
Привет, Хабр! Я Артем Чаадаев, Golang-разработчик в МТС Digital. В этой статье я собрал примеры использования конкурентного кода в Go. Хотите узнать, как писать конкурентный код? Значит, вам сюда.
Добро пожаловать под кат!

User
Привет, Хабр! Я Артем Чаадаев, Golang-разработчик в МТС Digital. В этой статье я собрал примеры использования конкурентного кода в Go. Хотите узнать, как писать конкурентный код? Значит, вам сюда.
Добро пожаловать под кат!

Привет, Хабр! Я работаю старшим Go-разработчиком в «Лаборатории Касперского». Сегодня хочу поговорить о том, как искать узкие места и оптимизировать код на Go. Разберу процесс профилирования и оптимизации на примере простого веб-сервиса — покажу, с помощью каких встроенных инструментов искать функции, активнее всего использующие CPU и память. Расскажу, какие можно применять подходы, чтобы повысить производительность. Хотя речь пойдет о микрооптимизации, в моем примере шаг за шагом производительность удалось поднять в 5 раз!
Когда в пятый раз у тебя появляется на работе падаван, которому надо все рассказать по нескольку раз, в какой-то момент приходит в голову светлая мысль все свои речи законспектировать, попутно хоть немного структурировав все это дело. Так что сия заметка о сontainerd для того, чтобы не повторяться в сотый раз. Возможно, кому-то еще это будет интересно, хотя тут все без рокет-сайнс.
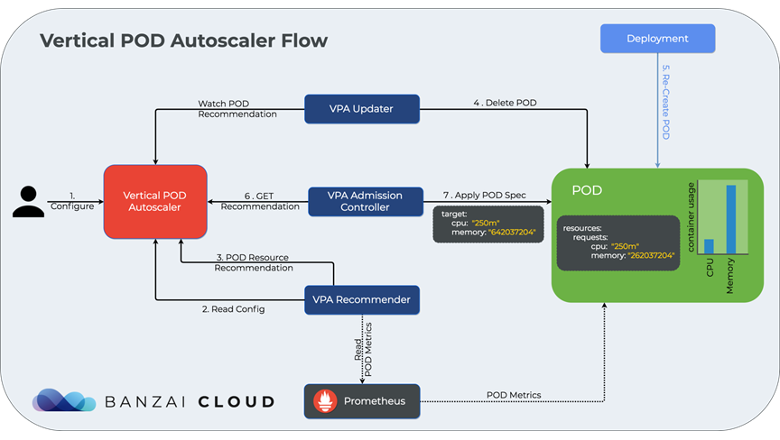
Прим перев.: месяц назад Povilas Versockas, CNCF Ambassador и software engineer из Литвы, написал очень подробную статью о том, как работает и как использовать VPA в Kubernetes. Рады поделиться её переводом для русскоязычной аудитории!
Это полное руководство по вертикальному автомасштабированию pod'ов (Vertical Pod Autoscaling, VPA) в Kubernetes. Из него можно узнать, что такое вертикальное автомасштабирование pod'ов, зачем оно нужно и как работает, как устроена модель ресурсных требований Kubernetes, когда использовать VPA и какие существуют ограничения.

Kubernetes отличная платформа как для оркестрации контейнеров так и для всего остального. За последнее время Kubernetes ушёл далеко вперёд как по части функциональности так и по вопросам безопасности и отказоустойчивости. Архитектура Kubernetes позволяет с лёгкостью переживать сбои различного характера и всегда оставаться на плаву.
Сегодня мы будем ломать кластер, удалять сертификаты, вживую реджойнить ноды и всё это, по возможности, без даунтайма для уже запущенных сервисов.

Мир сходит с ума, заталкивая калькулятор для 2+2 в облака. Чем мы хуже? Давайте Hello World затолкаем в три микросервиса, напишем пару-тройку тестов, обеспечим пользователей документацией, нарисуем красивый пайплайн сборки и обеспечим деплой в условный облачный прод при успешном прохождении тестов. Итак, в данной статье будет показан пример того, как может быть построен процесс разработки продукта от спецификации до деплоя в прод. Инетересно? тогда прошу под кат
Почему мы вообще хотим писать конкурентный код? Потому что процессоры перестали расти по герцовке и начали расти по ядрам. С каждым годом увеличивается количество ядер процессора, и мы хотим их эффективно утилизировать. Go — тот язык, который создан для этого. В документации так и написано.
Мы берём Go, начинаем писать конкурентный код. Конечно, ожидаем, что легко сможем обуздать мощь каждого ядра нашего процессора. Так ли это?
Меня зовут Артемий. Этот пост — вольная расшифровка моего доклада с GopherCon Russia. Он появился как попытка дать толчок людям, которые хотят разобраться, как писать хороший, конкурентный код.
Видео с конференции GopherCon Russia

type Status uint32
const (
StatusOpen Status = iota
StatusClosed
StatusUnknown
)StatusOpen = 0
StatusClosed = 1
StatusUnknown = 2

 Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.
Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.
К сожалению, некоторые невысокие программисты всерьёз полагают, что Dockerfile с какой-нибудь вообще любой командой внутри — это уже сам по себе микросервис и его можно деплоить хоть сейчас. Докеры крутятся, лавешка мутится. Такой подход оборачивается проблемами начиная с падения производительности, невозможностью отладки и отказами обслуживания и заканчивая кошмарным сном под названием Data Inconsistency.
Если вы ощущаете, что пришло время запустить ещё одну аппку в Kubernetes/ECS/whatever, то мне есть чем вам возразить.
English version is also available.

.base_deploy: &base_deploy
stage: deploy
script:
- PROJECT_NAME="${CI_PROJECT_NAME}-${CI_ENVIRONMENT_SLUG}"
- helm --namespace ${CI_ENVIRONMENT_SLUG} upgrade -i ${PROJECT_NAME} helm --set "global.env=${CI_ENVIRONMENT_SLUG}";
stages:
- deploy
Deploy to Test:
<<: *base_deploy
environment:
name: test
Deploy to Production:
<<: *base_deploy
environment:
name: production
when: manual

Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.

