
В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ "
DRAM Errors in the Wild: A Large-Scale Field Study" посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.
Отмечу также, что та же группа исследователей, во главе с аспирантом, а ныне профессором Университета Торонто,
Бианкой Шрёдер (Bianca Shroeder) ранее, в 2007 году публиковала не менее интересное исследование, посвященное статистике отказов жестких дисков в датацентрах Google (краткую популярную выжимку из работы
Failure Trends in a Large Disk Drive Population (pdf 242 KB), если вам скучно читать весь отчет, можно найти здесь:
http://blog.aboutnetapp.ru/archives/tag/google). Кроме того, их перу принадлежит еще несколько работ, в частности об влиянии температуры и охлаждении, и о статистике отказов в оперативной памяти, вызываемой, предположительно, космическими лучами высоких энергий. Ссылки на публикации можно найти на домашней странице Шрёдер, на сервере университета.




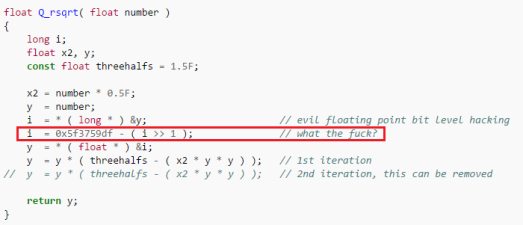





 «Всякая строка кода рождается без причины, продолжается в слабости и удаляется случайно», —
«Всякая строка кода рождается без причины, продолжается в слабости и удаляется случайно», — 


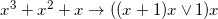 , которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.
, которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.