CPython 3.6 и далее) словарь реализован двумя массивами и как это связано с сохранением порядка вставки, или просто не смотрели презентацию Raymond Hettinger «Modern Python Dictionaries A confluence of a dozen great ideas». Тогда добро пожаловать.
Впрочем, люди знакомые с лекцией, тоже могут найти немного подробностей и свежей информации, и для совсем новичков, не знакомых с бакетами и закрытым хешированием, статья тоже будет интересна.



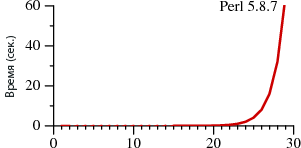
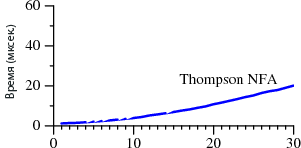
 [@tsafin — Обладателя
[@tsafin — Обладателя 


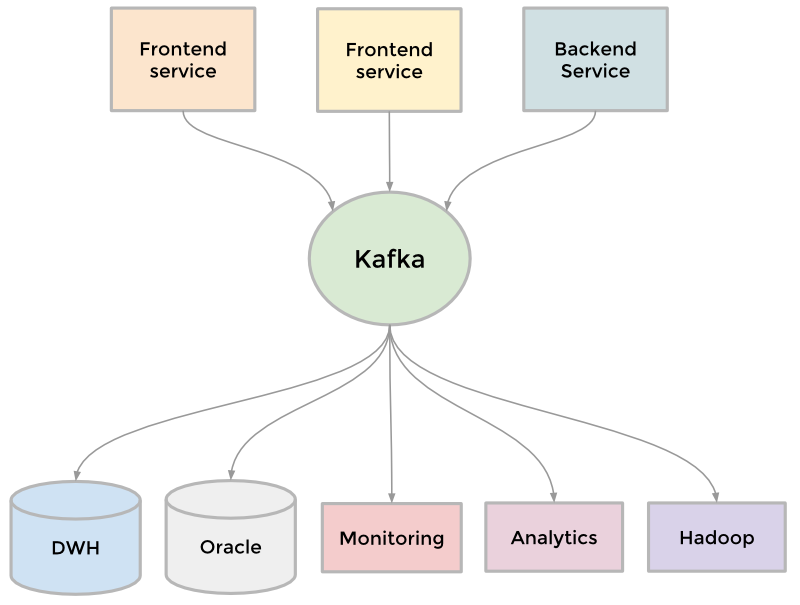
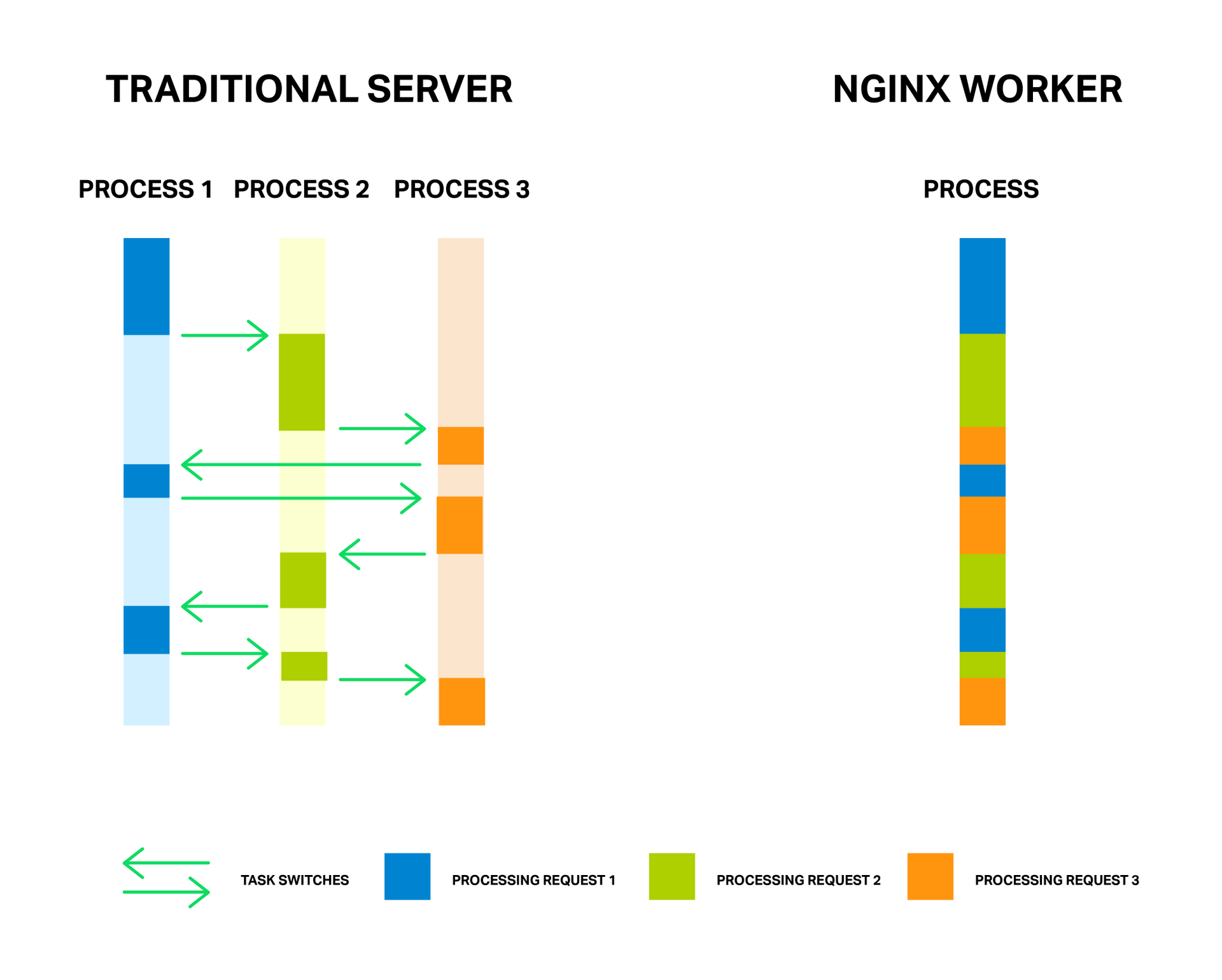
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.