Тема, озвученная в заголовке статьи, не нова. На просторах Интернета можно найти множество вопросов, как ее реализовать, а вот ответов несколько меньше. И не редко они сводятся к советам использовать продукты сторонних разработчиков, например, Sphinx. Но зачастую в использовании таких громоздких надстроек нет необходимости.

User
Транслируем видеопоток с веб-страницы по WebRTC на Facebook и YouTube одновременно
6 min
Facebook и YouTube предоставляют сервисы трансляций, которые позволяют вещать Live-видеопотоки на широкую аудиторию зрителей. В этой статье мы расскажем, как захватить видеопоток с веб-страницы по технологии WebRTC и отправить этот видеопоток одновременно в Facebook и на YouTube для прямой трансляции — сразу в два сервиса.
Знакомство с СУБД CockroachDB и создание отказоустойчивого кластера с ней на Ubuntu 16.04
8 min
Tutorial
Translation
Предисловие от переводчика: CockroachDB — достаточно молодая реляционная СУБД с открытым кодом (лицензия Apache 2.0), изначально созданная быть распределённой (с горизонтальным масштабированием «из коробки») и отказоустойчивой. Её авторы из компании Cockroach Labs, созданной в 2015 году, задаются целью «совместить богатство функциональности SQL с горизонтальной доступностью, привычной для NoSQL-решений». Данное руководство написано одним из сотрудников компании-разработчика и опубликовано на сайте облачного провайдера DigitalOcean для того, чтобы познакомить ИТ-специалистов с этой СУБД и продемонстрировать её использование.

CockroachDB — распределённая СУБД (SQL) с открытым кодом, обеспечивающая согласованность данных, масштабируемость и выживаемость.
Настройка CockroachDB проста: устанавливаете её на нескольких серверах (узлах) и объединяете их в единое целое для совместной работы (кластер). Все узлы кластера действуют «симметрично» и предлагают доступ к одинаковым данным. Если хранилище для данных необходимо увеличить, то при используемой архитектуре достаточно создать новые узлы и присоединить к кластеру.
Введение
CockroachDB — распределённая СУБД (SQL) с открытым кодом, обеспечивающая согласованность данных, масштабируемость и выживаемость.
Настройка CockroachDB проста: устанавливаете её на нескольких серверах (узлах) и объединяете их в единое целое для совместной работы (кластер). Все узлы кластера действуют «симметрично» и предлагают доступ к одинаковым данным. Если хранилище для данных необходимо увеличить, то при используемой архитектуре достаточно создать новые узлы и присоединить к кластеру.
Философия информации, глава 4. Системы
26 min

Эта публикация — четвёртая часть сериала, начало которого здесь.
Краткое содержание предыдущих серий. Сначала мы разобрались с тем, что об информации нельзя говорить как о материи, что пусть материя будет материальной, а информация материальной быть не должна. Потом вниманию любопытной публики была представлена логическая конструкция, позволяющая говорить о существовании информации так, чтобы если её «зазаемление» на материю и происходило, то исключительно аккуратно и правильно. Для того, чтобы двинуться дальше, пришлось изобрести специальный инструмент обоснования существования предметов рассуждения, который был описан в 3-й главе. Теперь мы подошли к понятию «система». Кому интересно — милости прошу под кат.
Пользуемся escrow, чтобы не было мучительно больно.
2 min
В последнее время с завидной регулярностью вижу на хабре посты и комментарии фрилансеров и заказчиков, красочно описывающие то, как их кинули. Не будем говорить о том, что клиента и работника надо выбирать с умом, лучше всего из уже имеющихся пары сотен предложений; что надо получить степень доктора психологии, чтобы выявить «кидалу» на стадии переговоров; что надо присылать урезанные неработающие демо-версии с встроенными бэкдорами; что надо строго стоять на принципе «утром стулья, вечером деньги» — это уже не раз обсасывалось в постах и комментах. Поговорим лучше о том, что сделает вашу жизнь скучной, пресной и безвкусной, решив эту проблему на корню — об escrow сервисах.
Xiaomi Philips: умная лампа, которая бережет глаза
3 min
Если бы Xiaomi не участвовала в коллаборациях с другими брендами, позволяя так или иначе использовать свой логотип, то многих бы устройств мы не увидели. Например, если бы Mi не инвестировала в Ihealth, то не было бы умных тонометров Xiaomi. А если бы не партнерство с Philips, то не видать нам умной настольной лампы.

Наш опыт знакомства с Docker
34 min
Вместо предисловия

Сегодня приснился сон, как-будто меня ужали до размера нескольких
килобайт, засунули в какой-то сокет и запустили в контейнере.
Выделили транспорт в оверлейной сети и пустили
тестировать сервисы в других контейнерах…
Пока не сделали docker rm
Не так давно мне посчастливилось стать членом очень крутой команды
Centos-admin.ru, в которой я познакомился с такими же, как я: единомышленниками со страстью к новым технологиям, энтузиастами и просто отличными парнями. И вот, уже на второй рабочий день меня с коллегой посадили работать над одним проектом, в котором требовалось «докерировать всё, что можно докеризировать» и было критически важно обеспечить высокую доступность сервисов.
Скажу сразу, что до этого я был обычным комнатным Linux-админом: мерился аптаймами, апт-гет-инсталлил пакеты, правил конфиги, перезапускал сервисы, тайлил логи. В общем, не имел особо выдающихся практических навыков, совершенно ничего не знал о концепции The Pets vs. Cattle, практически не был знаком с Docker и вообще очень слабо представлял, какие широкие возможности он скрывает. А из инструментов автоматизации использовал лишь ansible для настройки серверов и различные bash-скрипты.
Устранение беспорядка маршрутизации сервисов при помощи Docker
17 min
Translation

“Не трудности “ломают” вас, а то, как вы их переносите” — Lou Holtz
В соавторстве с Emmet O’Grady (основателем NimbleCI и Docker Ninja)
В книге Франца Кафки “Превращение” (“Метаморфозы”) человек просыпается однажды утром и обнаруживает, что он превратился в гигантское насекомоподобное существо. Как у инженеров DevOps, у нас есть такие же сюрреалистические моменты в жизни. Мы находим экзотические ошибки “под ковриком” (скрытые в самых труднодоступных местах) или бываем атакованы червями либо другими опасными сущностями. Если вы занимаетесь этим достаточно долго, у вас рано или поздно появится ужасная история, или даже две (поделитесь ими с нами!). В такой момент мы не можем сидеть и ждать, когда наступит кризис, мы должны действовать быстро. Торопясь исправить это как можно раньше, мы должны развернуть (deploy) новую сущность и выпустить новую версию нашего сервиса, устраняя проблему.
Кластер Docker Swarm за 30 секунд
5 min
Tutorial
Translation
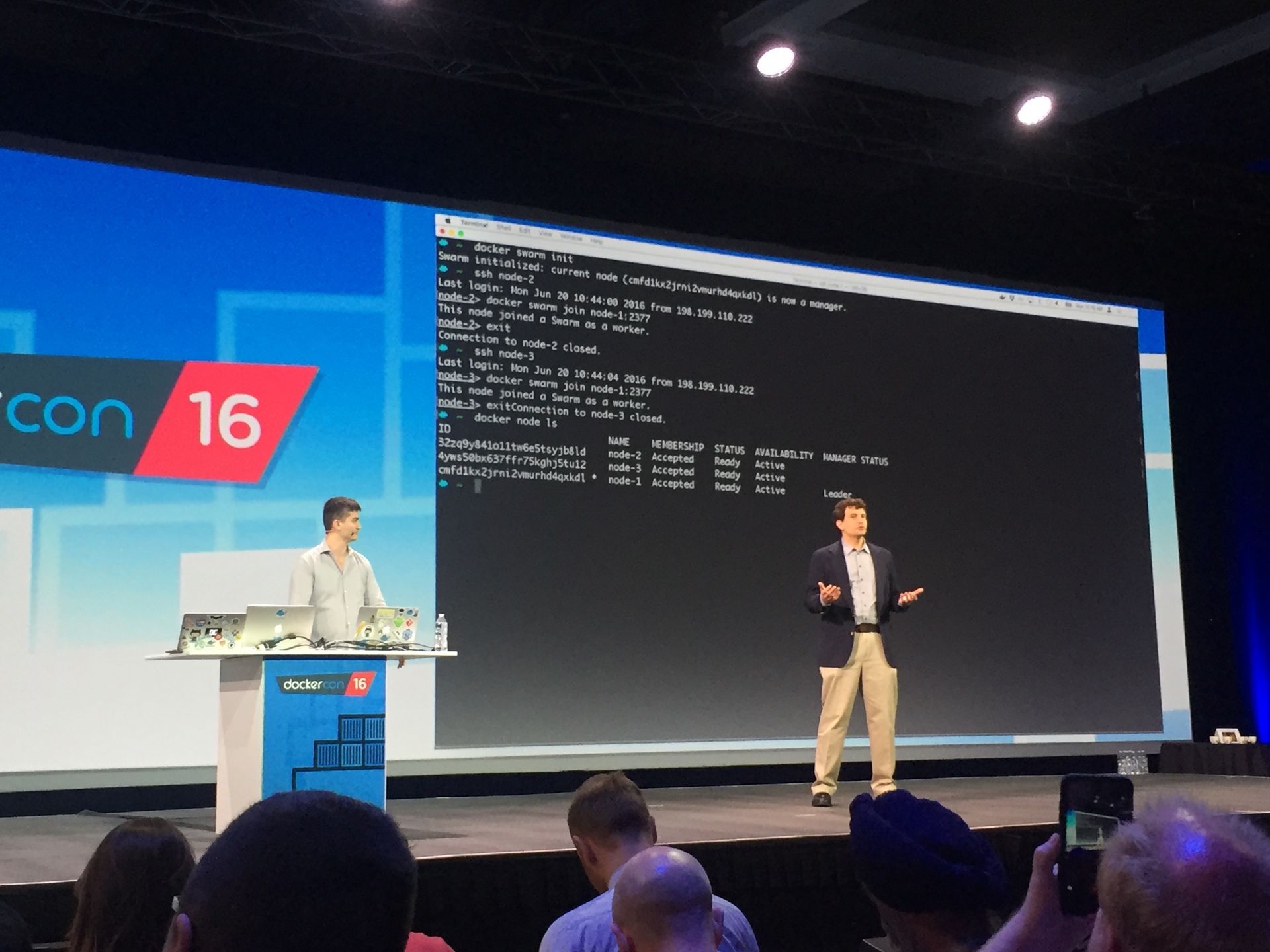
В этом июне, в качестве лейтмотива конференции DockerCon мы видели демо, в котором 3-узловой Swarm-кластер был создан за 30 секунд используя набор инструментов для кластеризации Swarm, интегрированную в Docker Engine 1.12.
Впечатляет, но естественно, мне нужно было попробовать сделать это самому, чтобы увидеть своими глазами.
Мониторинг Docker Swarm с помощью cAdvisor, InfluxDB и Grafana
11 min
Translation

Чтобы отслеживать состояние работающих приложений, необходимо проводить их постоянный мониторинг. А если приложения выполняются в таком хорошо масштабируемом окружении, как Docker Swarm, то потребуется также и хорошо масштабируемый инструмент мониторинга. В этой статье говорится о настройке именно такого инструмента.
В процессе работы мы установим агенты cAdvisor на каждой ноде для сбора метрик хоста и контейнеров. Метрики будут сохраняться в InfluxDB. Для построения графиков на основе этих метрик воспользуемся Grafana. Эти инструменты распространяются с открытым исходным кодом и могут быть развернуты в виде контейнеров.
Для построения кластера мы будем использовать Docker Swarm Mode и развернем необходимые сервисы в виде стека. Это позволит организовать динамическую систему мониторинга, которая способна автоматически начинать мониторинг новых нод по мере их добавления в рой (swarm). Файлы проекта можно найти здесь.
Шифрование в EXT4. How It Works?
12 min
 Паранойя не лечится! Но и не преследуется по закону. Поэтому в Linux Kernel 4.1 добавлена поддержка шифрования файловой системы ext4 на уровне отдельных файлов и директорий. Зашифровать можно только пустую директорию. Все файлы, которые будут созданы в такой директории, также будут зашифрованы. Шифруются только имена файлов и содержимое, метаданные не шифруются, inline data (когда данные файла, не превышающие по размеру 60 байт, хранятся в айноде) в файлах не поддерживается. Поскольку расшифровка содержимого файла выполняется непосредственно в памяти, шифрование доступно только в том случае, когда размер кластера совпадает с PAGE_SIZE, т.е. равен 4К.
Паранойя не лечится! Но и не преследуется по закону. Поэтому в Linux Kernel 4.1 добавлена поддержка шифрования файловой системы ext4 на уровне отдельных файлов и директорий. Зашифровать можно только пустую директорию. Все файлы, которые будут созданы в такой директории, также будут зашифрованы. Шифруются только имена файлов и содержимое, метаданные не шифруются, inline data (когда данные файла, не превышающие по размеру 60 байт, хранятся в айноде) в файлах не поддерживается. Поскольку расшифровка содержимого файла выполняется непосредственно в памяти, шифрование доступно только в том случае, когда размер кластера совпадает с PAGE_SIZE, т.е. равен 4К.Создана первая технология для подделки любых голосов
3 min

Говорят, ещё в советское время на телефонных станциях установили оборудование для прослушки разговоров. Естественно, записать и физически прослушать все разговоры тогда не было возможности, зато эффективно работала технология голосовой идентификации. По образцу голоса конкретного человека система мгновенно срабатывала — на прослушку или запись, с какого бы телефона он ни звонил. Эти технологии доступны и сегодня, вероятно, используются в оперативно-разыскной деятельности. Голос человека уникален, как его отпечатки пальцев.
Благодаря передовым разработкам в области ИИ теперь злоумышленники смогут пустить оперативников по ложному следу. 24 апреля 2017 года канадский стартап Lyrebird анонсировал первый в мире сервис, с помощью которого можно подделать голос любого человека. Для обучения системы достаточно минутного образца.
Восстание машин: Как роботы захватили бухгалтерию
5 min
Кнопочные войны в самом разгаре, роботы продолжают наступать, машины обучаются в разы быстрее людей, а вот Андрей, владелец одной московской кофейни, становится всё больше счастлив… В этот пятничный предпраздничный день мы решили поделиться с вами историей Кнопки, которая в прошлом году создала 42 робота для спасения бухгалтеров от рутинной работы, а сейчас занимается разитием искусственного бухгалтерского интеллекта.

Gixy — open source от Яндекса, который сделает конфигурирование Nginx безопасным
10 min
Nginx, однозначно, один из крутейших веб-серверов. Однако, будучи в меру простым, довольно расширяемым и производительным, он требует уважительного отношения к себе. Впрочем, это относится к почти любому ПО, от которого зависит безопасность и работоспособность сервиса. Признаюсь, нам нравится Nginx. В Яндексе он представлен огромным количеством инсталляций с разнообразной конфигурацией: от простых reverse proxy до полноценных приложений. Благодаря такому разнообразию у нас накопился некий опыт его [не]безопасного конфигурирования, которым мы хотим поделиться.
Но обо всем по порядку. Нас давно терзал вопрос безопасного конфигурирования Nginx, ведь он — полноправный кубик веб-приложения, а значит, и его конфигурация требует не меньшего контроля с нашей стороны, чем код самого приложения. В прошлом году нам стало очевидно, что этот процесс требует серьезной автоматизации. Так начался in-house проект Gixy, требования к которому мы обозначили следующим образом:
— быть простым;
— но расширяемым;
— с возможностью удобного встраивания в процессы тестирования;
— неплохо бы уметь резолвить инклюды;
— и работать с переменными;
— и про регулярные выражения не забыть.
Но обо всем по порядку. Нас давно терзал вопрос безопасного конфигурирования Nginx, ведь он — полноправный кубик веб-приложения, а значит, и его конфигурация требует не меньшего контроля с нашей стороны, чем код самого приложения. В прошлом году нам стало очевидно, что этот процесс требует серьезной автоматизации. Так начался in-house проект Gixy, требования к которому мы обозначили следующим образом:
— быть простым;
— но расширяемым;
— с возможностью удобного встраивания в процессы тестирования;
— неплохо бы уметь резолвить инклюды;
— и работать с переменными;
— и про регулярные выражения не забыть.
Создайте свой сервер AWS S3 с открытым кодом
4 min
Tutorial
Translation

Amazon S3 (Simple Storage Service, сервис простого хранилища) — очень мощный онлайн сервис файлового хранилища, предоставляемого Amazon Web Services. Думайте о нем, как об удаленном диске, на котором вы можете хранить файлы в директориях, получать и удалять их. Компании, такие как DropBox, Netflix, Pinterest, Slideshare, Tumblr и многие другие, полагаются на него.
Хоть сервис и отличный, его код не открыт, поэтому вы должны доверять Amazon свои данные, и хоть они предоставляют доступ к бесплатному инстансу на год, вы все равно должны ввести информацию о кредитной карте для создания аккаунта. Т.к. S3 должен знать каждый инженер-программист, я хочу, чтобы мои студенты приобрели опыт работы с ним и использовали его в своих веб-приложениях, и еще я не хочу, чтобы они за это платили. Некоторые студенты также работают во время поездок, что означает медленное Интернет-соединение и дорогой трафик, либо вообще полное отсутствие Интернета.
Философия информации, глава 3. Основания
24 min

Эта публикация — третья часть сериала, начало которого здесь. Если вы не ознакомились с началом истории, то вам, возможно, вообще не будет понятно, что этот текст здесь делает.
Ситуация, на самом деле, неоднозначная. С одной стороны, эта глава — абсолютно необходимый элемент конструкции философии информации, но с другой стороны, излагаемый материал не имеет прямого отношения к информационным технологиям. Если вы не уверены, что конкретно сейчас есть настроение погружаться в диковинную и вязкую тему философских обоснований, вполне можно пролистать дальше. Потом, при чтении следующих глав (когда они будут выложены), если вам вдруг станет интересно, что это за «ситуационно-зависимое обоснование», при помощи которого я творю ужасные вещи, к этой главе можно будет вернуться.
Универсальный грамматический анализатор естественных языков с нуля. Выпуск 1
13 min
Компиляторы, интерпретаторы… Сколько им посвещено книг и проектов! Баста, надоело! А вот сунешся в область анализа естественных языков, и никакой информации! А все что есть как-то очень сложно, непонятно и не универсально. Была у меня идея создать средневековую лингвистическую новеллу. Чтобы можно было разговаривать с персонажами на каком нибудь древнем естественном или вымышленном языке. На Латыни например? И на Квенья. И чтобы они понимали. А почему бы и нет?
Что дает «Генетика микробиоты»
6 min
«Атлас» сходил в творческий отпуск и вернулся в эфир с рассказом о новом тесте. «Генетика микробиоты» — анализ бактерий кишечника, который мы уже тестировали вместе с участниками краудфандинга в прошлом году.
После запуска мы серьезно доработали тест: переписали статьи, уточнили рекомендации по питанию и дополнили отчет. Результаты исследования микробиоты теперь интегрированы с генетическим тестом: пользователи «Атласа» получают сводный отчет о состоянии здоровья и рекомендации по питанию, которые учитывают данные двух тестов.
В марте тест «Генетика микробиоты» запустился в продажу. Это первый анализ микробиоты, который доступен в РФ обычным пользователям. Сегодня мы расскажем, что входит в обновленный тест, и чем он может быть полезен обычному человеку.
После запуска мы серьезно доработали тест: переписали статьи, уточнили рекомендации по питанию и дополнили отчет. Результаты исследования микробиоты теперь интегрированы с генетическим тестом: пользователи «Атласа» получают сводный отчет о состоянии здоровья и рекомендации по питанию, которые учитывают данные двух тестов.
В марте тест «Генетика микробиоты» запустился в продажу. Это первый анализ микробиоты, который доступен в РФ обычным пользователям. Сегодня мы расскажем, что входит в обновленный тест, и чем он может быть полезен обычному человеку.
Делаем Искусственный Интеллект
11 min
Пролог
Прошло уже около четырех месяцев с тех пор, как я серьезно увлекся проблемой Искусственного Интеллекта. Сначала желание не было таким явным — я просто хотел написать небольшую программку с естественно-языковым взаимодействием в качестве тренировки. Но чем больше я думал об этой цели, тем больше она усложнялась и, в конце концов, изменилась до неузнаваемости, стала похожей уже скорее на Искусственный Интеллект, чем на то, что было вначале. Покопавшись в сети, я не нашел ничего путного на эту тему и решил продолжить развивать свою первоначальную идею.На данный момент результатом многочисленных применений анализа и синтеза является некоторое количество информации в виде концепций, частичных моделей архитектуры, идей реализации и прогнозов. Вот и захотелось поделиться с общественностью.
Искусственный интеллект и Web: Часть 0
13 min
Привет Хабр.
Почитав то, что на хабре пишут по нейронным сетям захотелось более простым и интересным языком рассказать о искусственном интеллекте. Идея такова, во-первых написать цикл статей об основах нейронных сетей, ну а во-вторых есть несколько идей для интересных проектов, совмещающих интерактивность присущую всему вебдванольному и обучаемость нейросетей, но это позже.