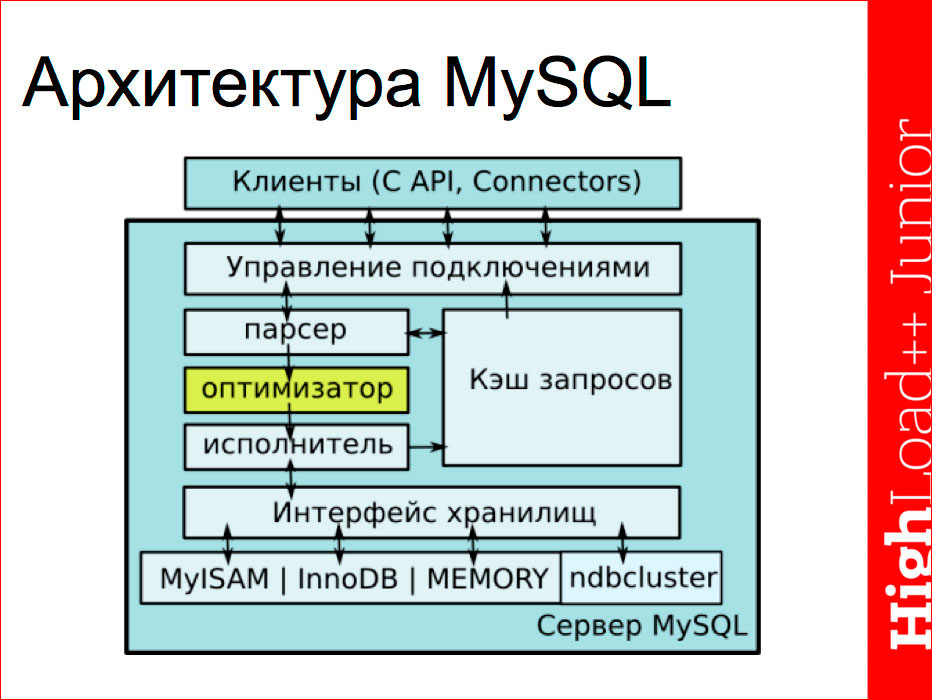
Ваш компьютер не является быстрой версией PDP-11
Привет, Хабр!
Меня зовут Антон Довгаль, я С (и не только) разработчик в Badoo.
Мне попалась на глаза статья Дэвида Чизнэлла, исследователя Кембриджского университета, в которой он оспаривает общепринятое суждение о том, что С — язык низкого уровня, и его аргументы мне показались достаточно интересными.
В свете недавно обнаруженных уязвимостей Meltdown и Spectre стоит потратить время на выяснение причин их появления. Обе эти уязвимости эксплуатировали спекулятивное выполнение инструкций процессорами и позволяли атакующему получать результаты по сторонним каналам. Вызвавшие уязвимости особенности процессоров наряду с некоторыми другими были добавлены для того, чтобы программисты на C продолжали верить, что они программируют на языке низкого уровня, хотя это не так уже десятки лет.
Производители процессоров не одиноки в этом. Разработчики компиляторов C/C++ тоже внесли свою лепту.




 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.
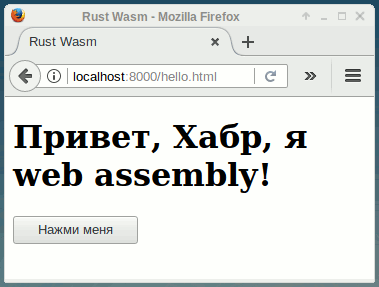 Недавно вышла новость про то, что webassembly теперь включен в firefox 52 из коробки. А потом еще и chrome 57 подтянулся (правда, там вроде бы были какие-то баги с запуском). Я решил, что обязательно надо попробовать.
Недавно вышла новость про то, что webassembly теперь включен в firefox 52 из коробки. А потом еще и chrome 57 подтянулся (правда, там вроде бы были какие-то баги с запуском). Я решил, что обязательно надо попробовать.