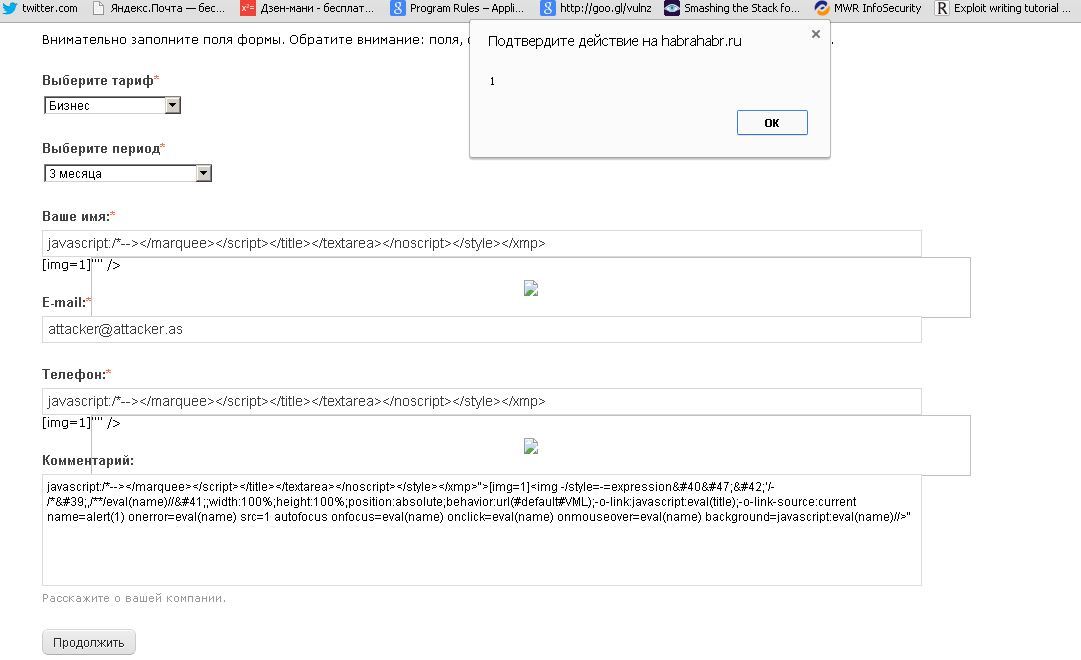
Это, пожалуй, самый болезненный отчет об ошибке, который я когда-либо читал. Он красочно описывает шаги, которые привели к потере 465 миллионов долларов компанией Knight Capital в связи с ошибкой программного обеспечения, проявившейся в прошлом году и обанкротившей компанию.
В этом отчете есть все характеристики технического долга в огромной, лишенной поддержки и запущенной базе кода (ошибка произошла из-за исполнения кода, который не использовали почти 9 лет) и ужасная и грустная история взаимодействия между разработчиками ПО и ИТ-профессионалами.
В этом отчете есть все характеристики технического долга в огромной, лишенной поддержки и запущенной базе кода (ошибка произошла из-за исполнения кода, который не использовали почти 9 лет) и ужасная и грустная история взаимодействия между разработчиками ПО и ИТ-профессионалами.
 Кто пишет на Node.js и использует MySQL, тот непременно знает, что наш дорогой товарищ
Кто пишет на Node.js и использует MySQL, тот непременно знает, что наш дорогой товарищ 
 и
и  ).
).
 От переводчика: Это одиннадцатая статья из
От переводчика: Это одиннадцатая статья из 



 От переводчика: Это первая статья из
От переводчика: Это первая статья из