
Школа менеджеров Стратоплан представляет:
Константин Дубровин, бизнес-тренер, работа с людьми и руководством, создание отделов продаж.
«Как продать идею»
Если вы хотите, чтобы кто-то сделал то, что придумали вы, значит вы хотите продать идею. Есть несколько вариантов. Например доплатить. Еще легко продавать идеи, у которых нет альтернативы. И гораздо реже нам удается действительно увлечь человека.
Вот было бы хорошо, если бы наши сотрудники были увлечены поставленной задачей, а наше руководство горело бы идеей, которую придумали мы. Вот бы наши близкие принимали бы наш вариант отдыха, шопинга или ремонта. И никакого торга, мол в прошлый раз мы сделали по-твоему, а в этот…
Константин Дубровин, бизнес-тренер, работа с людьми и руководством, создание отделов продаж.
Недавно ко мне пришли коллеги из Школы менеджеров «Стратоплан» и предложили выступить в роли спикера на онлайн-конференции PRO+People, где нужно будет говорить о работе с людьми: именно этой теме и посвящена вся Конференция. Вместе с другими спикерами (Александром Орловым, Вячеславом Панкратовым, Дмитрием Коткиным и Иваном Селиховкиным) мы будем рассказывать о сложностях и проблемах, которые часто встречаются в компаниях, коллективах и просто в жизни.
Когда я выбирал тему для своего выступления, первое, что мне пришло в голову — это…
Продажи! Уверен, я своим выбором никого сейчас не удивил. Но тему продаж я выбрал не зря. Есть одна вещь, которую порой сложнее всего продать. Это идея.
Мы каждый день убеждаем самых разных людей в своей точке зрения. Хочется сделать так, чтобы щелкнул тумблером, и человек сразу стал с тобой согласен. Но почему-то не всегда так получается.
Вот даже написалось «пару слов» о том, почему это происходит и что с этим делать…
«Как продать идею»
Если вы хотите, чтобы кто-то сделал то, что придумали вы, значит вы хотите продать идею. Есть несколько вариантов. Например доплатить. Еще легко продавать идеи, у которых нет альтернативы. И гораздо реже нам удается действительно увлечь человека.
Вот было бы хорошо, если бы наши сотрудники были увлечены поставленной задачей, а наше руководство горело бы идеей, которую придумали мы. Вот бы наши близкие принимали бы наш вариант отдыха, шопинга или ремонта. И никакого торга, мол в прошлый раз мы сделали по-твоему, а в этот…




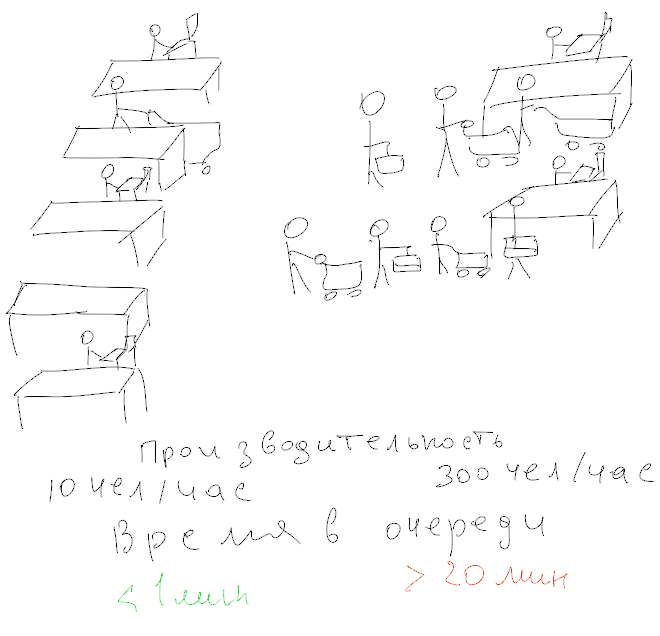
 IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
